|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
情報学および情報技術。 チートシート:簡単に言えば、最も重要な
目次
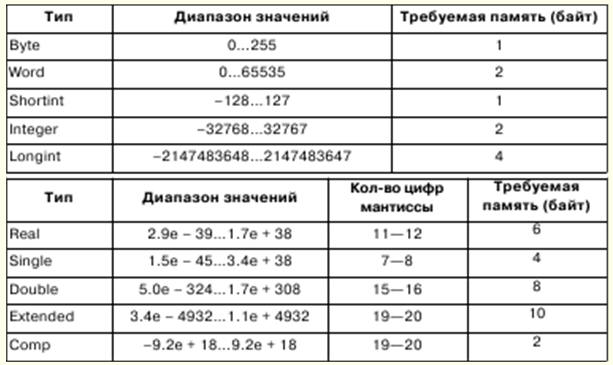
1. コンピューター サイエンス。 情報 表現と処理/情報。 番号システム 情報学は、科学、技術、生産のさまざまな分野で、オブジェクトとそれらの関係の構造の形式化された表現に従事しています。 論理式、データ構造、プログラミング言語など、さまざまな正式なツールを使用してオブジェクトや現象をモデル化します。 コンピューター サイエンスでは、情報などの基本的な概念にはさまざまな意味があります。 1)外部形式の情報の正式な提示。 2)情報の抽象的な意味、その内部コンテンツ、セマンティクス。 3)情報と実世界との関係。 しかし、原則として、情報はその抽象的な意味、つまりセマンティクスとして理解されます。 情報を交換したいのであれば、解釈の正しさが損なわれないように一貫した見方が必要です。 これを行うために、情報の表現の解釈は、いくつかの数学的構造で識別されます。 この場合、情報処理は厳密な数学的方法で実行できます。 情報の数学的記述のXNUMXつは、関数としての表現です。 y = f(x,t) ここで、tは時間です。 xは、yの値が測定されるフィールド内のポイントです。 機能パラメータxおよびtに応じて、情報を分類できます。 パラメータが連続した一連の値をとるスカラー量である場合、この方法で得られた情報は連続 (またはアナログ) と呼ばれます。 パラメータに特定の変化ステップが与えられている場合、その情報は離散的と呼ばれます。 離散情報は普遍的と見なされます。 離散情報は通常、デジタル情報で識別されます。これは、アルファベット表現の記号情報の特殊なケースです。 アルファベットは、あらゆる性質の記号の有限集合です。 コンピュータ サイエンスでは、あるアルファベットの文字を別の文字で表現しなければならない、つまりエンコード操作を実行しなければならないという状況が頻繁に発生します。 実践が示しているように、他のアルファベットをエンコードできる最も単純なアルファベットはバイナリであり、通常は 0 と 1 で示される 2 文字で構成されます。バイナリ アルファベットの n 文字を使用すると、XNUMXn 文字をエンコードでき、これで十分です。任意のアルファベットをエンコードします。 8進数のアルファベットの記号で表現できる値を情報の最小単位またはビットと呼びます。 256 ビットのシーケンス - バイト。 8 の異なる XNUMX ビット シーケンスを含むアルファベットは、バイト アルファベットと呼ばれます。 記数法は、番号の命名と書き込みに関する一連の規則です。 位置番号システムと非位置番号システムがあります。 数の桁の値が数の桁の位置に依存する場合、数システムは定位置と呼ばれます。 それ以外の場合は、非定位置と呼ばれます。 数値の値は、数値内のこれらの桁の位置によって決まります。 2.コンピューターでの数字の表現。 アルゴリズムの形式化された概念 32ビットプロセッサは最大232-1RAMで動作し、アドレスは00000000〜FFFFFFFFの範囲で書き込むことができます。 ただし、リアルモードでは、プロセッサは最大220-1のメモリで動作し、アドレスは00000〜FFFFFの範囲になります。 メモリのバイトは、固定長と可変長の両方のフィールドに組み合わせることができます。 ワードは2バイトで構成される固定長フィールドであり、ダブルワードは4バイトのフィールドです。 フィールドアドレスは偶数でも奇数でもかまいませんが、偶数アドレスの方が高速です。 固定小数点数は、コンピューターでは整数の1進数として表され、サイズは2、4、またはXNUMXバイトです。 整数のXNUMX進数は、XNUMXの補数で表されます。 正の数の追加コードはその数自体と同じであり、負の数の追加コードは次の式を使用して取得できます。 x = 10n - \x\、n は数値のビット深度です。 XNUMX 進数システムでは、追加のコードは、ビットを反転することによって得られます。 仮数のビット数は数値の表現の精度を決定し、マシンオーダービットの数は浮動小数点数の表現の範囲を決定します。 アルゴリズムの形式化された概念 アルゴリズムは、同時に何らかの数学的対象が存在する場合にのみ存在できます。 アルゴリズムの形式化された概念は、再帰関数、通常のマルコフアルゴリズム、チューリングマシンの概念に関連しています。 数学では、引数の任意のセットに対して、関数の一意の値が決定される法則がある場合、関数は単一値と呼ばれます。 アルゴリズムはそのような法則として機能します。 この場合、関数は計算可能であると言われます。 再帰関数は計算可能関数のサブクラスであり、計算を定義するアルゴリズムはコンピュテーション再帰関数アルゴリズムと呼ばれます。 まず、基本的な再帰関数が固定されており、付随するアルゴリズムは自明で明確です。 次に、置換、再帰、最小化のXNUMXつのルールが導入され、基本関数に基づいてより複雑な再帰関数が取得されます。 基本的な機能とそれに付随するアルゴリズムは次のとおりです。 1) n 個の独立変数の関数で、ゼロに等しくなります。 次に、関数の符号が φn の場合、引数の数に関係なく、関数の値はゼロに設定する必要があります。 2) Ψ ni 形式の n 個の独立変数の恒等関数。 次に、関数の符号が Ψ ni の場合、関数の値は、左から右に数えて i 番目の引数の値と見なされます。 3) XNUMX つの独立引数の λ 関数。 次に、関数の符号が λ の場合、関数の値は、引数の値に続く値と見なされます。 3. Pascal 言語の紹介 言語の基本記号 - 文字、数字、特殊文字 - がアルファベットを構成しています。 Pascal 言語には、次の基本的な記号のセットが含まれています。 1)26個のラテン語の小文字と26個のラテン語の大文字: 2)_(アンダースコア); 3)10桁:0 1 2 3 4 5 6 7 8 9; 4) 操作の兆候: + - O / = <> < > <= >= := @; 5) 区切り文字:.、( ) [ ] (..) { } (* *).. :; 6) 指定子: ^ # $; 7)サービス(予約)ワード:ABSOLUTE、ASSEMBLER、AND、ARRAY、ASM、BEGIN、CASE、CONST、CONSTRUCTOR、DESTRUCTOR、DIV、DO、DOWNTO、ELSE、END、EXPORT、EXTERNAL、FAR、FILE、FOR、FORWARD、 FUNCTION、GOTO、IF、IMPLEMENTATION、IN、INDEX、INHERITED、INLINE、INTERFACE、INTERRUPT、LABEL、LIBRARY、MOD、NAME、NIL、NEAR、NOT、OBJECT、OF、OR、PACKED、PRIVATE、PROCEDURE、 プログラム、パブリック、レコード、リピート、レジデント、セット、 SHL、SHR、STRING、THEN、TO、TYPE、UNIT、UNTIL、USES、 VAR、VIRTUAL、WILE、WITH、XOR。 リストされているものに加えて、基本文字のセットにはスペースが含まれています。 Pascal には規則があります。型は、変数または関数を使用する前に宣言するときに明示的に指定されます。 Pascal 型の概念には、次の主要なプロパティがあります。 1)任意のデータ型は、定数が属する値のセット、変数または式が取ることができる値、または操作または関数が生成できる値のセットを定義します。 2) 定数、変数、または式によって与えられる値の型は、それらの形式または記述によって決定できます。 3)各操作または関数は固定型の引数を必要とし、固定型の結果を生成します。 Pascalにはスカラーデータ型と構造化データ型があります。 スカラータイプには、標準タイプとユーザー定義タイプが含まれます。 標準タイプには、整数、実数、文字、ブール、およびアドレスタイプが含まれます。 整数型は、特定のコンピューターで許可されている整数のセットによって値が実現される定数、変数、および関数を定義します。 Pascal の演算子の優先順位は次のとおりです。
1) 括弧内の計算; 2)関数値の計算。 3) 単項演算。 4) 操作 * / div mod および; 5) 操作 + - または xor; 6) 関係演算 = <> < > <= >=. 4.標準的な手順と機能 算術関数 1.Function Abs(X); パラメータの絶対値を返します。 2. 関数 ArcTan (X: 拡張): 拡張; 引数の逆正接を返します。 3. 関数 Exp(X: 実数): 実数; 指数を返します。 4.Frac(X: 実数): 実数; 引数の小数部分を返します。 5. 関数 Int(X: 実数): 実数; 引数の整数部分を返します。 6. 関数 Ln(X: 実数): 実数。実数型の式 x の自然対数 (Ln e = 1) を返します。 7.機能Pi:拡張; 3.1415926535として定義されている値Piを返します。 8.Function Sin(X: 拡張): 拡張; 引数のサインを返します。 9. 関数 Sqr (X: 拡張): 拡張; 引数の二乗を返します。 10.Function Sqrt(X: 拡張): 拡張; 引数の平方根を返します。 値変換の手順と機能 1.プロシージャStr(X [:幅[:小数]]; var S); 数値Xを文字列表現に変換します。 2. 関数 Chr(X: バイト): Char; ASCII テーブル内のインデックス番号 x の文字を返します。 3.Function High(X); パラメータの範囲内の最大値を返します。 4.FunctionLow(X); パラメータの範囲内の最小値を返します。 5.関数 Ord(X): LongInt; 列挙型式の序数値を返します。 6. 関数 Round(X: 拡張): LongInt; 実数値を整数に丸めます。 7. 関数 Trunc(X: 拡張): LongInt; 実数型の値を切り捨てて整数にします。 8.プロシージャVal(S; var V; var Code:Integer); 数値を文字列値Sから数値表現Vに変換します。 順序値の手順と関数 1.手順 Dec(var X [; N: LongInt]); 変数 X から XNUMX または N を減算します。 2.手続き Inc(var X [; N: LongInt]); 変数 X に XNUMX または N を追加します。 3. Function Odd(X: LongInt): Boolean; X が奇数の場合は True、そうでない場合は False を返します。 4.FunctionPred(X); パラメータの以前の値を返します。 5 関数 Succ(X); 次のパラメータ値を返します。 5. Pascal 言語の演算子 条件演算子 完全な条件ステートメントの形式は、次のように定義されます。 B なら S1 でなければ S2 ここで、B は分岐 (意思決定) 条件、論理式、または関係です。 S1、S2 - XNUMX つの実行可能なステートメント、単純または複合。 条件付きステートメントを実行する場合、最初に式 B が評価され、次にその結果が分析されます。B が true の場合、ステートメント S1 が実行されます (then の分岐)。ステートメント S2 はスキップされます。 B が false の場合、ステートメント S2 - else 分岐が実行され、ステートメント S1 はスキップされます。 選択演算子 演算子の構造は次のとおりです。 ケースSの c1: 命令 1; c2: 命令 2; ... cn: 命令N; その他の命令 終わり ここで、S は、値が計算される序数型の式です。 c1、c2、...、on - 式 S が比較される順序型の定数。命令 XNUMX、...、命令 N - 定数が式 S の値と一致する演算子が実行されます。 命令-式Sの値が定数c1、o2、onのいずれにも一致しない場合に実行される演算子。 パラメータ付きのループステートメント for ステートメントの実行が開始されると、開始値と終了値が一度決定され、これらの値は for ステートメントの実行中ずっと保持されます。 for ステートメントの本体に含まれるステートメントは、開始値と終了値の間の範囲内の値ごとに XNUMX 回実行されます。 ループカウンタは常に初期値に初期化されます。 前提条件付きループ文 BがSを行う間; ここで、B は論理条件であり、その真偽がチェックされます (ループを終了するための条件です)$; S - ループ本体 - XNUMX つのステートメント。 ステートメントの繰り返しを制御する式は、ブール型でなければなりません。 内部ステートメントが実行される前に評価されます。 内部ステートメントは、式が Trie に評価される限り繰り返し実行されます。 式が最初から False と評価された場合、前提条件ループ ステートメント内に含まれるステートメントは実行されません。 事後条件付きのループステートメント B まで S を繰り返します。 ここで、Bは論理条件であり、その真偽がチェックされます(ループを終了するための条件です)。 S-XNUMXつ以上のループ本体ステートメント。 式の結果はブール型である必要があります。 繰り返しキーワードとuntilキーワードで囲まれたステートメントは、式の結果がTrueと評価されるまで順番に実行されます。 式はステートメントシーケンスの実行ごとに評価されるため、ステートメントシーケンスは少なくともXNUMX回実行されます。 6. 補助アルゴリズムの概念 問題を解決するためのアルゴリズムは、問題全体を個別のサブタスクに分解することによって設計されます。 通常、サブタスクはサブルーチンとして実装されます。 サブルーチンは、パラメーターと呼ばれるいくつかの入力量のさまざまな値を使用して、メイン アルゴリズムで繰り返し使用される補助アルゴリズムです。 プログラミング言語のサブルーチンは、プログラム内のXNUMXつの場所でのみ定義および記述される一連のステートメントですが、プログラム内のXNUMXつ以上のポイントから実行するために呼び出すことができます。 各サブルーチンは一意の名前で識別されます。 Pascalには、プロシージャと関数のXNUMX種類のサブルーチンがあります。 プロシージャと関数は、宣言とステートメントの名前付きシーケンスです。 プロシージャまたは関数を使用する場合、プログラムには、プロシージャまたは関数のテキストと、プロシージャまたは関数の呼び出しが含まれている必要があります。 説明で指定されたパラメーターは形式的と呼ばれ、サブルーチンの呼び出しで指定されたパラメーターは実際と呼ばれます。 すべての正式なパラメータは、次のカテゴリに分類できます。 1)パラメータ-変数; 2) 定数パラメータ。 3) パラメータ値。 4) 手続きパラメータと関数パラメータ、つまり手続き型パラメータ。 5) 型指定されていない変数パラメーター。 手順と関数のテキストは、手順と関数の説明に配置されています。 プロシージャ名と関数名をパラメータとして渡す 多くの問題、特に計算数学では、手続きと関数の名前をパラメータとして渡す必要があります。 これを行うために、TURBO PASCAL は、記述内容に応じて手続き型または関数型の新しいデータ型を導入しました。 (手続き型と関数型は、型宣言のセクションで説明されています。) 関数と手続き型は、手続きの見出しと、正式なパラメーターのリストはあるが名前がない関数として定義されます。 パラメータなしで関数または手続き型を定義することができます。次に例を示します。 type Proc=プロシージャ; 手続き型または関数型を宣言した後、それを使用して、正式なパラメーター(手続きおよび関数の名前)を記述することができます。 さらに、名前が実際のパラメーターとして渡される実際のプロシージャーまたは関数を作成する必要があります。 7. Pascal での手続きと機能 パスカルでの手順 プロシージャの説明は、ヘッダーとブロックで構成されます。これらは、モジュール接続セクションを除いて、プログラムブロックと同じです。 ヘッダーは、Procedureキーワード、プロシージャーの名前、および括弧内の仮パラメーターのオプションのリストで構成されます。 プロシージャ<名前>[(<正式なパラメータのリスト>)]; 仮パラメータごとに、その型を定義する必要があります。 プロシージャの説明のパラメータグループは、セミコロンで区切られています。 プロシージャの構造は、プログラムとほぼ完全に似ています。 ただし、プロシージャブロックにはモジュール接続セクションがありません。 このブロックは、記述部分と実行部分の XNUMX つの部分で構成されています。 説明部分には、プロシージャの要素の説明が含まれます。 また、実行部分では、必要な結果を得ることができる手順で使用可能なプログラム要素 (グローバル変数や定数など) を使用してアクションが示されます。 プロシージャの命令セクションがプログラムの命令セクションと異なるのは、セクションを終了する End キーワードの後にピリオドではなくセミコロンが続く点だけです。 プロシージャーを呼び出すには、プロシージャー呼び出しステートメントを使用します。 これは、プロシージャの名前と、括弧で囲まれた引数のリストで構成されます。 プロシージャーの実行時に実行されるステートメントは、プロシージャー・モジュールのステートメント部分に含まれています。 プロシージャーがそれ自体を呼び出したい場合があります。 この呼び出し方を再帰と呼びます。 再帰は、メイン タスクをサブタスクに分割できる場合に役立ちます。各サブタスクは、メイン タスクと一致するアルゴリズムに従って実装されます。 パスカルの関数 関数宣言は、値が計算されて返されるプログラムの部分を定義します。 関数記述は、ヘッダーとブロックで構成されます。 ヘッダーには、Function キーワード、関数の名前、括弧で囲まれたオプションの仮パラメーターのリスト、および関数の戻り値の型が含まれます。 関数ヘッダーの一般的な形式は次のとおりです。 関数<名前>[(<仮パラメーターのリスト>)]:<戻り値>; Turbo Pascal 7.0のBorland実装では、関数の戻り値を複合型にすることはできません。 また、BorlandDelphi統合開発環境で使用されているObjectPascal言語では、ファイルタイプを除いて、あらゆるタイプの結果を返すことができます。 ファンクション ブロックは、プロシージャ ブロックと構造が似ているローカル ブロックです。 関数の本体には、少なくとも XNUMX つの割り当てステートメントが含まれている必要があり、その左側に関数の名前があります。 関数によって返される値を決定するのは彼女です。 そのような命令が複数ある場合、関数の結果は最後に実行された代入命令の値になります。 関数が呼び出されると、関数がアクティブになります。 関数が呼び出されると、関数識別子と関数の評価に必要なパラメーターが指定されます。 関数呼び出しは、オペランドとして式に含めることができます。 式が評価されると、関数が実行され、オペランドの値が関数によって返される値になります。 関数ブロックの演算子部分は、関数がアクティブ化されたときに実行する必要があるステートメントを指定します。 モジュールには、関数識別子に値を割り当てる割り当てステートメントが少なくとも XNUMX つ含まれている必要があります。 関数の結果は、最後に割り当てられた値です。 そのような代入ステートメントがない場合、または実行されていない場合、関数の戻り値は未定義です。 モジュール内の関数 (関数) を呼び出すときに関数識別子が使用される場合、その関数は再帰的に実行されます。 8.サブルーチンの説明と接続を転送します。 指令 プログラムには複数のサブルーチンが含まれる場合があります。つまり、プログラムの構造が複雑になる場合があります。 ただし、これらのサブルーチンは同じネストレベルにすることができるため、特別な前方宣言が使用されていない限り、サブルーチン宣言を最初に実行してから、サブルーチン宣言を呼び出す必要があります。 ステートメントブロックの代わりに前方ディレクティブを含むプロシージャ宣言は、前方宣言と呼ばれます。 この宣言の後のある時点で、定義宣言を使用してプロシージャを定義する必要があります。 定義宣言は、同じプロシージャーIDを使用しますが、仮パラメーターのリストを省略し、ステートメント・ブロックを含む宣言です。 前方宣言と定義宣言は、プロシージャ宣言と関数宣言の同じ部分に含まれている必要があります。 それらの間で、前方宣言プロシージャを参照できる他のプロシージャと関数を宣言できます。 したがって、相互再帰が可能です。 前方記述と定義記述は、手順の完全な記述です。 手順は、前方記述を使用して記述されていると見なされます。 プログラムに非常に多くのサブルーチンが含まれている場合、プログラムは視覚的ではなくなり、ナビゲートするのが難しくなります。 これを回避するために、一部のルーチンはソース ファイルとしてディスクに保存され、必要に応じて、コンパイル ディレクティブを使用してコンパイル段階でメイン プログラムに接続されます。 ディレクティブは、プログラム内のどこにでも配置できる特別なコメントであり、通常のコメントを配置できます。 ただし、ディレクティブには特別な表記があるという点で異なります。スペースなしの閉じ括弧の直後に$記号が書き込まれ、スペースなしでディレクティブが示されます。 例: 1) {$E+} - 数学コプロセッサをエミュレートします。 2){$F+}-遠いタイプの呼び出しプロシージャと関数を形成します。 3){$N+}-数学コプロセッサーを使用します。 4) {$R+} - 範囲が範囲外かどうかを確認します。 一部のコンパイル スイッチには、次のようなパラメーターが含まれる場合があります。 {$I file name} - 指定されたファイルをコンパイル済みプログラムのテキストに含めます 9. サブプログラムのパラメータ プロシージャまたは関数の説明は、正式なパラメータのリストを指定します。 正式なパラメータリストで宣言された各パラメータは、記述されているプロシージャまたは関数に対してローカルであり、そのプロシージャまたは関数に関連付けられたモジュールでその識別子によって参照できます。 パラメータには、値、変数、型なし変数のXNUMX種類があります。 それらは次のように特徴付けられます。 1. 前にキーワードがないパラメーターのグループは、値パラメーターのリストです。 2. const キーワードが前にあり、型が後に続くパラメーターのグループは、定数パラメーターのリストです。 3. var キーワードが前にあり、タイプが後に続くパラメーターのグループは、変数パラメーターのリストです。 値パラメーター 仮値パラメーターは、プロシージャーまたは関数が呼び出されたときに対応する実パラメーターから初期値を取得することを除いて、プロシージャーまたは関数に対してローカルな変数のように扱われます。 仮の値パラメーターが受ける変更は、実際のパラメーターの値には影響しません。 value パラメーターの対応する実際の値は式である必要があり、その値はファイルの種類またはファイルの種類を含む構造体の型であってはなりません。 実際のパラメーターは、仮値パラメーターのタイプと割り当て互換性のあるタイプである必要があります。 パラメータが文字列型の場合、仮パラメータのサイズ属性は255になります。 定数パラメータ サブルーチンの本体では、定数パラメーターの値は変更できません。 パラメータ定数を使用して、サブルーチンでの変更が望ましくなく、禁止する必要があるパラメータを調整できます。 可変パラメータ 変数パラメーターは、サブルーチンから呼び出しブロックに値を渡す必要がある場合に使用されます。 この場合、サブルーチンが呼び出されると、仮パラメーターが可変引数に置き換えられ、仮パラメーターへの変更が引数に反映されます。 手続き変数 手続き型を定義すると、この型の変数を記述できるようになります。 このような変数は手続き型変数と呼ばれます。 整数型の値を割り当てることができる整数変数と同様に、手続き型変数には手続き型の値を割り当てることができます。 もちろん、そのような値は別のプロシージャ変数である可能性がありますが、プロシージャまたは関数の識別子である可能性もあります。 このコンテキストでは、プロシージャまたは関数の宣言は、値がプロシージャまたは関数である特別な種類の定数の記述と見なすことができます。 他の割り当てと同様に、左側と右側の変数の値は割り当て互換でなければなりません。 代入の互換性を保つ手続き型には、同じ数のパラメーターが必要であり、対応する位置のパラメーターは同じ型でなければなりません。 手続き型宣言のパラメーター名は効果がありません。 さらに、割り当ての互換性を確保するために、プロシージャまたは関数をプロシージャ変数に割り当てる場合は、標準またはネストしてはなりません。 10. サブルーチンのパラメータの種類 値パラメーター 仮値パラメータはローカル変数として扱われ、プロシージャまたは関数が呼び出されると、対応する実パラメータから初期値が取得されます。 仮の値パラメーターが受ける変更は、実際のパラメーターの値には影響しません。 value パラメータの対応する実際の値は式である必要があり、その値はファイル タイプであってはなりません。 定数パラメータ 仮定数パラメータは、プロシージャまたは関数が呼び出されたときに値を取得します。 仮定数パラメーターへの代入は許可されていません。 仮定数パラメーターは、実パラメーターとして別のプロシージャーまたは関数に渡すことはできません。 可変パラメータ 変数パラメーターは、プロシージャーまたは関数から呼び出しプログラムに値を渡す必要がある場合に使用されます。 有効にすると、仮パラメーター変数が実変数に置き換えられ、仮パラメーター変数への変更が実パラメーターに反映されます。 型なしパラメータ 仮パラメーターが型指定されていない変数パラメーターである場合、対応する実パラメーターは変数または定数参照にすることができます。 varキーワードで宣言された型なしパラメーターは変更できますが、constキーワードで宣言された型なしパラメーターは読み取り専用です。 手続き変数 手続き型を定義すると、この型の変数を記述できるようになります。 このような変数は手続き型変数と呼ばれます。 手続き変数には、手続き型の値を割り当てることができます。 割り当て時のプロシージャまたは関数は、次のようにする必要があります。 1) 標準ではありません。 2)ネストされていません。 3) インライン型の手続きではありません。 4)割り込み手順によるものではありません。 手続き型パラメーター 手続き型はあらゆる文脈で使用できるため、手続きや関数をパラメータとして取る手続きや関数を記述することができます。 手続き型パラメーターは、複数の手続きまたは関数に対して共通のアクションを実行する必要がある場合に特に役立ちます。 プロシージャまたは関数をパラメーターとして渡す場合は、代入と同じ型の互換性規則に従う必要があります。 つまり、そのようなプロシージャまたは関数は far ディレクティブを使用してコンパイルする必要があり、組み込み関数にすることはできず、入れ子にすることも、インラインまたは割り込み属性で記述することもできません。 11.Pascalの文字列型。 文字列型変数のプロシージャと関数 一定の長さの文字列を文字列と呼びます。 文字列型の変数は、変数の名前、予約語文字列を指定し、必要に応じて最大サイズ (つまり、文字列の長さ) を角括弧で指定することによって定義されます。 最大文字列サイズを設定しない場合、デフォルトで 255 になります。つまり、文字列は 255 文字で構成されます。 文字列の各要素は、その番号で参照できます。 ただし、文字列の入力と出力は、配列の場合のように要素ごとではなく、全体として実行されます。 入力する文字数は最大文字列サイズで指定された数を超えてはならないため、このような超過が発生した場合、「余分な」文字は無視されます。 文字列型変数の手続きと関数 1. Function Copy(S: 文字列; インデックス, カウント: 整数): 文字列; 文字列の部分文字列を返します。 SはString型の式です。 IndexとCountは整数型の式です。 この関数は、インデックス位置から始まるカウント文字を含む文字列を返します。 IndexがSの長さより大きい場合、関数は空の文字列を返します。 2. Procedure Delete(var S: String; Index, Count: Integer); 長さ Count の文字の部分文字列を文字列 S から位置 Index から削除します。 S は String 型の変数です。 Index と Count は整数型の式です。 Index が S の長さより大きい場合、文字は削除されません。 3. Procedure Insert(ソース: 文字列; var S: 文字列; インデックス: 整数); 指定された位置から開始して、部分文字列を文字列に連結します。 ソースは String 型の式です。 S は、任意の長さの String 型の変数です。 インデックスは整数型の式です。 Insert は、Source を S の位置から S に挿入します。 4.関数の長さ(S:文字列):整数; 文字列 S で実際に使用されている文字数を返します。null で終わる文字列を使用する場合、文字数は必ずしもバイト数と同じではないことに注意してください。 5. 関数 Pos(Substr: 文字列; S: 文字列): 整数; 文字列内の部分文字列を検索します。 Pos は S 内の Substr を探します そして、S 内の Substr の最初の文字のインデックスである整数値を返します。Substr が見つからない場合、Pos はゼロを返します。 12. 録音 レコードは、さまざまなタイプに属する限られた数の論理的に関連するコンポーネントのコレクションです。 レコードのコンポーネントはフィールドと呼ばれ、各フィールドは名前で識別されます。 レコードフィールドには、フィールドの名前が含まれ、その後にフィールドのタイプを示すコロンが続きます。 レコードフィールドは、ファイルタイプを除いて、Pascalで許可されている任意のタイプにすることができます。 Pascal言語でのレコードの記述は、サービスワードRECORDを使用して実行され、その後にレコードのコンポーネントの記述が続きます。 エントリの説明は、サービスワードENDで終わります。 たとえば、ノートブックには姓、イニシャル、電話番号が含まれているため、次のエントリとしてノートブック内の別の行を表すと便利です。 タイプ行=レコード FIO:文字列[20]; 電話: 文字列[7]; 終わり var str: 行; タイプ名を使用しないレコードの説明も可能です。たとえば、次のようになります。 var str: 記録 FIO:文字列[20]; 電話: 文字列[7]; 終わり レコード全体の参照は、同じタイプのレコード名が割り当て記号の左右に使用されている割り当てステートメントでのみ許可されます。 他のすべての場合、レコードの個別のフィールドが操作されます。 個々のレコードコンポーネントを参照するには、レコード名を指定し、ドットを使用して目的のフィールドの名前を指定する必要があります。 このような名前は複合名と呼ばれます。 レコードコンポーネントはレコードにすることもできます。その場合、識別名にはXNUMXつではなく、より多くの名前が含まれます。 with append 演算子を使用すると、レコード コンポーネントの参照を簡略化できます。 各フィールドを特徴付ける複合名をフィールド名だけに置き換え、結合ステートメントでレコード名を定義できます。 個々のレコードの内容が、そのフィールドの XNUMX つの値に依存する場合があります。 Pascal 言語では、共通部分と異体部分から構成されるレコード記述が許可されます。 バリアント部分は、コンストラクトのケース P を使用して指定されます。ここで、P は、レコードの共通部分からのフィールドの名前です。 このフィールドで受け入れられる可能な値は、バリアント ステートメントと同じ方法でリストされます。 ただし、バリアント ステートメントで行われるように、実行するアクションを指定する代わりに、バリアント フィールドが括弧で指定されます。 バリアント部分の説明はサービス語 end で終わります。 フィールド タイプ P は、バリアント パーツのヘッダーで指定できます。 レコードは、型付き定数を使用して初期化されます。 13.セット Pascal 言語における集合の概念は、集合の数学的概念に基づいています。集合は、さまざまな要素の限定されたコレクションです。 列挙型または間隔データ型は、具体的なセット型を構築するために使用されます。 セットを構成する要素の型は、基本型と呼ばれます。 複数のタイプは、機能語のセットを使用して記述されます。次に例を示します。 タイプ M = B のセット。 ここで、Mは複数形、Bは基本型です。 変数が複数型に属するかどうかは、変数宣言セクションで直接決定できます。 セット型定数は、コンマで区切られた、基本型要素または間隔の括弧で囲まれたシーケンスとして記述されます。 代入 (:=)、和集合 (+)、交差 (*)、および減算 (-) 演算は、集合型の変数と定数に適用できます。 これらの操作の結果は、複数型の値です。 1) ['A','B'] + ['A','D'] は ['A','B','D'] を返します。 2)['A'] * ['A'、'B'、'C']は['A'];を与えます。 3) ['A','B','C'] - ['A','B'] は ['C'] を返します 操作は、同一 (=)、非同一 (<>)、内包 (<=)、内包 (>=) の複数の値に適用できます。 これらの操作の結果は、ブール型になります。 1) ['A','B'] = ['A','C'] は FALSE を返します。 2)['A'、'B'] <> ['A'、'C']はTRUEを返します。 3)['B'] <= ['B'、'C']はTRUEを返します。 4) ['C','D'] >= ['A'] は FALSE を返します。 これらの操作に加えて、セット型の値を操作するには、in 操作が使用されます。これは、操作記号の左側にある基本型の要素が操作記号の右側にあるセットに属しているかどうかを確認します。 . この操作の結果はブール値です。 複数のタイプの値をI/Oリストの要素にすることはできません。 Pascal言語からのコンパイラの具体的な実装ごとに、セットが構築される基本タイプの要素の数が制限されます。 14. ファイル。 ファイル操作 ファイル データ型は、同じ型のコンポーネントの順序付きコレクションを定義します。 ファイルを操作するときは、I / O操作が実行されます。 入力操作は外部デバイスからメモリへのデータの転送であり、出力操作はメモリから外部デバイスへのデータの転送です。 テキストファイル このようなファイルを説明するために、Text タイプがあります。 var TF1、TF2:テキスト; コンポーネント ファイル コンポーネントまたは型付きファイルは、そのコンポーネントの型が宣言されたファイルです。 タイプ M = T のファイル。 ここで、M はファイル タイプの名前です。 T - コンポーネント タイプ。 操作はプロシージャーを使用して実行されます。 書き込み(f, X1,X2,...XK) 型なしファイル 型指定されていないファイルを使用すると、コンピュータ メモリの任意のセクションをディスクに書き込んで読み取ることができます。 var f:ファイル; 1.プロシージャAssign(var F; FileName:String); ファイル名を変数にマップします。 2. プロシージャ Close(varF); ファイル変数と外部ディスク ファイルの間のリンクを解除し、ファイルを閉じます。 3.関数Eof(var F):ブール値; {型付きまたは型なしのファイル} 関数Eof[(var F:Text)]:ブール値; {テキストファイル} ファイルの終わりをチェックします。 4. 手順 Erase(var F); F に関連付けられた外部ファイルを削除します。 5. 関数 FileSize(var F): 整数; ファイル F のサイズをバイト単位で返します。 6.Function FilePos(varF): LongInt; ファイル内の現在の位置を返します。 7. 手順 Reset(var F [: File; RecSize: Word]); 既存のファイルを開きます。 8.プロシージャRewrite(var F:File [; Recsize:Word]); 新しいファイルを作成して開きます。 9. 手順 Seek(var F; N: LongInt); 現在のファイル位置を指定されたコンポーネントに移動します。 10.プロシージャAppend(var F:Text); 添加。 11.関数Eoln[(var F:Text)]:ブール値; 文字列の終わりをチェックします。 12. プロシージャ Read(F, V1 [, V2..., Vn]); {型付きファイルと型なしファイル} プロシージャ Read([var F: Text;] V1 [, V2..., Vn]); {テキストファイル} ファイル コンポーネントを変数に読み込みます。 13. プロシージャ Readln([var F: Text;] V1 [, V2..., Vn]); 行末マーカーを含むファイル内の文字列を読み取り、次の文字列の先頭に移動します。 14. 関数 SeekEof[(var F: テキスト)]: ブール値; ファイル終了記号を返します。 開いているテキスト ファイルにのみ使用されます。 15. プロシージャ Writeln([var F: Text;] [P1, P2..., Pn]); {テキストファイル} 書き込み操作を実行し、ファイルに行末マーカーを配置します。 15. モジュール。 モジュールの種類 Pascal のユニット (UNIT) は、特別に設計されたサブルーチンのライブラリです。 モジュールは、プログラムとは異なり、単独で実行するために起動することはできず、プログラムや他のモジュールの構築にのみ参加できます。 Pascalのモジュールは、個別に保存され、個別にコンパイルされたプログラムユニットです。 モジュールのすべてのプログラム要素は、次のXNUMXつの部分に分けることができます。 1)他のプログラムまたはモジュールによる使用を目的としたプログラム要素。このような要素は、モジュールの外部で表示可能と呼ばれます。 2)モジュール自体の操作にのみ必要なソフトウェア要素は、非表示(または非表示)と呼ばれます。 unit <モジュール名>; {モジュールのタイトル} インタフェース {モジュールの目に見えるプログラム要素の説明} 実装 {モジュールの隠されたプログラミング要素の説明} 始まる {モジュール要素の初期化ステートメント} 終わり。 モジュールで宣言された変数を参照するには、モジュール名と変数名をドットで区切った複合名を使用する必要があります。 モジュールの再帰的な使用は禁止されています。 モジュールの種類を挙げてみましょう。 1. システムモジュール。 SYSTEMモジュールは、I / O、文字列操作、浮動小数点演算、動的メモリ割り当てなど、すべての組み込み機能に対して低レベルのサポートルーチンを実装します。 2.DOS モジュール。 Dos モジュールは、GetTime、SetTime、DiskSize など、最も一般的に使用される DOS 呼び出しと同等の多数の Pascal ルーチンと関数を実装しています。 3. CRT モジュール。 CRT モジュールは、画面モード制御、拡張キーボード コード、色、ウィンドウ、サウンドなど、PC の機能を完全に制御する強力なプログラムを多数実装しています。 4.GRAPHモジュール。 このモジュールに含まれている手順と機能を使用して、画面上にさまざまなグラフィックを作成できます。 5. オーバーレイ モジュール。 OVERLAY モジュールを使用すると、リアル モード DOS プログラムのメモリ要件を減らすことができます。 16.参照データ型。 動的メモリ。 動的変数。 動的メモリの操作 静的変数 (静的に割り当てられた) は、プログラムで明示的に宣言された変数であり、名前で参照されます。 静的変数を配置するメモリ内の場所は、プログラムのコンパイル時に決定されます。 このような静的変数とは異なり、Pascal プログラムでは動的変数を作成できます。 動的変数の主な特性は、それらが作成され、プログラムの実行中にメモリが割り当てられることです。 動的変数は、動的メモリ領域 (ヒープ領域) に配置されます。 動的変数は、変数宣言で明示的に指定されていないため、名前で参照できません。 このような変数には、ポインターと参照を使用してアクセスします。 参照型(ポインター)は、基本型と呼ばれる特定の型の動的変数を指す値のセットを定義します。 参照型変数には、メモリ内の動的変数のアドレスが含まれています。 基本型が宣言されていない識別子である場合は、型宣言のポインタ型と同じ部分で宣言する必要があります。 予約語 nil は、ポインタ値が何も指していない定数を示します。 動的変数の記述例を挙げましょう。 var p1、p2: ^real; p3、p4: ^整数; ... 動的メモリの手続きと機能 1.手順New{varp:Pointer)。 動的変数 p" を格納するために動的メモリ領域にスペースを割り当て、そのアドレスをポインタ p に割り当てます。 2. 手順 Dispose(var p: Pointer)。 New プロシージャによって動的変数割り当て用に割り当てられたメモリを解放し、ポインター p の値は未定義になります。 3. プロシージャ GetMem(var p: ポインタ; サイズ: ワード)。 ヒープ領域にメモリセクションを割り当て、その先頭のアドレスをポインタpに割り当てます。セクションのサイズ(バイト単位)は、sizeパラメータで指定されます。 4. 手続き FreeMem(varp: Pointer; size: Word)。 開始アドレスがpポインタで指定され、サイズがsizeパラメータで指定されているメモリ領域を解放します。 ポインタ値pは未定義になります。 5. プロシージャ Mark{var p: Pointer) は、その呼び出し時に、空き動的メモリのセクションの先頭のアドレスをポインタ p に書き込みます。 6. Release(var p: Pointer) プロシージャは、Mark プロシージャによってポインタ p に書き込まれたアドレスから始まる動的メモリのセクションを解放します。つまり、Mark プロシージャの呼び出し後に占有されていた動的メモリをクリアします。 7. 関数 MaxAvail: 倍長整数は、動的メモリの最長の空きセクションの長さをバイト単位で返します。 8. 関数 MemAvail: 倍長整数は、空き動的メモリの総量をバイト単位で返します。 9. ヘルパー関数 SizeOf(X):Word は、X が占めるサイズをバイト単位で返します。ここで、X は、任意の型の変数名または型名のいずれかです。 17.抽象的なデータ構造 配列、セット、レコードなどの構造化データ型は、プログラムの実行中にサイズが変わらないため、静的構造です。 多くの場合、問題を解決する過程でデータ構造のサイズを変更する必要があります。 このようなデータ構造は動的と呼ばれます。 これらには、スタック、キュー、リスト、ツリーなどが含まれます。 配列、レコード、およびファイルを使用して動的構造を記述すると、コンピューターのメモリが無駄に使用され、問題を解決するための時間が長くなります。 動的構造の各コンポーネントは、少なくともXNUMXつのフィールドを含むレコードです。XNUMXつは「ポインタ」タイプのフィールドで、もうXNUMXつはデータ配置用です。 一般に、レコードにはXNUMXつではなく、複数のポインターと複数のデータフィールドが含まれる場合があります。 データフィールドには、変数、配列、セット、またはレコードを指定できます。 ポインティング部分にリストの XNUMX つの要素のアドレスが含まれている場合、リストは単方向 (または単一リンク) と呼ばれます。 XNUMX つのコンポーネントが含まれている場合は、二重接続されています。 リストに対してさまざまな操作を実行できます。次に例を示します。 1) リストに要素を追加する。 2) 指定されたキーを持つリストから要素を削除します。 3)キーフィールドの指定された値を持つ要素を検索します。 4)リストの要素を並べ替えます。 5)リストをXNUMXつ以上のリストに分割する。 6)XNUMXつ以上のリストをXNUMXつに結合する。 7) その他の操作。 ただし、原則として、さまざまな問題を解決するためにすべての操作が必要になるわけではありません。 したがって、適用する必要がある基本的な操作に応じて、さまざまな種類のリストがあります。 これらの中で最も一般的なのはスタックとキューです。 18.スタック スタックは動的なデータ構造であり、コンポーネントの追加とコンポーネントの削除は、スタックの最上位と呼ばれる一方の端から行われます。 スタックは、LIFO (Last-In, First-Out) - 「後入れ先出し」の原則に基づいて機能します。 通常、スタックに対して実行される操作は XNUMX つあります。 1) スタックの初期形成 (最初のコンポーネントの記録); 2) コンポーネントをスタックに追加する。 3) コンポーネントの選択 (削除)。 スタックを形成して操作するには、「ポインター」型の XNUMX つの変数が必要です。XNUMX つ目はスタックのトップを決定し、XNUMX つ目は補助変数です。 例。 スタックを形成し、それに任意の数のコンポーネントを追加してから、すべてのコンポーネントを読み取るプログラムを作成します。 プログラム STACK; Crt を使用します。 type アルファ = 文字列[10]; PComp = ^Comp; Comp=レコード SD: アルファ; p次: PComp 終わり VAR pトップ: PComp; sc: アルファ; ProcedureStack を作成します(var pTop: PComp; var sC: Alfa); 始まる 新しい (pTop); pTop^.pNext:= NIL; pTop^.sD:= sC; 終わり ProcedureComp(var pTop: PComp; var sC: Alfa); を追加します。 var pAux:PComp; 始まる 新しい(pAux); pAux ^ .pNext:= pTop; pTop:=pAux; pTop^.sD:= sC; 終わり 手順 DelComp(var pTop: PComp; var sC: ALFA); 始まる sC:= pTop^.sD; pTop:= pTop ^ .pNext; 終わり 始まる Clrscr; writeln(ENTER STRING); readln(SC); CreateStack(pTop、sc); 繰り返す writeln(ENTER STRING); readln(SC); AddComp(pTop、sc); sC = 'END' まで; 19. 待ち行列 キューは動的なデータ構造であり、一方の端でコンポーネントが追加され、もう一方の端で取得されます。 キューは、FIFO (First-In, First-Out) - 「先入れ先出し」の原則に基づいて機能します。 例。 キューを形成し、それに任意の数のコンポーネントを追加してから、すべてのコンポーネントを読み取るプログラムを作成します。 ProgramQUEUE; Crt を使用します。 type アルファ = 文字列[10]; PComp = ^Comp; コンプ=記録 SD: アルファ; pNext:PComp; 終わり VAR pBegin、pEnd: PComp; sc: アルファ; ProcedureQueue を作成します(var pBegin,pEnd: PComp; var sc: アルファ); 始まる 新しい (pBegin); pBegin^.pNext:= NIL; pBegin^.sD:= sC; pEnd:=pBegin; 終わり 手順 AddQueue(var pEnd: PComp; var sC: アルファ); var pAux:PComp; 始まる New(pAux); pAux^.pNext:= NIL; pEnd^.pNext:= pAux; pEnd:= pAux; pEnd ^ .sD:= sC; 終わり 手順 DelQueue(var pBegin: PComp; var sC: アルファ); 始まる sC:=pBegin^.sD; pBegin:= pBegin^.pNext; 終わり 始まる Clrscr; writeln(ENTER STRING); readln(SC); CreateQueue(pBegin、pEnd、sc); 繰り返す writeln(ENTER STRING); readln(SC); AddQueue(pEnd, sc); sC = 'END' まで; 20. ツリーデータ構造 ツリー状のデータ構造は、要素とノードの有限集合であり、その間に関係 (ソースと生成されたものとの間の接続) があります。 N. Wirth によって提案された再帰的な定義を使用する場合、基本型 t を持つツリー データ構造は、空の構造体または型 t のノードのいずれかであり、サブツリーと呼ばれる基本型 t を持つツリー構造の有限集合は、関連する。 次に、ツリー構造を操作するときに使用される定義を示します。 ノード y がノード x の直下に位置する場合、ノード y はノード x の直接の子孫と呼ばれ、x はノード y の直接の祖先となります。つまり、ノード x が i 番目のレベルにある場合、ノード y はそれに応じて(i + 1 ) - 番目のレベルにあります。 ツリー ノードの最大レベルは、ツリーの高さまたは深さと呼ばれます。 祖先には、ツリーのノード (ルート) が XNUMX つしかないわけではありません。 子を持たないツリー ノードは、リーフ ノード (またはツリーの葉) と呼ばれます。 他のすべてのノードは内部ノードと呼ばれます。 ノードの直接の子の数によってそのノードの次数が決まり、特定のツリー内のノードの最大次数によってツリーの次数が決まります。 祖先と子孫を交換することはできません。つまり、元の動作と生成された動作の間の接続は一方向にのみ作用します。 ツリーのルートから特定のノードに移動する場合、この場合にトラバースされるツリーのブランチの数は、このノードのパスの長さと呼ばれます。 ツリーのすべてのブランチ (ノード) が順序付けられている場合、そのツリーは順序付けられていると言われます。 二分木は、木構造の特殊なケースです。 これらは、各子が最大 XNUMX つの子を持つツリーであり、左サブツリーと右サブツリーと呼ばれます。 したがって、二分木は次数が XNUMX のツリー構造です。 バイナリツリーの順序は、次のルールによって決定されます。各ノードには独自のキーフィールドがあり、各ノードのキー値は、左側のサブツリーのすべてのキーよりも大きく、右側のサブツリーのすべてのキーよりも小さくなります。 次数がXNUMXより大きいツリーは、強分岐と呼ばれます。 21.木の操作 さらに、二分木に関連するすべての操作を検討します。 I. ツリーを構築します。 順序付けられたツリーを構築するためのアルゴリズムを提示します。 1.ツリーが空の場合、データはツリーのルートに転送されます。 ツリーが空でない場合、ツリーの順序に違反しないように、そのブランチのXNUMXつが下降します。 その結果、新しいノードがツリーの次のリーフになります。 2. 既存のツリーにノードを追加するには、上記のアルゴリズムを使用できます。 3.ツリーからノードを削除するときは、注意が必要です。 削除するノードがリーフの場合、または子がXNUMXつしかない場合、操作は簡単です。 削除するノードにXNUMXつの子孫がある場合、その子孫の中からその場所に配置できるノードを見つける必要があります。 これは、ツリーを注文する必要があるために必要です。 これを行うことができます:削除するノードを、左側のサブツリーで最大のキー値を持つノード、または右側のサブツリーで最小のキー値を持つノードと交換してから、目的のノードをリーフとして削除します。 Ⅱ. 指定されたキー フィールド値を持つノードを検索します。 この操作を実行するときは、ツリーをトラバースする必要があります。 ツリーを作成するさまざまな形式(接頭辞、中置辞、接尾辞)を考慮する必要があります。 疑問が生じます: ツリーのノードをどのように表現すれば、それらを操作するのが最も便利になるでしょうか? 配列を使用してツリーを表すことができます。各ノードは、文字型の情報フィールドと参照型の XNUMX つのフィールドを持つ結合型の値によって記述されます。 しかし、ツリーには事前に定義されていないノードが多数あるため、これはあまり便利ではありません。 したがって、ツリーを記述するときは動的変数を使用するのが最善です。 次に、各ノードは、指定された数の情報フィールドの説明を含む同じタイプの値で表され、対応するフィールドの数はツリーの次数に等しくなければなりません。 参照 nil によって子孫の不在を定義することは論理的です。 次に、Pascal では、バイナリ ツリーの記述は次のようになります。 TYPE TreeLink = ^ Tree; ツリー = レコード; Inf: <データ型>; 左、右: TreeLink; 終了 22. 運用の実施例 1. 最小の高さの XNUMX つのノードからなるツリー、または完全にバランスの取れたツリーを構築します (このようなツリーの左右のサブツリーのノード数は XNUMX を超えてはなりません)。 再帰的構築アルゴリズム: 1) 最初のノードがツリーのルートと見なされます。 2) nl ノードの左サブツリーが同じ方法で構築されます。 3)nrノードの右側のサブツリーも同じ方法で作成されます。 nr = n - nl - 1 情報フィールドとして、キーボードから入力されたノード番号を取得します。 この構造を実装する再帰関数は次のようになります。 機能ツリー(n:バイト): TreeLink; ヴァート: TreeLink; nl、nr、x: バイト。 始める n = 0 の場合、ツリー:= nil 他 始める nl:= n div 2; nr = n - nl - 1; writeln('頂点番号を入力してください); readln(x); new(t); t ^ .inf:= x; t^.left:= ツリー(nl); t^.right:= ツリー(nr); ツリー:= t; 終わり; {木} 終了 2. 二分順序ツリーで、指定されたキー フィールドの値を持つノードを見つけます。 ツリーにそのような要素がない場合は、ツリーに追加します。 検索手順(x: Byte; var t: TreeLink); 始める t = nilの場合、 始める 新しい(t); t^inf:= x; t^.left:= nil; t^.right:= nil; 終わり そうでなければ x < t^.inf の場合 検索(x, t^.左) それ以外の場合、x> t^.infの場合 Search(x、t ^ .right) 他 始める {見つかった要素を処理する} ... 終わり; 終了 23. グラフの概念。 グラフを表現する方法 グラフはペアG=(V、E)です。ここで、Vは頂点と呼ばれる任意の性質のオブジェクトのセットであり、Eはエッジと呼ばれるペアei =(vil、vi2)、vijOVのファミリーです。 一般的なケースでは、集合Vおよび(または)ファミリーEは無限の数の要素を含むことができますが、有限グラフ、つまりVとEの両方が有限であるグラフのみを検討します。 eiに含まれる要素の順序が重要な場合、グラフは有向と呼ばれ、有向グラフと省略されます。それ以外の場合は、無向と呼ばれます。 有向グラフのエッジは円弧と呼ばれます。 e=の場合の場合、頂点vとuはエッジの端と呼ばれます。 ここで、エッジeは頂点vとuのそれぞれに隣接(インシデント)していると言います。 頂点vとおよびは隣接(インシデント)とも呼ばれます。 一般的な場合、形式e=のエッジ; このようなエッジはループと呼ばれます。 グラフ頂点の次数は、特定の頂点に付随するエッジの数であり、ループは XNUMX 回カウントされます。 ノードの重みは、特定のノードに割り当てられた数値 (実数、整数、または有理数) です (コスト、スループットなどとして解釈されます)。 グラフ内のパス (または有向グラフ内のルート) は、v0、(v0,v1)、v1、...、(vn -1、 vn)、vn.数値 n は経路長と呼ばれます。エッジの繰り返しがないパスはチェーンと呼ばれ、頂点の繰り返しがないパスは単純チェーンと呼ばれます。エッジの繰り返しのない閉じたパスはサイクル (または 有向グラフの等高線); 頂点を繰り返さずに(最初と最後を除く)-単純なサイクル。 任意の XNUMX つの頂点間にパスがある場合、グラフは接続されていると呼ばれ、それ以外の場合は切断されていると呼ばれます。 グラフの表現にはさまざまな方法があります。 1. 発生率マトリックス。 これは n x m の長方形行列で、n は頂点の数、m はエッジの数です。 2. 隣接行列。 これは n × n 次元の正方行列で、n は頂点の数です。 3. 隣接関係 (インシデント) のリスト。 次のデータ構造を表します。 グラフの各頂点には、それに隣接する頂点のリストが格納されます。 リストはポインターの配列であり、その i 番目の要素には、i 番目の頂点に隣接する頂点のリストへのポインターが含まれます。 4.リストのリスト。 これは、XNUMX つの枝にそれぞれに隣接する頂点のリストが含まれるツリー状のデータ構造です。 24. さまざまなグラフ表現 グラフを発生率リストとして実装するには、次の型を使用できます。 TypeList = ^S; S=レコード; inf:バイト; 次へ:リスト; 終わり 次に、グラフは次のように定義されます。 Vargr: リストの配列[1..n]; それでは、グラフトラバーサル手順に移りましょう。 これは、グラフのすべての頂点を表示し、すべての情報フィールドを分析できる補助アルゴリズムです。 グラフのトラバーサルを詳細に検討すると、再帰的アルゴリズムと非再帰的アルゴリズムの XNUMX 種類があります。 Pascal では、深さ優先トラバーサル手順は次のようになります。 手順 Obhod(gr: グラフ; k: バイト); Varg:グラフ; l:リスト; 始める nov[k]:= 偽; g:=gr; g^.inf <> k している間 g:= g^.next; l:= g ^ .smeg; l <> nil が始まる間 nov[l^.inf] の場合、Obod(gr, l^.inf); l:= l^.next; 終わり; 終わり; グラフをリストのリストとして表現する グラフは、次のようにリストのリストを使用して定義できます。 TypeList = ^ Tlist; tlist = record inf:バイト; 次へ:リスト; 終わり グラフ = ^TGpaph; TGpaph = レコード inf:バイト; smeg: リスト; 次: グラフ; 終わり グラフを横方向に走査するとき、任意の頂点を選択し、それに隣接するすべての頂点を一度に調べます。 以下は、疑似コードで幅方向にグラフをトラバースする手順です。 手順 Obhod2(v); 始める キュー = O; キュー <= v; nov [v] = False; キューの間<> O do 始める p <= キュー; spisok(p)のuについては、 新しい[u]の場合 始める nov[u]:= 偽; キュー <= u; 終わり; 終わり; 終わり; 25. Pascal でのオブジェクト型。 オブジェクトの概念、その説明と使用 オブジェクト指向プログラミング言語は、次のXNUMXつの主要な特性によって特徴付けられます。 1)カプセル化。 レコードを、これらのレコードのフィールドを操作するプロシージャおよび関数と組み合わせると、新しいデータ型(オブジェクト)が形成されます。 2) 継承。 オブジェクトの定義と、階層に関連する各子オブジェクトがすべての親オブジェクトのコードとデータにアクセスできる機能を備えた子オブジェクトの階層を構築するためのその使用。 3) ポリモーフィズム。 アクションに単一の名前を付けて、オブジェクトの階層を上下に共有し、階層内の各オブジェクトがそのアクションを適切な方法で実行します。 オブジェクトといえば、新しいデータ型オブジェクトを導入します。 オブジェクト型は、一定数のコンポーネントから構成される構造です。 各コンポーネントは、厳密に定義された型のデータを含むフィールド、またはオブジェクトに対して操作を実行するメソッドのいずれかです。 オブジェクトタイプは、別のオブジェクトタイプのコンポーネントを継承できます。 タイプT2がタイプT1から継承する場合、タイプT2はタイプGの子であり、タイプG自体はタイプG2の親です。 次のソースコードは、オブジェクトタイプ宣言の例を示しています。 type ポイント = オブジェクト X、Y: 整数。 終わり Rect=オブジェクト A、B: T ポイント。 procedure Init(XA, YA, XB, YB: 整数); プロシージャCopy(var R:TRectangle); プロシージャ Move(DX, DY: 整数); プロシージャGrow(DX、DY:整数); プロシージャ Intersect(var R: TRectangle); 手順 Union(var R: TRectangle); function Contains(P: ポイント): Boolean; 終わり 他の型とは異なり、オブジェクト型は、プログラムまたはモジュールのスコープの最も外側のレベルにある型宣言セクションでのみ宣言できます。 したがって、変数宣言セクション、またはプロシージャ、関数、またはメソッド ブロック内でオブジェクト型を宣言することはできません。 ファイル タイプ コンポーネント タイプは、オブジェクト タイプまたはオブジェクト タイプ コンポーネントを含む構造タイプを持つことはできません。 26.継承 継承は、既存の親型から新しい子型を生成するプロセスであり、子は親からすべてのフィールドとメソッドを受け取ります (継承します)。 この場合、子孫の型は相続人または子の型と呼ばれます。 そして、子型が継承する型を親型と呼びます。 継承されたフィールドとメソッドは、変更せずに使用することも、再定義(変更)することもできます。 N. Wirthは、彼の言語でPascalが最大限の単純さを追求したため、継承関係を導入することで複雑化することはありませんでした。 したがって、Pascalの型は継承できません。 ただし、Turbo Pascal 7.0 では、継承をサポートするためにこの言語が拡張されています。 そのような拡張機能の XNUMX つは、レコードに関連する新しいデータ構造カテゴリですが、はるかに強力です。 この新しいカテゴリのデータ型は、新しい予約語 Object を使用して定義されます。 構文は、レコードを定義するための構文に非常に似ています。 タイプ <型名> = オブジェクト [(<親型名>)] ([<スコープ>] <フィールドとメソッドの説明>)+ 終わり 括弧内の構文構造の後の「+」記号は、この構造がこの説明で XNUMX 回以上出現する必要があることを意味します。 スコープは、次のキーワードのいずれかです。 ▪プライベート。 ▪ 保護されています。 ▪ 公開。 スコープは、このスコープを指定するキーワードに続く記述を持つコンポーネントが、プログラムのどの部分で使用可能になるかを特徴付けます。 コンポーネント スコープの詳細については、質問 #28 を参照してください。 継承は、プログラム開発で使用される強力なツールです。 これにより、言語を使用して階層を形成するタイプのオブジェクト間の関係を表現し、問題のオブジェクト指向分解を実際に実装できます。また、プログラムコードの再利用も促進されます。 27.オブジェクトのインスタンス化 オブジェクトのインスタンスは、オブジェクト型の変数または定数を宣言するか、標準の New プロシージャを「オブジェクト型へのポインタ」型の変数に適用することによって作成されます。 結果のオブジェクトは、オブジェクト タイプのインスタンスと呼ばれます。 オブジェクトタイプに仮想メソッドが含まれている場合、そのオブジェクトタイプのインスタンスは、仮想メソッドを呼び出す前にコンストラクターを呼び出して初期化する必要があります。 オブジェクトタイプのインスタンスを割り当てることは、インスタンスの初期化を意味するものではありません。 オブジェクトは、コンストラクターの呼び出しから、実行がコンストラクターのコードブロックの最初のステートメントに実際に到達するポイントまでの間に実行されるコンパイラー生成コードによって初期化されます。 オブジェクトインスタンスが初期化されておらず、範囲チェックが有効になっている場合({$ R +}ディレクティブによる)、オブジェクトインスタンスの仮想メソッドへの最初の呼び出しで実行時エラーが発生します。 {$ R-}ディレクティブによって範囲チェックがオフになっている場合)、初期化されていないオブジェクトの仮想メソッドを最初に呼び出すと、予期しない動作が発生する可能性があります。 必須の初期化ルールは、構造体タイプのコンポーネントであるインスタンスにも適用されます。 例えば: VAR コメント: TStrField の配列 [1..5]。 I:整数 始まる Iの場合:= 1〜5 コメント[I].Init(1、I + 10、40、'first_name'); . . . Iの場合:= 1〜5コメント[I]を実行します。完了; 終わり 動的インスタンスの場合、初期化は通常、配置に関するものであり、クリーンアップは削除に関するものです。これは、NewおよびDispose標準プロシージャの拡張構文によって実現されます。 例えば: VAR SP:StrFieldPtr; 始まる New(SP、Init(1、1、25、'first_name'); SP^.Put('ウラジミール'); SP^.表示; . . . 処分(SP、完了); 終わり。 オブジェクトタイプへのポインタは、任意の親オブジェクトタイプへのポインタと割り当て互換であるため、実行時に、オブジェクトタイプへのポインタは、そのタイプのインスタンスまたは任意の子タイプのインスタンスを指すことができます。 28. コンポーネントと範囲 Bean識別子のスコープは、オブジェクトタイプを超えています。 さらに、Bean識別子のスコープは、オブジェクトタイプとその子孫のメソッドを実装するプロシージャ、関数、コンストラクタ、およびデストラクタのブロックにまで及びます。 これらの考慮事項に基づいて、コンポーネント識別子は、オブジェクトタイプ内、そのすべての子孫内、およびそのすべてのメソッド内で一意である必要があります。 オブジェクト型の宣言では、メソッド ヘッダーは、宣言がまだ完了していない場合でも、記述されているオブジェクト型のパラメーターを指定できます。 すべての有効なスコープのコンポーネントを含む型宣言の次のスキーマを検討してください。 タイプ <型名> = オブジェクト [(<親型名>)] プライベート <フィールドとメソッドのプライベートな説明> 保護されました <保護されたフィールドとメソッドの説明> 公共 <フィールドとメソッドの公開説明> 終わり Private セクションで説明されているフィールドとメソッドは、それらの宣言を含むモジュール内でのみ使用でき、それ以外の場所では使用できません。 保護されたフィールドとメソッド、つまり、保護されたセクションで説明されているものは、型が定義されているモジュールと型の子孫に表示されます。 Public セクションのフィールドとメソッドは、その使用に制限がなく、この型のオブジェクトにアクセスできるプログラム内のどこでも使用できます。 型宣言のプライベート部分に記述されたコンポーネント識別子の範囲は、オブジェクトの型宣言を含むモジュール (プログラム) に限定されます。 つまり、プライベート識別子 Bean は、オブジェクト型宣言を含むモジュール内では通常のパブリック識別子のように機能し、モジュールの外側ではプライベート Bean と識別子は不明であり、アクセスできません。 関連するタイプのオブジェクトを同じモジュールに配置することで、これらのオブジェクトが互いのプライベート コンポーネントにアクセスできることを確認でき、これらのプライベート コンポーネントは他のモジュールから認識されなくなります。 29. 方法 オブジェクト型内のメソッド宣言は、前方メソッド宣言 (forward) に対応します。 したがって、オブジェクト型宣言の後のどこかで、ただしオブジェクト型宣言のスコープと同じスコープ内で、その宣言を定義することによってメソッドを実装する必要があります。 手続き型および関数型メソッドの場合、定義宣言は通常の手続きまたは関数宣言の形式を取りますが、この場合、手続きまたは関数識別子はメソッド識別子として扱われます。 メソッドの定義記述には、オブジェクト型を持つ仮変数パラメーターに対応する識別子 Self を持つ暗黙パラメーターが常に含まれます。 メソッド ブロック内で、 Self は、メソッド コンポーネントがメソッドを呼び出すように指定されたインスタンスを表します。 したがって、Self フィールドの値に対する変更は、インスタンスに反映されます。 仮想メソッド メソッドはデフォルトで静的ですが、コンストラクターを除いて、仮想にすることができます(メソッド宣言に仮想ディレクティブを含めることにより)。 コンパイラは、コンパイルプロセス中に静的メソッド呼び出しへの参照を解決しますが、仮想メソッド呼び出しは実行時に解決されます。 これは、遅延バインディングと呼ばれることもあります。 静的メソッドのオーバーライドは、メソッド ヘッダーの変更とは無関係です。 対照的に、仮想メソッドのオーバーライドでは、順序、パラメーターの型と名前、および関数の結果の型 (存在する場合) を保持する必要があります。 さらに、再定義には virtual ディレクティブを再度含める必要があります。 動的メソッド Borland Pascal は、動的メソッドと呼ばれる追加の遅延バインド メソッドをサポートしています。 動的メソッドは、実行時にディスパッチされる方法のみが仮想メソッドと異なります。 他のすべての点で、動的メソッドは仮想メソッドと同等と見なされます。 動的メソッド宣言は仮想メソッド宣言と同等ですが、動的メソッド宣言には、virtualキーワードの直後に指定される動的メソッドインデックスを含める必要があります。 動的メソッドのインデックスは、1〜656535の整数定数である必要があり、オブジェクトタイプまたはその祖先に含まれる他の動的メソッドのインデックス間で一意である必要があります。 例えば: プロシージャFileOpen(var Msg:TMessage); 仮想100; 動的メソッドのオーバーライドは、パラメーターの順序、タイプ、および名前と一致し、親メソッドの関数の結果タイプと正確に一致する必要があります。 オーバーライドには、仮想ディレクティブと、それに続く祖先オブジェクトタイプで指定されたものと同じ動的メソッドインデックスも含める必要があります。 30. コンストラクタとデストラクタ コンストラクタとデストラクタは、特殊な形式のメソッドです。 NewおよびDispose標準プロシージャの拡張構文に関連して使用されるコンストラクタとデストラクタには、動的オブジェクトを配置および削除する機能があります。 さらに、コンストラクターには、仮想メソッドを含むオブジェクトの必要な初期化を実行する機能があります。 すべてのメソッドと同様に、コンストラクタとデストラクタは継承でき、オブジェクトには任意の数のコンストラクタとデストラクタを含めることができます。 コンストラクターは、新しく作成されたオブジェクトを初期化するために使用されます。 通常、初期化は、パラメーターとしてコンストラクターに渡される値に基づいています。 仮想メソッドのディスパッチメカニズムは、オブジェクトを最初に初期化したコンストラクターに依存するため、コンストラクターを仮想にすることはできません。 コンストラクターの例を次に示します。 コンストラクタ Field.Copy(var F: フィールド); 始まる 自己:= F; 終わり 派生 (子) 型のコンストラクターの主なアクションは、ほとんどの場合、直接の親の適切なコンストラクターを呼び出して、オブジェクトの継承されたフィールドを初期化することです。 このプロシージャを実行した後、コンストラクターは、派生型のみに属するオブジェクトのフィールドを初期化します。 デストラクタはコンストラクタの反対であり、オブジェクトが使用された後にクリーンアップするために使用されます。 通常、クリーンアップでは、オブジェクト内のすべてのポインター フィールドを削除します。 注意 デストラクタは仮想である可能性があり、多くの場合仮想です。 デストラクタにパラメータがあることはめったにありません。 デストラクタの例を次に示します。 デストラクタ フィールド Done; 始まる FreeMem(Name、Length(Name ^)+ 1); 終わり デストラクタ StrField.Done; 始まる FreeMem(Value、Len); フィールド完了; 終わり 上記の TStrField などの子型のデストラクタ。 通常、最初に派生型で導入されたポインター フィールドを削除し、最後のステップとして、直接の親の適切なコレクター/デストラクターを呼び出して、オブジェクトの継承されたポインター フィールドを削除します。 31.デストラクタ Borland Pascalは、動的に割り当てられたオブジェクトをクリーンアップおよび削除するためのガベージコレクタ(またはデストラクタ)と呼ばれる特別なタイプのメソッドを提供します。 デストラクタは、オブジェクトを削除するステップと、そのタイプのオブジェクトに必要な他のアクションまたはタスクを組み合わせたものです。 XNUMXつのオブジェクトタイプに対して複数のデストラクタを定義できます。 デストラクタは継承でき、静的または仮想のいずれかになります。 ファイナライザーが異なれば、必要なオブジェクトのタイプも異なる傾向があるため、オブジェクトのタイプごとに正しいデストラクタが実行されるように、デストラクタは常に仮想であることが一般的に推奨されます。 オブジェクトの型定義に仮想メソッドが含まれている場合でも、すべてのクリーンアップ メソッドに対して予約語デストラクタを指定する必要はありません。 デストラクタは、実際には動的に割り当てられたオブジェクトに対してのみ機能します。 動的に割り当てられたオブジェクトがクリーンアップされると、デストラクタは特別な機能を実行します。つまり、動的に割り当てられたメモリ領域で正しいバイト数が常に解放されるようにします。 静的に割り当てられたオブジェクトでデストラクタを使用することについて心配する必要はありません。 実際、オブジェクトの型をデストラクタに渡さないことで、プログラマはその型のオブジェクトから、Borland Pascal の動的メモリ管理の利点を完全に享受できなくなります。 デストラクタは、ポリモーフィック オブジェクトをクリアする必要がある場合や、オブジェクトが占有するメモリの割り当てを解除する必要がある場合に、実際に自分自身になります。 ポリモーフィックオブジェクトは、BorlandPascalの拡張型互換性ルールのために親型に割り当てられたオブジェクトです。 オブジェクトを処理するコードは、コンパイル時に正確にどのタイプのオブジェクトを処理する必要があるかを正確に「知らない」ため、「ポリモーフィック」という用語が適切です。 それが知っている唯一のことは、このオブジェクトが指定されたオブジェクトタイプの子孫であるオブジェクトの階層に属しているということです。 デストラクタメソッド自体は空で、次の機能のみを実行できます。 destructorAnObject.Done; 始まる 終わり このデストラクタで役立つのは、その本体のプロパティではありませんが、コンパイラは、デストラクタの予約語に応答してエピローグ コードを生成します。 これは、何もエクスポートしないモジュールのようなものですが、プログラムを開始する前に初期化セクションを実行することで、目に見えない作業を行います。 すべてのアクションは舞台裏で行われます。 32.仮想メソッド オブジェクト型宣言の後に新しい予約語 virtual が続く場合、メソッドは virtual になります。 親型のメソッドが virtual として宣言されている場合、コンパイラ エラーを回避するために、子型の同じ名前を持つすべてのメソッドも virtual として宣言する必要があります。 以下は、適切に仮想化された給与計算の例のオブジェクトです。 タイプ PEmployee = ^TEmployee; 従業員 = オブジェクト 名前、タイトル: string[25]; レート: レアル; コンストラクターInit(AName、ATitle:String; ARate:Real); 関数 GetPayAmount: 実数; バーチャル; 関数GetName:文字列; 関数 GetTitle: 文字列; 関数 GetRate: 実数; 手順表示; バーチャル; 終わり PH 時間 = ^TH 時間; THourly = object(TEmployee); 時間: 整数。 コンストラクターInit(AName、ATitle:String; ARate:Real; 時間:整数); 関数 GetPayAmount: 実数; バーチャル; 関数 GetTime: 整数; 終わり PSalaried = ^TSalaried; TSalaried = オブジェクト(従業員); 関数 GetPayAmount: 実数; バーチャル; 終わり PCommissioned = ^ TCommissioned; TCommissioned = object(サラリーマン); コミッション: 実質; 売上高: 実質; コンストラクターInit(AName、ATitle:String; ARate、 ACommission、ASalesAmount: Real); 関数 GetPayAmount: 実数; バーチャル; 終わり コンストラクターは、仮想メソッド機構のセットアップ作業を行う特殊なタイプのプロシージャーです。 さらに、仮想メソッドが呼び出される前に、コンストラクターを呼び出す必要があります。 最初にコンストラクターを呼び出さずに仮想メソッドを呼び出すと、システムがブロックされる可能性があり、コンパイラーはメソッドが呼び出される順序をチェックする方法がありません。 仮想メソッドを持つすべてのオブジェクト型には、コンストラクターが必要です。 コンストラクターは、他の仮想メソッドを呼び出す前に呼び出す必要があります。 コンストラクターを事前に呼び出さずに仮想メソッドを呼び出すと、システムロックが発生する可能性があり、コンパイラーはメソッドが呼び出される順序を確認できません。 33.オブジェクトデータフィールドと形式手法パラメーター メソッドとそのオブジェクトが共通のスコープを共有するという事実の意味は、メソッドの仮パラメーターがオブジェクトのデータ フィールドのいずれかと同一であってはならないということです。 これは、オブジェクト指向プログラミングによって課せられた新しい制限ではなく、Pascal が常に持っていた同じ古いスコープ規則です。 これは、プロシージャの仮パラメータがプロシージャのローカル変数と同一であることを禁止するのと同じです。 プロシージャのこのエラーを示す例を考えてみましょう: プロシージャ CrunchIt(Crunchee: MyDataRec、Crunchby、 エラー コード: 整数); VAR A、B: 文字。 エラー コード: 整数; 始まる . . . 終わり ローカル変数ErrorCodeの宣言を含む行でエラーが発生します。 これは、仮パラメータとローカル変数の識別子が同じであるためです。 プロシージャのローカル変数とその仮パラメータは共通のスコープを共有しているため、同一にすることはできません。 このようなものをコンパイルしようとすると、「エラー4:識別子が重複しています」というメッセージが表示されます。 このメソッドが属するオブジェクトのフィールドの名前に正式なメソッドパラメータを割り当てようとすると、同じエラーが発生します。 データ構造内にサブルーチン ヘッダーを配置することは、Turbo Pascal の革新に賛成するため、状況は多少異なりますが、Pascal スコープの基本原則は変更されていません。 変数とパラメーターの識別子を選択するときは、特定の文化を尊重する必要があります。 一部のプログラミング スタイルでは、型フィールドに名前を付けて、識別子が重複するリスクを軽減する方法が提供されています。 たとえば、ハンガリー語の表記法では、フィールド名は "m" プレフィックスで始まることが示唆されています。 34.カプセル化 オブジェクト内のコードとデータの組み合わせは、カプセル化と呼ばれます。 原則として、オブジェクトのユーザーがオブジェクトのフィールドに直接アクセスしないように、十分なメソッドを提供することができます。 Smalltalkなど、他のオブジェクト指向言語には必須のカプセル化が必要ですが、BorlandPascalには選択肢があります。 たとえば、TEmployee および THourly オブジェクトは、内部データ フィールドに直接アクセスする必要がまったくないように記述されています。 type 従業員 = オブジェクト 名前、タイトル: string[25]; レート: レアル; プロシージャInit(AName、ATitle:string; ARate:Real); 関数GetName:文字列; 関数 GetTitle: 文字列; 関数 GetRate: 実数; 関数 GetPayAmount: 実数; 終わり THourly = オブジェクト(TEmployee) 時間: 整数。 プロシージャInit(AName、ATitle:string; ARate: Real、Atime: 整数); 関数 GetPayAmount: 実数; 終わり ここには、名前、タイトル、レート、時間の XNUMX つのデータ フィールドしかありません。 GetName メソッドと GetTitle メソッドは、それぞれ従業員の姓と役職を表示します。 GetPayAmount メソッドは Rate を使用し、稼働中の場合は THourly と Time を使用して稼働中への支払い額を計算します。 これらのデータ フィールドを直接参照する必要はなくなりました。 THourly 型の AnHourly インスタンスが存在すると仮定すると、一連のメソッドを使用して AnHourly のデータ フィールドを次のように操作できます。 時給付き 始まる 初期化 (アレクサンドル ペトロフ、フォーク リフト オペレーター' 12.95、62); {姓、役職、金額を表示 支払い} ショー; 終わり オブジェクトのフィールドへのアクセスは、このオブジェクトのメソッドを使用してのみ実行されることに注意してください。 35. オブジェクトの拡張 派生型が定義されている場合、親型のメソッドは継承されますが、必要に応じてオーバーライドできます。 継承されたメソッドをオーバーライドするには、継承されたメソッドと同じ名前で新しいメソッドを宣言するだけですが、本体と (必要に応じて) パラメーターのセットが異なります。 次の例で、時給が支払われる従業員を表す TEmployee の子型を定義しましょう。 定数 PayPeriods = 26; {支払い期間} 残業しきい値=80; {支払い期間中} OvertimeFactor = 1.5; { 時給 } type THourly = オブジェクト(TEmployee) 時間: 整数。 プロシージャInit(AName、ATitle:string; ARate: Real、Atime: 整数); 関数 GetPayAmount: 実数; 終わり プロシージャ THourly.Init(AName, ATitle: string; ARate: 実数、Atime: 整数); 始まる TEmployee.Init(AName, ATitle, ARate); 時間:= ATime; 終わり 関数 THourly.GetPayAmount: リアル; VAR 残業:整数; 始まる 残業:=時間-OvertimeThreshold; 残業>0の場合 GetPayAmount:= RoundPay(残業しきい値 * レート + RateOverTime * 残業係数 *レート) ほかに GetPayAmount:= RoundPay(時間*レート) 終わり オーバーライドされたメソッドを呼び出すときは、派生オブジェクト タイプに親の機能が含まれていることを確認する必要があります。 さらに、親メソッドを変更すると、すべての子メソッドが自動的に影響を受けます。 重要な注意: メソッドはオーバーライドできますが、データ フィールドはオーバーライドできません。 オブジェクト階層でデータ フィールドが定義されると、まったく同じ名前のデータ フィールドを子型で定義することはできません。 36. オブジェクトタイプの互換性 継承は、BorlandPascalの型互換性ルールをある程度変更します。 子孫は、そのすべての祖先の型互換性を継承します。 この拡張タイプの互換性には、次のXNUMXつの形式があります。 1) オブジェクトの実装間。 2)オブジェクト実装へのポインタ間。 3) 仮パラメータと実際のパラメータの間。 型の互換性は、子から親にのみ適用されます。 たとえば、TSalaried は TEmployee の子であり、TCommissioned は TSalaried の子です。 次の説明を考慮してください。 VAR AnEmployee: TEmployee; ASalaried:TSalaried; Pコミッショニング: Tコミッショニング; TEmployeePtr: ^T従業員; TSalariedPtr:^ TSalaried; TCommissionedPtr: ^TCommissioned; これらの説明では、次の代入演算子が有効です。 AnEmployee:=ASサラリード; A給与:= A委託; TCommissionedPtr:= ACommissioned; 一般に、タイプ互換性ルールは次のように定式化されます。ソースはレシーバーを完全に満たすことができなければなりません。 派生型には、継承のプロパティのために親型に含まれるすべてのものが含まれます。 したがって、派生型のサイズは親のサイズ以上です。 親オブジェクトを子オブジェクトに割り当てると、親オブジェクトの一部のフィールドが未定義のままになる可能性があります。これは危険であるため、違法です。 割り当てステートメントでは、両方のタイプに共通のフィールドのみがソースから宛先にコピーされます。 代入演算子の場合: AnEmployee:= ACommissioned; TCommissionedとTEmployeeの間で共有される唯一のフィールドであるため、ACommissionedのName、Title、およびRateフィールドのみがAnEmployeeにコピーされます。 型の互換性は、オブジェクト型へのポインタ間でも機能し、オブジェクトの実装と同じ一般的な規則に従います。 子へのポインタを親へのポインタに割り当てることができます。 前の定義を考えると、次のポインター割り当てが有効です。 TSalariedPtr:= TCommissionedPtr; TEmployeePtr:= TSalariedPtr; TEmployeePtr:= PCommissionedPtr; 特定のオブジェクト型の仮パラメーター (値または変数パラメーターのいずれか) は、その実パラメーターとして、それ自身の型のオブジェクトまたはすべての子型のオブジェクトを取ることができます。 次のようなプロシージャ ヘッダーを定義する場合: プロシージャCalcFedTax(Victim:TSalaried); この場合、実際のパラメータの型は TSalaried または TCommissioned にすることができますが、TEmployee にすることはできません。 Victim は可変パラメータにすることもできます。 この場合、同じ互換性ルールに従います。 値パラメーターは、パラメーターとして送信される実際のオブジェクトへのポインターであり、変数パラメーターは、実際のパラメーターのコピーです。 このコピーには、正式な値パラメーターのタイプの一部であるフィールドのみが含まれます。 これは、実パラメータが仮パラメータの型に変換されることを意味します。 37. アセンブラについて むかしむかし、アセンブラは、コンピューターに何かをさせることが不可能であることを知らずに言語でした。 徐々に状況が変わった。 コンピュータとのより便利な通信手段が登場しました。 しかし、他の言語とは異なり、アセンブラは死ぬことはなく、原則としてこれを行うことはできませんでした。 なんで? 答えを求めて、アセンブリ言語が一般的に何であるかを理解しようとします。 つまり、アセンブリ言語は機械語の記号表現です。 最下層のハードウェア レベルにあるマシンのすべてのプロセスは、マシン語のコマンド (命令) によってのみ駆動されます。 このことから、一般的な名前にもかかわらず、コンピューターの種類ごとにアセンブリ言語が異なることが明らかです。 これは、アセンブラで書かれたプログラムの外観、およびこの言語が反映しているアイデアにも当てはまります。 アセンブラの知識がなければ、ハードウェア関連の問題 (さらには、プログラムの高速化などのハードウェア関連の問題) を実際に解決することは不可能です。 プログラマーやその他のユーザーは、仮想世界を構築するためのプログラムまでの高水準ツールを使用できます。おそらく、コンピューターがプログラムが記述されている言語のコマンドではなく、変換された表現を実際に実行しているとは思わないでしょう。まったく異なる言語(機械語)の退屈で退屈なシーケンスコマンドの形で。 ここで、そのようなユーザーが非標準の問題を抱えていると想像してください。 たとえば、彼のプログラムは、いくつかの異常なデバイスで動作するか、コンピューターハードウェアの原理の知識を必要とする他のアクションを実行する必要があります。 プログラマーが自分のプログラムを書いた言語がどれほど優れていても、彼はアセンブラーを知らなければできません。 また、高級言語のほとんどすべてのコンパイラが、モジュールをアセンブラ内のモジュールに接続する手段を備えているか、アセンブラプログラミングレベルへのアクセスをサポートしているのは偶然ではありません。 コンピュータは複数の物理デバイスで構成されており、それぞれがシステムユニットと呼ばれる単一のユニットに接続されています。 38. マイクロプロセッサのソフトウェアモデル 今日のコンピューター市場には、多種多様な種類のコンピューターがあります。 したがって、消費者が質問をすることを想定することができます-コンピュータの特定のタイプ(またはモデル)の機能と他のタイプ(モデル)のコンピュータからのその独特の機能をどのように評価するか。 コンピュータのブロック図だけを考慮するだけでは、これには十分ではありません。これは、マシンごとに基本的にほとんど違いがないためです。すべてのコンピュータには、RAM、プロセッサ、および外部デバイスがあります。 コンピュータが単一のメカニズムとして機能するために使用される方法、手段、およびリソースは異なります。 機能的なプログラム制御の特性という点でコンピューターを特徴付けるすべての概念をまとめるために、コンピューター アーキテクチャという特別な用語があります。 コンピューター アーキテクチャの概念は、第 3 世代のコンピューターの登場により、比較評価のために初めて言及されるようになりました。 コンピュータのアセンブリ言語の学習を開始するのは、コンピュータのどの部分が表示され、この言語でのプログラミングに使用できるかを確認した後でないと意味がありません。 これは、いわゆるコンピュータ プログラム モデルであり、その一部はマイクロプロセッサ プログラム モデルであり、プログラマが多かれ少なかれ使用できる 32 個のレジスタが含まれています。 これらのレジスタは、次のXNUMXつの大きなグループに分けることができます。 1)16のユーザーレジスタ。 2)16個のシステムレジスタ。 アセンブリ言語プログラムはレジスタを非常に頻繁に使用します。 ほとんどのレジスタには特定の機能目的があります。 上記のレジスタに加えて、プロセッサ開発者は、特定のクラスの計算を最適化するように設計されたソフトウェアモデルに追加のレジスタを導入します。 そのため、IntelCorporationのPentiumPro(MMX)プロセッサファミリでは、IntelのMMX拡張機能が導入されました。 8(MM0-MM7)64ビットレジスタが含まれており、いくつかの新しいデータ型のペアに対して整数演算を実行できます。 1) パックされた XNUMX バイト。 2)XNUMXつのパックされた単語。 3) XNUMX つのダブルワード。 4) 四重語; 言い換えると、単一のMMX拡張命令で、プログラマーは、たとえば、0つのダブルワードを一緒に追加できます。 物理的には、新しいレジスタは追加されていません。 MM7〜MM64は、80ビットFPU(浮動小数点ユニット-コプロセッサー)レジスターのスタックの仮数(下位XNUMXビット)です。 さらに、現時点では、プログラミングモデルの次の拡張機能があります-3DNOW! AMDから; SSE、SSE2、SSE3、SSE4。 最後の4つの拡張機能は、AMDプロセッサとIntelプロセッサの両方でサポートされています。 39. ユーザー登録 名前が示すように、プログラマーがプログラムを作成するときにユーザーレジスターを使用できるため、ユーザーレジスターが呼び出されます。 これらのレジスタには次のものが含まれます。 1) プログラマがデータとアドレスを格納するために使用できる 32 つの XNUMX ビット レジスタ (汎用レジスタ (RON) とも呼ばれます): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl。 ▪ ecx/cx/ch/cl; ▪ ebp/bp。 ▪esi/si; ▪ エディ/ディ。 ▪ 特に/sp。 2) XNUMX つのセグメントレジスタ: ▪ cs; ▪ DS; ▪ ss; ▪ エス; ▪ fs; ▪ gs; 3) ステータスおよび制御レジスタ: ▪ flags は eflags/flags を登録します。 ▪ コマンド ポインタは eip/ip を登録します。 次の図は、マイクロプロセッサのメインレジスタを示しています。 汎用レジスタ
40.一般的なレジスタ このグループのすべてのレジスタを使用すると、「下位」部分にアクセスできます。 セルフアドレッシングに使用できるのは、これらのレジスタの下位16ビットおよび8ビット部分のみです。 これらのレジスタの上位16ビットは、独立したオブジェクトとして使用できません。 汎用レジスタのグループに属するレジスタをリストしてみましょう。 これらのレジスタは、算術論理演算装置(ALU)内のマイクロプロセッサに物理的に配置されているため、ALUレジスタとも呼ばれます。 1)eax / ax / ah / al(アキュムレータレジスタ)-バッテリ。 中間データを格納するために使用されます。 一部のコマンドでは、このレジスタの使用が必要です。 2)ebx / bx / bh / bl(ベースレジスタ)-ベースレジスタ。 オブジェクトのベースアドレスをメモリに格納するために使用されます。 3) ecx/cx/ch/cl (カウント レジスタ) - カウンタ レジスタ。 これは、いくつかの反復アクションを実行するコマンドで使用されます。 多くの場合、その使用は暗黙的であり、対応するコマンドのアルゴリズムに隠されています。 たとえば、ループ構成コマンドは、特定のアドレスにあるコマンドに制御を移すだけでなく、ecx/cx レジスタの値を分析して XNUMX つ減らします。 4) edx/dx/dh/dl (データレジスタ) - データレジスタ。 eax/ax/ah/al レジスタと同様に、中間データを格納します。 一部のコマンドには、その使用が必要です。 一部のコマンドでは、これは暗黙的に発生します。 次の 32 つのレジスタは、いわゆるチェーン操作、つまり要素のチェーンを順次処理する操作をサポートするために使用されます。各要素のチェーンは 16、8、または XNUMX ビット長にすることができます。 1) esi/si (ソース インデックス レジスタ) - ソース インデックス。 チェーン操作のこのレジスタには、ソース チェーン内の要素の現在のアドレスが含まれます。 2)edi / di(宛先インデックスレジスタ)-受信者(受信者)のインデックス。 チェーン操作のこのレジスタには、宛先チェーンの現在のアドレスが含まれています。 ハードウェアおよびソフトウェアレベルのマイクロプロセッサのアーキテクチャでは、スタックなどのデータ構造がサポートされています。 マイクロプロセッサ命令システムのスタックを操作するために、特別なコマンドがあり、マイクロプロセッサソフトウェアモデルには、このための特別なレジスタがあります。 1) esp/sp (スタック ポインター レジスター) - スタック ポインター レジスター。 現在のスタック セグメントのスタックの先頭へのポインターが含まれます。 2)ebp / bp(ベースポインタレジスタ)-スタックフレームベースポインタレジスタ。 スタック内のデータへのランダムアクセスを整理するように設計されています。 一部の命令でレジスタのハード ピニングを使用すると、それらのマシン表現をよりコンパクトにエンコードできます。 これらの機能を知っていれば、必要に応じて、プログラム コードが占有するメモリを少なくとも数バイト節約できます。 41. セグメントレジスタ マイクロプロセッサ ソフトウェア モデルには、cs、ss、ds、es、gs、fs の XNUMX つのセグメント レジスタがあります。 それらの存在は、組織の詳細とIntelマイクロプロセッサによるRAMの使用によるものです。 これは、マイクロプロセッサハードウェアが、セグメントと呼ばれるXNUMXつの部分の形でプログラムの構造的編成をサポートしているという事実にあります。 したがって、このようなメモリの編成はセグメント化と呼ばれます。 特定の時点でプログラムがアクセスできるセグメントを示すために、セグメントレジスタが意図されています。 実際、(若干の修正はありますが) これらのレジスタには、対応するセグメントが始まるメモリ アドレスが含まれています。 マシン命令を処理するロジックは、命令をフェッチするとき、プログラム データにアクセスするとき、またはスタックにアクセスするときに、明確に定義されたセグメント レジスタ内のアドレスが暗黙的に使用されるように構築されます。 マイクロプロセッサは、次のタイプのセグメントをサポートしています。 1. コード セグメント。 プログラム コマンドが含まれます。 このセグメントにアクセスするには、cs レジスタ (コード セグメント レジスタ) - セグメント コード レジスタが使用されます。 これには、マイクロプロセッサがアクセスできるマシン命令セグメントのアドレスが含まれています (つまり、これらの命令はマイクロプロセッサ パイプラインにロードされます)。 2. データ セグメント。 プログラムによって処理されたデータが含まれます。 このセグメントにアクセスするには、ds レジスタ (データ セグメント レジスタ) が使用されます。これは、現在のプログラムのデータ セグメントのアドレスを格納するセグメント データ レジスタです。 3.スタックセグメント。 このセグメントは、スタックと呼ばれるメモリの領域です。 マイクロプロセッサは、次の原則に従ってスタックでの作業を編成します。この領域に書き込まれた最後の要素が最初に選択されます。 このセグメントにアクセスするには、ssレジスタ(スタックセグメントレジスタ)を使用します。これは、スタックセグメントのアドレスを含むスタックセグメントレジスタです。 4. 追加のデータ セグメント。 ほとんどのマシン命令を実行するためのアルゴリズムは、処理するデータがデータ セグメントにあり、そのアドレスが ds セグメント レジスタにあることを暗に想定しています。 XNUMX つのデータ セグメントがプログラムに十分でない場合、さらに XNUMX つの追加のデータ セグメントを使用する機会があります。 ただし、アドレスが ds セグメント レジスタに含まれるメイン データ セグメントとは異なり、追加のデータ セグメントを使用する場合は、コマンドで特別なセグメント再定義プレフィックスを使用して、それらのアドレスを明示的に指定する必要があります。 追加のデータ セグメントのアドレスは、レジスタ es、gs、fs (拡張データ セグメント レジスタ) に含まれている必要があります。 42. ステータスおよび制御レジスタ マイクロプロセッサには、マイクロプロセッサ自体と、現在パイプラインに命令がロードされているプログラムの両方の状態に関する情報を常に含むいくつかのレジスタが含まれています。 これらのレジスタには次のものがあります。 1) フラグレジスタ eflags/flags; 2) eip/ip コマンド ポインタ レジスタ。 これらのレジスタを使用して、コマンド実行の結果に関する情報を取得し、マイクロプロセッサ自体の状態に影響を与えることができます。 これらのレジスタの目的と内容をさらに詳しく考えてみましょう。 1. eflags / flags(フラグレジスタ)-フラグレジスタ。 eflags/flagsのビット深度は32/16ビットです。 このレジスタの個々のビットには特定の機能目的があり、フラグと呼ばれます。 このレジスタの下部は、i8086のフラグレジスタに完全に類似しています。 eflags/flags レジスタのフラグは、使用方法に応じて XNUMX つのグループに分けられます。 1)XNUMXつのステータスフラグ。 これらのフラグは、マシン命令が実行された後に変更される場合があります。 eflags レジスタのステータス フラグは、算術演算または論理演算の実行結果の詳細を反映します。 これにより、計算プロセスの状態を分析し、条件付きジャンプ コマンドとサブルーチン呼び出しを使用して応答することができます。 2) XNUMX つの制御フラグ。 df(ディレクトリフラグ)を示します。 これはeflagsレジスタのビット10にあり、連鎖コマンドによって使用されます。 dfフラグの値は、これらの操作での要素ごとの処理の方向を決定します。文字列の最初から最後まで(df = 0)、またはその逆、文字列の最後から最初まで(df = 1)。 dfフラグを操作するための特別なコマンドがあります:cld(dfフラグを削除する)およびstd(dfフラグを設定する)。 これらのコマンドを使用すると、アルゴリズムに従って df フラグを調整し、文字列に対して操作を実行するときにカウンターが自動的に増分または減分されるようにすることができます。 3) XNUMX つのシステム フラグ。 I/O、マスカブル割り込み、デバッグ、タスク切り替え、および 8086 仮想モードを制御します. アプリケーション プログラムがこれらのフラグを不必要に変更することはお勧めできません. 2. eip/ip (命令ポインタ レジスタ) - 命令ポインタ レジスタ。 eip/ip レジスタは 32/16 ビット幅で、現在の命令セグメントの cs セグメント レジスタの内容に関連して実行される次の命令のオフセットが含まれています。 プログラマーはこのレジスターに直接アクセスできませんが、その値はさまざまな制御コマンドによってロードおよび変更されます。これには、条件付きおよび無条件のジャンプ、プロシージャーの呼び出し、およびプロシージャーからの復帰のためのコマンドが含まれます。 割り込みが発生すると、eip/ip レジスタも変更されます。 43.マイクロプロセッサシステムレジスタ これらのレジスタの名前は、システム内で特定の機能を実行することを示唆しています。 システム レジスタの使用は厳密に規制されています。 プロテクトモードを提供するのは彼らです。 これらは、資格のあるシステム プログラマが最も低レベルの操作を実行できるように、意図的に可視化されたマイクロプロセッサ アーキテクチャの一部と考えることができます。 システムレジスタは、次のXNUMXつのグループに分けることができます。 1)XNUMXつの制御レジスタ。 制御レジスタのグループには、次の 4 つのレジスタが含まれます。 ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) XNUMX つのシステム アドレス レジスタ (メモリ管理レジスタとも呼ばれる)。 システム アドレス レジスタには、次のレジスタが含まれます。 ▪ グローバル記述子テーブル レジスタ gdtr。 ▪ ローカル記述子テーブル Idtr のレジスタ。 ▪ 割り込み記述子テーブル レジスタ idtr; ▪ 16 ビットタスクレジスタ tr; 3) XNUMX つのデバッグ レジスタ。 これらには以下が含まれます: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7。 システム レジスタは主に最も低レベルの操作に使用されるため、アセンブラでプログラムを記述するのにシステム レジスタの知識は必要ありません。 ただし、ソフトウェア開発の現在の傾向 (特に、人間のコードよりも効率的に優れたコードを生成することが多い高級言語の最新のコンパイラーの最適化機能が大幅に向上していることを考慮して) は、アセンブラーの範囲を最も低い問題を解決するように狭めています。 -レベルの問題。上記のレジスタの知識が非常に役立つことが判明する可能性があります。 44. 制御レジスタ 制御レジスタのグループには、cr0、cr1、cr2、cr3の0つのレジスタが含まれます。 これらのレジスタは、一般的なシステム制御用です。 制御レジスタは、特権レベルXNUMXのプログラムでのみ使用できます。 マイクロプロセッサには1つの制御レジスタがありますが、使用できるのはXNUMXつだけです。crXNUMXは除外されており、その機能はまだ定義されていません(将来の使用のために予約されています)。 cr0 レジスタには、実行中の特定のタスクに関係なく、マイクロプロセッサの動作モードを制御し、その状態をグローバルに反映するシステム フラグが含まれています。 システム フラグの目的: 1) pe (保護の有効化)、ビット 0 - 保護モードを有効にします。 このフラグの状態は、0 つのモード (リアル (pe = 1) または保護 (pe = XNUMX)) のどちらでマイクロプロセッサが特定の時間に動作しているかを示します。 2) mp (Math Present)、ビット 1 - コプロセッサーの存在。 常に 1。 3) ts (タスク切り替え)、ビット 3 - タスク切り替え。 プロセッサは、別のタスクに切り替えると、このビットを自動的に設定します。 4) am (アライメント マスク)、ビット 18 - アライメント マスク。 このビットは、アライメント制御を有効(am = 1)または無効(am = 0)にします。 5)cd(キャッシュ無効化)、ビット30-キャッシュメモリを無効化します。 このビットを使用して、内部キャッシュ (第 1 レベルのキャッシュ) の使用を無効 (cd = 0) または有効 (cd = XNUMX) にすることができます。 6)pg(PaGing)、ビット31-ページングを有効(pg = 1)または無効(pg = 0)にします。 このフラグは、メモリ編成のページングモデルで使用されます。 cr2 レジスターは RAM ページングで使用され、現在の命令が現在メモリー内にないメモリー・ページに含まれるアドレスにアクセスしたときの状況を登録します。 このような状況では、マイクロプロセッサで例外番号 14 が発生し、この例外を引き起こした命令のリニア 32 ビット アドレスがレジスタ cr2 に書き込まれます。 この情報により、例外ハンドラ14は、所望のページを決定し、それをメモリにスワップし、プログラムの通常の動作を再開する。 cr3レジスタは、メモリのページングにも使用されます。 これは、いわゆる第20レベルのページディレクトリレジスタです。 これには、現在のタスクのページディレクトリの1024ビットの物理ベースアドレスが含まれています。 このディレクトリには、32個の1024ビット記述子が含まれています。各記述子には、第32レベルのページテーブルのアドレスが含まれています。 次に、各第4レベルのページテーブルには、メモリ内のページフレームをアドレス指定するXNUMX個のXNUMXビット記述子が含まれています。 ページフレームサイズはXNUMXKBです。 45. システムアドレスのレジスタ これらのレジスタは、メモリ管理レジスタとも呼ばれます。 これらは、マイクロプロセッサのマルチタスク モードでプログラムとデータを保護するように設計されています。 マイクロプロセッサ保護モードで動作している場合、アドレス空間は次のように分割されます。 1) グローバル - すべてのタスクに共通。 2) ローカル - タスクごとに個別。 この分離により、マイクロプロセッサ アーキテクチャに次のシステム レジスタが存在することが説明されます。 1) グローバル記述子テーブル gdtr (Global Descriptor Table Register) のレジスタ。サイズは 48 ビットで、グローバル記述子テーブル GDT の 32 ビット (ビット 16 ~ 47) のベースアドレスと 16 ビット (ビット0-15) GDT テーブルのバイト単位のサイズである制限値。 2)16ビットのサイズを有し、ローカル記述子テーブルLDTのいわゆる記述子セレクタを含む、ローカル記述子テーブルレジスタldtr(ローカル記述子テーブルレジスタ)。 このセレクターは、ローカル記述子テーブル LDT を含むセグメントを記述する GDT へのポインターです。 3)48ビットのサイズを持ち、IDT割り込み記述子テーブルの32ビット(ビット16-47)のベースアドレスと16ビット(ビット)を含む割り込み記述子テーブルidtr(割り込み記述子テーブルレジスタ)のレジスタ0-15)IDTテーブルのバイト単位のサイズである制限値。 4)16ビットタスクレジスタtr(タスクレジスタ)。これは、ldtrレジスタと同様に、セレクタ、つまりGDTテーブル内の記述子へのポインタを含みます。 この記述子は、現在のタスクセグメントステータス(TSS)を記述します。 このセグメントは、システム内のタスクごとに作成され、厳密に規制された構造を持ち、タスクのコンテキスト(現在の状態)を含みます。 TSSセグメントの主な目的は、別のタスクに切り替えたときのタスクの現在の状態を保存することです。 46.デバッグレジスタ これは、ハードウェアのデバッグを目的とした非常に興味深いレジスタのグループです。 ハードウェアデバッグツールは、i486マイクロプロセッサで最初に登場しました。 ハードウェアでは、マイクロプロセッサにはXNUMXつのデバッグレジスタが含まれていますが、実際に使用されるのはそのうちのXNUMXつだけです。 レジスタ dr0、dr1、dr2、dr3 は 32 ビット幅を持ち、0 つのブレークポイントのリニア アドレスを設定するように設計されています。この場合に使用されるメカニズムは次のとおりです。現在のプログラムによって生成されたアドレスがレジスタ dr3 ~ dr1 のアドレスと比較され、一致する場合は番号 XNUMX のデバッグ例外が生成されます。 レジスタ dr6 は、デバッグ ステータス レジスタと呼ばれます。 このレジスタのビットは、最後の例外番号 1 が発生した理由に従って設定されます。 これらのビットとその目的をリストします。 1) b0 - このビットが 1 に設定されている場合、最後の例外 (割り込み) は、レジスタ dr0 で定義されたチェックポイントに到達した結果として発生しました。 2)b1-b0と同様ですが、レジスタdr1のチェックポイント用です。 3)b2-b0と同様ですが、レジスタdr2のチェックポイント用です。 4)b3-b0と同様ですが、レジスタdr3のチェックポイント用です。 5) bd (ビット 13) - デバッグ レジスタを保護します。 6) bs (ビット 14) - eflags レジスタのフラグ tf = 1 の状態によって例外 1 が発生した場合、1 に設定されます。 7) TSS t = 15 に設定されたトラップ ビットを持つタスクへの切り替えによって例外 1 が発生した場合、bt (ビット 1) は 1 に設定されます。このレジスタの他のビットはすべて 1 で埋められます。例外ハンドラ 6 は、drXNUMX の内容に基づいて、例外が発生した理由を判断し、必要なアクションを実行する必要があります。 レジスタ dr7 は、デバッグ制御レジスタと呼ばれます。 これには、割り込みを生成する次の条件を指定できる XNUMX つのデバッグ ブレークポイント レジスタのそれぞれのフィールドが含まれています。 1) チェックポイント登録場所 - 現在のタスクまたは任意のタスクのみ。 これらのビットは、レジスタ dr8 の下位 7 ビットを占有します (レジスタ dr2、drl、dr0、dr2 によってそれぞれ設定されるブレークポイント (実際にはブレークポイント) ごとに 3 ビット)。 各ペアの最初のビットは、いわゆるローカル解像度です。 設定すると、現在のタスクのアドレス空間内にある場合にブレークポイントが有効になります。 各ペアの XNUMX 番目のビットは、グローバル許可を定義します。これは、指定されたブレークポイントが、システムに存在するすべてのタスクのアドレス空間内で有効であることを示します。 2) 割り込みが開始されるアクセスのタイプ: コマンドのフェッチ時、書き込み時、またはデータの書き込み/読み取り時のみ。 割り込みの発生のこの性質を決定するビットは、このレジスタの上部に配置されています。 システム レジスタのほとんどは、プログラムでアクセスできます。 47. アセンブラでのプログラムの構造 アセンブリ言語プログラムは、メモリ セグメントと呼ばれるメモリ ブロックの集まりです。 プログラムは、これらのブロックセグメントの XNUMX つまたは複数で構成されます。 各セグメントには言語センテンスのコレクションが含まれており、各センテンスはプログラム コードの個別の行を占めています。 アセンブリステートメントには XNUMX つのタイプがあります。 機械語命令のシンボリック版であるコマンドまたは命令。 変換プロセス中に、アセンブリ命令はマイクロプロセッサ命令セットの対応するコマンドに変換されます。 原則として、XNUMX つのアセンブラ命令は XNUMX つのマイクロプロセッサ命令に対応します。これは、一般的に言えば、低レベル言語で一般的です。 以下は、eax レジスタに格納されている XNUMX 進数を XNUMX ずつインクリメントする命令の例です。 インクルーシブ ▪ マクロ コマンド - 特定の方法でフォーマットされた番組テキストの文。放送中に他の文に置き換えられます。 マクロの例は、次のプログラム終了マクロです。 終了マクロ movax,4c00h int 21h エンドム ▪ ディレクティブ。これは、アセンブラ トランスレータに特定のアクションを実行するための命令です。 ディレクティブには、マシン表現に対応するものはありません。 例として、リスト ファイルのタイトルを設定する TITLE ディレクティブを次に示します。 %TITLE "Listing 1" ▪ ロシア語のアルファベットを含む任意の文字を含むコメント行。コメントは翻訳者によって無視されます。例: ; この行はコメントです 48.アセンブリ構文 プログラムを構成する文は、コマンド、マクロ、ディレクティブ、またはコメントに対応する構文構造にすることができます。 アセンブラトランスレータがそれらを認識するためには、特定の構文規則に従ってそれらを形成する必要があります。 これを行うには、文法の規則のように、言語の構文の正式な説明を使用するのが最善です。 この方法でプログラミング言語を記述する最も一般的な方法は、シンタックスダイアグラムと拡張バッカスナウア記法です。 シンタックスダイアグラムを操作するときは、矢印で示されているトラバースの方向に注意してください。 シンタックスダイアグラムは、プログラムの入力文を解析するときの翻訳者のロジックを反映しています。 有効な文字: 1) すべてのラテン文字: A - Z、a - z; 2) 0 から 9 までの数字。 3) サイン? @、$、&; 4)セパレーター。 トークンは次のとおりです。 1.識別子-操作コード、変数名、およびラベル名を指定するために使用される有効な文字のシーケンス。 識別子を数字で始めることはできません。 2. 文字の連鎖 - 一重引用符または二重引用符で囲まれた一連の文字。 3.整数。 アセンブラステートメントの可能なタイプ。 1. 算術演算子。 これらには以下が含まれます: 1) 単項 "+" および "-"; 2) バイナリ "+" および "-"; 3) 乗算 "*"; 4) 整数除算 "/"; 5) 除算「mod」の余りを取得します。 2.シフト演算子は、指定されたビット数だけ式をシフトします。 3.比較演算子(「true」または「false」を返す)は、論理式を形成するように設計されています。 4.論理演算子は、式に対してビット単位の演算を実行します。 5. インデックス演算子 []。 6. ptr 型再定義演算子は、式によって定義されたラベルまたは変数の型を再定義または修飾するために使用されます。 7.セグメント再定義演算子「:」(コロン)を使用すると、指定したセグメントコンポーネントを基準にして物理アドレスが計算されます。 8. 構造体型命名演算子「.」 (ドット) が式の中にある場合、コンパイラは特定の計算を実行します。 9. 式 seg のアドレスのセグメント コンポーネントを取得する演算子は、式のセグメントの物理アドレスを返します。これは、ラベル、変数、セグメント名、グループ名、または何らかの記号名です。 10.式オフセットのオフセットを取得するための演算子を使用すると、式が定義されているセグメントの先頭を基準にした式のオフセットの値をバイト単位で取得できます。 49.セグメンテーションディレクティブ セグメンテーションは、モジュラー プログラミングの概念に関連する、より一般的なメカニズムの一部です。 これには、さまざまなプログラミング言語からのものを含め、コンパイラによって作成されたオブジェクト モジュールの設計の統一が含まれます。 これにより、異なる言語で書かれたプログラムを組み合わせることができます。 SEGMENT ディレクティブのオペランドが意図されているのは、そのようなユニオンのさまざまなオプションを実装するためです。 それらをより詳細に検討してください。 1.セグメントアラインメント属性(アラインメントタイプ)は、セグメントの先頭が指定された境界に配置されるようにリンカーに指示します。 1)BYTE-位置合わせは実行されません。 2) WORD - セグメントは 0 の倍数のアドレスで開始します。つまり、物理アドレスの最後の (最下位) ビットは XNUMX (ワード境界に整列) です。 3) DWORD - セグメントは XNUMX の倍数のアドレスで始まります。 4)PARA-セグメントは16の倍数のアドレスで始まります。 5) PAGE - セグメントは、256 の倍数であるアドレスで始まります。 6) MEMPAGE - セグメントは、4 KB の倍数であるアドレスで始まります。 2. 結合セグメント属性 (結合型) は、同じ名前を持つ異なるモジュールのセグメントを結合する方法をリンカに指示します。 1)PRIVATE-セグメントは、このモジュールの外部で同じ名前の他のセグメントとマージされません。 2) PUBLIC - すべてのセグメントを同じ名前で接続するようリンカーに強制します。 3)COMMON-同じアドレスに同じ名前のすべてのセグメントがあります。 4)ATxxxx-段落の絶対アドレスにセグメントを配置します。 5) STACK - スタック セグメントの定義。 3. セグメント クラス属性 (クラス タイプ) は、複数のモジュール セグメントからプログラムをアセンブルするときに、リンカが適切なセグメントの順序を決定するのに役立つ引用符付きの文字列です。 4. セグメント サイズ属性: 1) USE16 - これは、セグメントが 16 ビットのアドレス指定を許可することを意味します。 2)USE32-セグメントは32ビットになります。 不可能を補うための何らかの方法が必要です。 セグメントの配置と組み合わせを直接制御します。 これを行うために、彼らは MODEL メモリ モデルを指定するディレクティブを使用し始めました。 このディレクティブは、単純化されたセグメンテーション ディレクティブを使用する場合、定義済みの名前を持つセグメントをセグメント レジスタにバインドします (ただし、明示的に ds を初期化する必要があります)。 MODEL ディレクティブの必須パラメータはメモリ モデルです。 このパラメータは、POU のメモリ セグメンテーション モデルを定義します。 プログラムモジュールは、前述の単純化されたセグメント記述ディレクティブによって定義される特定のタイプのセグメントのみを持つことができると想定されています。 50. 機械命令構造 マシンコマンドは、特定の規則に従ってエンコードされたマイクロプロセッサへの指示であり、何らかの操作またはアクションを実行します。 各コマンドには、次を定義する要素が含まれています。 1)何をしますか? 2) 何かを行う必要があるオブジェクト (これらの要素はオペランドと呼ばれます); 3) どうやって? 機械語命令の最大長は 15 バイトです。 1. プレフィックス。 オプションの機械命令要素。各要素は1バイトであるか、省略できます。 メモリでは、プレフィックスがコマンドの前にあります。 プレフィックスの目的は、コマンドによって実行される操作を変更することです。 アプリケーションは、次のタイプのプレフィックスを使用できます。 1) セグメント置換プレフィックス。 2) アドレス ビット長プレフィックスは、アドレスのビット長 (32 ビットまたは 16 ビット) を指定します。 3) オペランドのビット長のプレフィックスは、アドレスのビット長のプレフィックスと似ていますが、コマンドが動作するオペランドのビット長 (32 ビットまたは 16 ビット) を示します。 4)繰り返しプレフィックスは連鎖コマンドで使用されます。 2. 操作コード。 コマンドによって実行される操作を説明する必須要素。 3. アドレッシング モード バイト modr/m。 このバイトの値によって、使用されるオペランドアドレス形式が決まります。 オペランドは、XNUMXつまたはXNUMXつのレジスタのメモリに置くことができます。 オペランドがメモリ内にある場合、modr / mバイトはコンポーネント(オフセット、ベース、およびインデックスレジスタ)を指定します。 実効アドレスの計算に使用されます。 modr / mバイトは、次のXNUMXつのフィールドで構成されます。 1) mod フィールドは、オペランドのアドレスによって命令で占有されるバイト数を決定します。 2) reg/cop フィールドは、最初のオペランドの代わりにコマンドに配置されたレジスタ、またはオペコードの可能な拡張のいずれかを決定します。 3)r / mフィールドはmodフィールドと組み合わせて使用され、コマンドの第11オペランドの場所にあるレジスタ(mod = XNUMXの場合)、または実効アドレスの計算に使用されるベースレジスタとインデックスレジスタのいずれかを決定します。 (コマンドのオフセットフィールドと一緒に)。 4.バイトスケール-インデックス-ベース(バイトシブ)。 オペランドのアドレス指定の可能性を拡張するために使用されます。 sibバイトは、次のXNUMXつのフィールドで構成されます。 1) スケール フィールド ss。 このフィールドには、sib バイトの次の 3 ビットを占めるインデックス コンポーネント インデックスのスケール ファクタが含まれます。 2) インデックス フィールド。 オペランドの実効アドレスの計算に使用されるインデックス レジスタ番号を格納するために使用されます。 3)ベースフィールド。 ベースレジスタ番号を格納するために使用されます。これは、オペランドの実効アドレスの計算にも使用されます。 5.コマンドのオフセットフィールド。 オペランドの実効アドレスの値の全部または一部(上記の考慮事項に従う)を表す8、16、または32ビットの符号付き整数。 6. 即値オペランドのフィールド。 8-, を表すオプションのフィールド 16 ビットまたは 32 ビットの即値オペランド。 もちろん、このフィールドの存在は modr/m バイトの値に反映されます。 51. 命令オペランドの指定方法 オペランドはファームウェアレベルで暗黙的に設定されます この場合、命令には明示的にオペランドが含まれていません。 コマンド実行アルゴリズムは、いくつかのデフォルトオブジェクト(レジスタ、eflagsのフラグなど)を使用します。 命令自体にオペランドを指定する(即値オペランド) オペランドは命令コード内にあります。つまり、命令コードの一部です。 このようなオペランドを格納するために、最大 32 ビット長のフィールドが命令に割り当てられます。 即値オペランドは、XNUMX 番目の (ソース) オペランドのみにすることができます。 デスティネーション オペランドは、メモリ内またはレジスタ内のいずれかになります。 オペランドはレジスタの XNUMX つにあり、レジスタ オペランドはレジスタ名で指定されます。 レジスタは次のように使用できます。 1) 32 ビット レジスタ EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP。 2) 16 ビットレジスタ AX、BX、CX、DX、SI、DI、SP、BP。 3) 8 ビットレジスタ AH、AL、BH、BL、CH、CL、DH、 DL; 4) セグメント レジスタ CS、DS、SS、ES、FS、GS。 たとえば、コマンド add ax,bx は、レジスタ ax と bx の内容を加算し、結果を bx に書き込みます。 dec si コマンドは、si の内容を 1 減らします。 オペランドはメモリ内にあります これは最も複雑であると同時に、オペランドを指定する最も柔軟な方法です。 これにより、次の XNUMX つの主なタイプのアドレス指定を実装できます: 直接および間接。 次に、間接アドレッシングには次の種類があります。 1) 間接ベースアドレッシング。 他の名前はレジスタ間接アドレッシングです。 2)オフセットを使用した間接ベースアドレス指定。 3)オフセットを使用した間接インデックスアドレス指定。 4)間接ベースインデックスアドレス指定。 5)オフセットを使用した間接ベースインデックスアドレス指定。 オペランドはI/Oポートです マイクロプロセッサは、RAMアドレス空間に加えて、I/Oデバイスへのアクセスに使用されるI/Oアドレス空間を維持します。 I/Oアドレス空間は64KBです。 アドレスは、このスペース内の任意のコンピューターデバイスに割り当てられます。 このスペース内の特定のアドレス値は、I/Oポートと呼ばれます。 物理的には、I / Oポートはハードウェアレジスタ(マイクロプロセッサレジスタと混同しないでください)に対応し、特別なアセンブラ命令を使用してアクセスされます。 オペランドはスタックにあります 命令にはオペランドがまったくない場合もあれば、XNUMX つまたは XNUMX つのオペランドがある場合もあります。 ほとんどの命令は XNUMX つのオペランドを必要とし、そのうちの XNUMX つはソース オペランドで、もう XNUMX つはデスティネーション オペランドです。 XNUMX つのオペランドをレジスタまたはメモリに配置できることが重要であり、XNUMX 番目のオペランドはレジスタまたは直接命令に配置する必要があります。 即値オペランドは、ソース オペランドのみにすることができます。 XNUMX オペランドの機械語命令では、次のオペランドの組み合わせが可能です。 1) 登録 - 登録; 2)レジスタ-メモリ; 3)メモリ-レジスタ; 4)即値オペランド-レジスタ; 5) 即値オペランド - メモリ。 52.アドレス指定方法 直接アドレッシング これは、メモリ内のオペランドをアドレス指定する最も単純な形式です。これは、実効アドレスが命令自体に含まれており、それを形成するために追加のソースやレジスタが使用されていないためです。 実効アドレスは、8、16、32 ビットのマシン命令オフセット フィールドから直接取得されます。 この値は、データ セグメントにあるバイト、ワード、またはダブル ワードを一意に識別します。 直接アドレッシングには XNUMX つのタイプがあります。 相対的な直接アドレス指定 相対ジャンプアドレスを示す条件付きジャンプ命令に使用されます。 このような遷移の相対性は、マシン命令のオフセットフィールドに8、16、または32ビットの値が含まれているという事実にあります。これらの値は、命令の操作の結果として、の内容に追加されます。 ip/eip命令ポインタレジスタ。 この追加の結果として、遷移が実行されるアドレスが取得されます。 絶対直接アドレス指定 この場合、実効アドレスは機械命令の一部ですが、このアドレスは命令のオフセットフィールドの値からのみ形成されます。 メモリ内のオペランドの物理アドレスを形成するために、マイクロプロセッサはこのフィールドにセグメントレジスタの値を4ビットシフトして追加します。 このアドレス指定のいくつかの形式は、アセンブラ命令で使用できます。 間接基本 (レジスタ) アドレッシング このアドレッシングでは、オペランドの実効アドレスは、sp / esp および bp / ebp を除く汎用レジスタのいずれかに置くことができます (これらは、スタック セグメントを操作するための特定のレジスタです)。 コマンドの構文では、このアドレッシング モードは、レジスタ名を角括弧 [] で囲むことによって表されます。 オフセットによる間接ベース (レジスタ) アドレッシング このタイプのアドレッシングは、以前のものに追加されたもので、ベース アドレスに対する既知のオフセットでデータにアクセスするように設計されています。 このタイプのアドレッシングは、プログラム開発の段階で要素のオフセットが事前にわかっていて、構造体のベース (開始) アドレスを動的に計算する必要がある場合に、データ構造体の要素にアクセスするために使用すると便利です。プログラム実行の段階。 オフセットによる間接インデックス アドレッシング この種のアドレッシングは、オフセットを使用した間接ベース アドレッシングに非常に似ています。 ここでも、汎用レジスタの XNUMX つを使用して実効アドレスを形成します。 しかし、インデックス アドレス指定には、配列を操作するのに非常に便利な興味深い機能が XNUMX つあります。 これは、インデックスレジスタの内容のいわゆるスケーリングの可能性に関連しています。 間接ベース インデックス アドレッシング このタイプのアドレス指定では、実効アドレスは、ベースとインデックスのXNUMXつの汎用レジスタの内容の合計として形成されます。 これらのレジスタは任意の汎用レジスタにすることができ、インデックスレジスタの内容のスケーリングがよく使用されます。 オフセットを使用した間接ベースインデックスアドレス指定 この種のアドレス指定は、間接的なインデックス付きアドレス指定を補完するものです。 実効アドレスは、ベースレジスタの内容、インデックスレジスタの内容、および命令のオフセットフィールドの値のXNUMXつのコンポーネントの合計として形成されます。 53. データ転送コマンド 一般的なデータ転送コマンド このグループには、次のコマンドが含まれます。 1) mov はメインのデータ転送コマンドです。 2) xchg - 双方向データ転送に使用されます。 ポートI/Oコマンド 基本的に、ポートを介してデバイスを直接管理するのは簡単です。 1) アキュムレータでは、ポート番号 - ポート番号を持つポートからアキュムレータへの入力。 2) out port, accumulator - アキュムレータの内容をポート番号のポートに出力します。 データ変換コマンド 多くのマイクロプロセッサ命令はこのグループに属していますが、それらのほとんどには、他の機能グループに属している必要がある特定の機能があります。 スタック コマンド このグループは、スタックを使用した柔軟で効率的な作業の整理に焦点を当てた一連の特殊なコマンドです。 スタックは、プログラム データの一時的な保存用に特別に割り当てられたメモリ領域です。 スタックには XNUMX つのレジスタがあります。 1)ss-スタックセグメントレジスタ。 2) sp/esp - スタック ポインタ レジスタ。 3) bp/ebp - スタック フレーム ベース ポインタ レジスタ。 スタックでの作業を整理するために、書き込みと読み取り用の特別なコマンドがあります。 1. ソースのプッシュ - ソース値をスタックの先頭に書き込みます。 2. pop 代入 - スタックの一番上から宛先オペランドで指定された位置に値を書き込みます。 したがって、値はスタックの一番上から「削除」されます。 3. pusha - スタックへのグループ書き込みコマンド。 4. pushaw は pusha コマンドとほぼ同義です。 ビット属性は、use16 または use32 のいずれかです。 R 5. pushad-pushaコマンドと同様に実行されますが、いくつかの特性があります。 次のXNUMXつのコマンドは、上記のコマンドの逆を実行します。 1) ポパ; 2) ポポー; 3) ポップ。 以下に説明する一連の命令を使用すると、フラグ レジスタをスタックに保存し、スタックにワードまたはダブル ワードを書き込むことができます。 1.pushf-フラグのレジスタをスタックに保存します。 2. pushfw - フラグのワードサイズのレジスタをスタックに保存します。 use16 属性を持つ pushf のように常に機能します。 3. pushfd - セグメントのビット幅属性に応じて、フラグまたは eflags フラグ レジスタをスタックに保存します (つまり、pushf と同じ)。 同様に、次のXNUMXつのコマンドは、上記の操作の逆を実行します。 1) ポップ; 2) popfw; 3) ポップド。 54. 算術コマンド このようなコマンドは、次の XNUMX つのタイプで機能します。 1) 整数の XNUMX 進数、つまり、XNUMX 進数システムでエンコードされた数値。 XNUMX 進数は、数値情報の特殊な表現形式であり、数値の各 XNUMX 進数を XNUMX ビットのグループでエンコードするという原則に基づいています。 マイクロプロセッサは、XNUMX 進数の加算規則に従ってオペランドの加算を実行します。 マイクロプロセッサの命令セットには、次の XNUMX つのバイナリ加算命令があります。 1) inc オペランド - オペランドの値を増やします。 2)オペランド1、オペランド2を追加 - 加算; 3) adc オペランド 1、オペランド 2 - キャリー フラグを考慮した加算。 符号なし XNUMX 進数の減算 被減数が減数よりも大きい場合、差は正になります。 被減数が減算した値よりも小さい場合、問題があります。結果は 0 未満であり、これはすでに符号付きの数値です。 符号なしの数値を減算した後、CF フラグの状態を分析する必要があります。 1 に設定されている場合、最上位ビットは借用されており、結果は XNUMX の補数コードになります。 符号付きの XNUMX 進数の減算 ただし、追加コードで符号付きの数値を加算して減算するには、被減数と減数の両方のオペランドを表す必要があります。 結果も XNUMX の補数値として扱う必要があります。 しかし、ここで困難が生じます。 まず第一に、それらはオペランドの最上位ビットが符号ビットと見なされるという事実に関連しています。 のオーバーフローフラグの内容によります。 これを 1 に設定すると、結果がこのサイズのオペランドの符号付き数値の範囲外である (つまり、最上位ビットが変更された) ことを示し、プログラマーは結果を修正するためのアクションを実行する必要があります。 オペランドの標準ビット グリッドを超える表現範囲を持つ数値を減算する原理は、加算の場合と同じです。つまり、キャリー フラグ cf が使用されます。 列で減算するプロセスを想像し、マイクロプロセッサ命令を sbb 命令と正しく組み合わせる必要があるだけです。 符号なし数を乗算するコマンドは次のとおりです。 マルチファクター_1 数値に符号を掛けるコマンドは次のとおりです。 [imul オペランド_1、オペランド_2、オペランド_3] div除数コマンドは、符号なし数を除算するためのものです。 idiv除数コマンドは、符号付き数を除算するためのものです。 55. ロジックコマンド 理論によれば、次の論理演算はステートメント (ビット) に対して実行できます。 1. 否定 (論理否定) - XNUMX つのオペランドに対する論理演算で、その結果は元のオペランドの値の逆数です。 2. 論理和 (論理的包括的 OR) - 1 つのオペランドの論理演算。その結果は、一方または両方のオペランドが真 (1) の場合は「真」 (0) になり、両方のオペランドが真 (0) の場合は「偽」 (XNUMX) になります。偽 (XNUMX)。 3. 論理乗算 (論理 AND) - 1 つのオペランドに対する論理演算で、両方のオペランドが真 (1) の場合にのみ結果が真 (0) になります。 それ以外の場合、操作の値は「false」(XNUMX) です。 4. 論理排他的加算 (論理排他的 OR) - 1 つのオペランドの論理演算。その結果は、1 つのオペランドのうちの 0 つだけが真 (0) の場合は「真」(1)、場合は偽 (XNUMX) です。両方のオペランドは、偽 (XNUMX) または真 (XNUMX) のいずれかです。 4. 論理排他的加算 (論理排他的 OR) - 1 つのオペランドの論理演算。その結果は、1 つのオペランドのうちの 0 つだけが真 (0) の場合は「真」(1)、場合は偽 (XNUMX) です。両方のオペランドは、偽 (XNUMX) または真 (XNUMX) のいずれかです。 論理データの操作をサポートする次の一連のコマンド: 1) and operand_1, operand_2 - 論理乗算演算; 2) or operand_1, operand_2 - 論理加算演算; 3) xor operand_1、operand_2 - 論理排他的加算の演算。 4) テスト operand_1、operand_2 - 「テスト」演算 (論理積による) 5) notオペランド - 論理否定の演算。 a) 特定の桁 (ビット) を 1 に設定するには、コマンドまたはオペランド_1、オペランド_2 が使用されます。 b) 特定の桁 (ビット) を 0 にリセットするには、コマンドとオペランド_1、オペランド_2 が使用されます。 c) コマンド xor operand_1、operand_2 が適用されます。 ▪ operand_1 と operand_2 のどのビットが異なるかを確認します。 ▪ 指定されたビットの状態を operand_1 に反転します。 コマンド test operand_1, operand_2 (check operand_1) は、指定されたビットのステータスをチェックするために使用されます。 コマンドの結果は、ゼロ フラグ zf の値を設定することです。 1) zf = 0 の場合、論理積の結果としてゼロの結果が得られました。つまり、マスクの 1 単位ビットがオペランド XNUMX の対応する単位ビットと一致しませんでした。 2) zf = 1 の場合、論理乗算の結果は非ゼロになります。つまり、マスクの少なくとも 1 つの単位ビットが、operandXNUMX の対応する XNUMX ビットと一致しました。 すべてのシフト命令は、オペコードに応じてオペランド フィールドのビットを左または右に移動します。すべてのシフト命令は、cop オペランド、シフト カウンタという同じ構造を持っています。 56. コントロール転送コマンド 次にどのプログラム命令を実行するか、マイクロプロセッサは cs の内容から学習します。 (e) ip レジスタ ペア: 1) cs - 現在のコード セグメントの物理アドレスを含むコード セグメント レジスタ。 2) eip/ip - 命令ポインタ レジスタ。次に実行される命令のメモリ内のオフセット値が含まれます。 無条件ジャンプ 何を変更する必要があるかは、以下によって異なります。 1) 無条件分岐命令のオペランドのタイプ (near または far)。 2) 遷移アドレスの前に修飾子を指定することから。 この場合、ジャンプ アドレス自体は、命令内で直接指定することも (直接ジャンプ)、メモリ レジスタ内で指定することもできます (間接ジャンプ)。 修飾子の値: 1) near ptr - ラベルへの直接遷移。 2) far ptr - 別のコード セグメントのラベルへの直接遷移。 3) word ptr - ラベルへの間接遷移。 4) dword ptr - 別のコード セグメントのラベルへの間接遷移。 jmp 無条件ジャンプ命令 jmp [修飾子] jump_address プロシージャまたはサブルーチンは、タスクの分解の基本的な機能単位です。 プロシージャはコマンドのグループです。 条件付きジャンプ マイクロプロセッサには、18 個の条件付きジャンプ命令があります。 これらのコマンドを使用すると、次のことを確認できます。 1) 符号付きオペランド間の関係 (「多いほど少ない」)。 2) 符号なしオペランド間の関係 (「より高いより低い」); 3) 算術フラグ ZF、SF、CF、OF、PF の状態 (AF は除く)。 条件付きジャンプ命令の構文は同じです: jcc jump label cmp compare コマンドには興味深い働き方があります。 サブオペランド_1、オペランド_2の減算コマンドとまったく同じです。 cmp コマンドは、sub コマンドと同様に、オペランドを減算し、フラグを設定します。 行わない唯一のことは、最初のオペランドの代わりに減算の結果を書き込むことです。 cmp コマンド構文 - cmp operand_1, operand_2 (compare) - は、XNUMX つのオペランドを比較し、比較の結果に基づいてフラグを設定します。 サイクルの編成 たとえば、制御コマンドの条件付き転送または無条件ジャンプ コマンド jmp を使用して、プログラムの特定のセクションの循環実行を編成できます。 1) ループ遷移ラベル (Loop) - ループを繰り返します。 このコマンドを使用すると、ループカウンターの自動デクリメントを使用して、高級言語の for ループと同様のループを編成できます。 2) loope/loopz ジャンプラベル loope コマンドと loopz コマンドは完全な同義語です。 3) loopne/loopnz ジャンプラベル コマンド loopne と loopnz も絶対的な同義語です。 loope/loopz コマンドと loopne/loopnz コマンドは相互に作用します。 著者: Tsvetkova A.V.
タッチエミュレーション用人工皮革
15.04.2024 Petgugu グローバル猫砂
15.04.2024 思いやりのある男性の魅力
14.04.2024
▪ 雨の匂い
▪ 記事 誰がメキシコ人に死者の日の仮装パレードを企画させたのか? 詳細な回答 ▪ 記事 フライス盤。 無線エレクトロニクスと電気工学の百科事典
ホームページ | 図書館 | 物品 | サイトマップ | サイトレビュー
www.diagram.com.ua |



 他の記事も見る セクション
他の記事も見る セクション 