|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
データベース。 講義ノート:簡単に言えば、最も重要な
目次
第1回 はじめに 1.データベース管理システム データベース管理システム(DBMS) 以下を可能にする特殊なソフトウェア製品です。 1)任意に大量の(ただし無限ではない)データを永続的に保存します。 2)いわゆるクエリを使用して、これらの保存されたデータを何らかの方法で抽出および変更します。 3)新しいデータベースを作成します。つまり、論理データ構造を記述し、それらの構造を設定します。つまり、プログラミングインターフェイスを提供します。 4)複数のユーザーが同時に保存されたデータにアクセスする(つまり、トランザクション管理メカニズムへのアクセスを提供する)。 したがって、 データベース 管理システムの管理下にあるデータセットです。 現在、データベース管理システムは市場で最も複雑なソフトウェア製品であり、その基盤を形成しています。 将来的には、従来のデータベース管理システムとオブジェクト指向プログラミング(OOP)およびインターネット技術を組み合わせた開発を行う予定です。 当初、DBMS は以下に基づいていました。 階層的 и ネットワーク データ モデル、つまり、ツリー構造とグラフ構造のみを操作できます。 1970 年の開発過程で、Codd (コッド) によって提案されたデータベース管理システムがありました。 リレーショナル データ モデル. 2. リレーショナル データベース 「リレーショナル」という用語は、英語の「関係」-「関係」に由来します。 最も一般的な数学的意味で(古典的な集合代数コースから覚えているかもしれませんが) 態度 -セットです R = {(x1、...、 バツn) | バツ1 ∈ A1、...、バツn ∈ An}, ここで1、...、An デカルト積を形成するセットです。 この上、 比率R セットのデカルト積のサブセットです:A1 ×...×An : R⊆A 1 ×...×An. たとえば、順序付けられた数のペアの集合 A について、厳密な順序「より大きい」と「より小さい」の XNUMX 項関係を考えてみましょう。 1 = A2 = {3、4、5}: R> = {(3、4)、(4、5)、(3、5)} ⊂ A1 ×A2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 ×A2. これらの関係は、表の形式で表すことができます。 「より大きい」比率>:
R「未満」の比率<:
したがって、リレーショナルデータベースでは、さまざまなデータがリレーションシップの形式で編成され、テーブルの形式で表示できることがわかります。 これらのXNUMXつの関係Rに注意する必要があります> そしてR< つまり、これらの関係に対応するテーブルは互いに等しくありません。 したがって、リレーショナルデータベースのデータ表現の形式は異なる場合があります。 私たちの場合、この異なる表現の可能性はどのように現れますか? 関係R> そしてR< - これらはセットであり、セットは順序付けられていない構造です。つまり、これらの関係に対応するテーブルでは、行を入れ替えることができます。 しかし同時に、これらのセットの要素は順序付きセットです。この場合、番号 3、4、5 の順序付きペアです。つまり、列を交換することはできません。 このように、任意の行順序と固定数の列を持つテーブルとしての (数学的な意味での) リレーションの表現は、リレーションの表現の許容できる正しい形式であることを示しました。 しかし、関係 R を考えると> そしてR< それらに埋め込まれた情報の観点から、それらが同等であることは明らかです。 したがって、リレーショナルデータベースでは、「関係」の概念は、一般的な数学の関係とは少し異なる意味を持ちます。 つまり、表形式の表示の列による順序付けとは関係ありません。 代わりに、いわゆる「行-列見出し」関係スキームが導入されます。つまり、各列に見出しが付けられ、その後、自由に交換できます。 R 関係は次のようになります。> そしてR< リレーショナル データベースで。 厳密な順序関係(関係Rの代わりに)>):
厳密な順序関係(関係Rの代わりに)<):
両方のテーブル-リレーションシップは新しいものを取得します(この場合、同じです。追加のヘッダーを導入することで、リレーションR間の違いを消去したためです。> そしてR<) 題名。 したがって、必要なヘッダーをテーブルに追加するなどの簡単なトリックの助けを借りて、関係 R という結論に達することがわかります。> そしてR< 互いに同等になる。 したがって、一般的な数学的および関係的な意味での「関係」の概念は完全には一致せず、同一ではないと結論付けます。 現在、リレーショナルデータベース管理システムは情報技術市場の基盤を形成しています。 さまざまな程度のリレーショナルモデルを組み合わせる方向で、さらなる研究が行われています。 講義#2。欠測データ データベース管理システムでは、欠損データを検出するために XNUMX 種類の値が記述されています。空 (または空の値) と未定義 (または Null 値) です。 一部の (主に商業的な) 文献では、Null 値は空または null 値と呼ばれることがありますが、これは正しくありません。 空の意味と不定の意味は根本的に異なるため、特定の用語の使用状況を注意深く監視する必要があります。 1.空の値(Empty-values) 空の値 は、明確に定義されたデータ型の多くの可能な値のXNUMXつにすぎません。 最も「自然」で即時的なものをリストします 空の値 (つまり、追加情報なしで自分で割り当てることができる空の値): 1) 0 (ゼロ) - 数値データ型の null 値は空です。 2) false (間違っている) - boolean データ型の空の値です。 3)B''-可変長文字列の場合は空のビット文字列。 4)""-可変長の文字列の場合は空の文字列。 上記の場合、既存の値を各データ型に定義されたnull定数と比較することにより、値がnullであるかどうかを判断できます。 ただし、データベース管理システムは、長期的なデータストレージ用に実装されているスキームにより、一定の長さの文字列でのみ機能します。 このため、ビットの空の文字列は、バイナリゼロの文字列と呼ぶことができます。 または、スペースまたはその他の制御文字で構成される文字列は、空の文字列です。 一定長の空の文字列の例を次に示します。 1) B'0'; 2) B'000'; 3) ' '. このような場合、文字列が空であるかどうかをどのように判断できますか? データベース管理システムでは、論理関数を使用して空であることをテストします。つまり、述語 IsEmpty(<式>)、これは文字通り「空を食べる」という意味です。 この述語は通常、データベース管理システムに組み込まれており、あらゆるタイプの式に適用できます。 データベース管理システムにそのような述語がない場合は、論理関数を自分で記述して、設計中のデータベースのオブジェクトのリストに含めることができます。 空の値があるかどうかを判断するのがそれほど簡単ではない別の例を考えてみましょう。 日付型データ。 日付が 01.01.0100 からの範囲で変化する可能性がある場合、この型のどの値を空の値と見なす必要がありますか。 31.12.9999 年 XNUMX 月 XNUMX 日より前ですか? これを行うために、特別な指定が DBMS に導入されます。 空の日付定数 {...}、この型の値が書かれている場合: {DD. んん。 YY} または {YY. んん。 DD}。 この値を使用すると、値が空かどうかをチェックするときに比較が行われます。 これは、このタイプの式の明確に定義された「完全な」値であり、可能な限り小さい値であると見なされます。 データベースを操作する場合、null 値はデフォルト値として使用されることが多く、式の値が欠落している場合に使用されます。 2.未定義の値 (ヌル値) 単語 ヌル を表すために使用される 未定義の値 データベースで。 どの値が未定義として理解されるかをよりよく理解するために、データベースのフラグメントであるテーブルを考えてみましょう。
このように、 未定義の値 または ヌル値 は: 1) 不明だが通常、つまり適用可能な値。 たとえば、私たちのデータベースでナンバーワンのKhairetdinov氏は、間違いなくいくつかのパスポートデータ(1980年生まれの人やその国の市民など)を持っていますが、それらは知られていないため、データベースには含まれていません. したがって、テーブルの対応する列に Null 値が書き込まれます。 2) 該当しない値。 カラマーゾフ氏 (私たちのデータベースの 2 番) は、このデータベースの作成時またはデータベースへのデータの入力時に、彼は子供だったので、パスポート データを持つことはできません。 3)該当するかどうかわからない場合は、テーブルの任意のセルの値。 たとえば、データベースのXNUMX番目の位置にあるコバレンコ氏は生年月日を知らないため、パスポートデータを持っているかどうかははっきりとは言えません。 その結果、コバレンコ氏に捧げられた行のXNUMXつのセルの値はNull値になります(最初のセルは一般的に不明であり、XNUMX番目のセルは性質が不明な値です)。 他のデータ型と同様に、Null値にも特定の値があります プロパティ。 それらの中で最も重要なものをリストします。 1) 時間の経過とともに、Null 値の理解が変わる可能性があります。 たとえば、2 年のカラマーゾフ氏 (データベースで 2014 位) の場合、つまり成年に達すると、Null 値は明確に定義された特定の値に変化します。 2)null値は、任意のタイプ(数値、文字列、ブール値、日付、時刻など)の変数または定数に割り当てることができます。 3) オペランドとして Null 値を持つ式に対する演算の結果は Null 値です。 4) 前の規則の例外は、吸収の法則の条件下での結合および分離の操作です (吸収の法則の詳細については、講義 No. 4 の段落 2 を参照してください)。 3. Null 値と式を評価するための一般的な規則 Null 値を含む式に対するアクションについて詳しく説明しましょう。 Null 値を処理するための一般的な規則 (Null 値に対する操作の結果が Null 値である) は、次の操作に適用されます。 1) 算術; 2) ビットごとの否定、結合、および論理和演算 (吸収則を除く)。 3)文字列を使用した操作(たとえば、連結-文字列の連結)。 4)比較操作(<、≤、≠、≥、>)。 例を挙げましょう。 次の操作を適用した結果、Null値が取得されます: 3 + Null、1/ Null、(Ivanov' + '' + Null) ≔ Null ここでは、通常の平等の代わりに、 置換操作 Null値を操作するという特殊な性質のために「≔」。 以下では、この文字も同様の状況で使用されます。つまり、ワイルドカード文字の右側の式は、リストのワイルドカード文字の左側の式を置き換えることができます。 ヌル値の性質により、多くの場合、一部の式では、予期されるヌルではなくヌル値が生成されます。たとえば、次のようになります。 (x - x), y * (x - x), x * 0 ≔ x = Null の場合は Null。 たとえば、値 x = Null を式 (x - x) に代入すると、式 (Null - Null) が得られ、Null 値を含む式の値を計算するための一般規則が得られます。が有効になり、ここで Null 値が同じ変数に対応するという事実に関する情報が失われます。 ブール値以外の演算を計算する場合、Null値は次のように解釈されると結論付けることができます 適用外、したがって、結果もNull値になります。 比較操作で Null 値を使用すると、予想外の結果が生じることもあります。 たとえば、次の式も、予想されるブール値の True または False 値ではなく、Null 値を生成します。 (ヌル < ヌル); (ヌル ≤ ヌル); (Null = Null); (Null≠Null); (ヌル > ヌル); (ヌル ≥ ヌル) ≔ ヌル; したがって、Null値がそれ自体と等しいか等しくないと言うことは不可能であると結論付けます。 ヌル値が新たに出現するたびに独立したものとして扱われ、ヌル値が異なる未知の値として扱われるたびに。 この場合、Null値は他のすべてのデータ型とは根本的に異なります。これは、以前に渡されたすべての値とそれらの型について、それらが互いに等しいか等しくないかを言うのが安全であることがわかっているためです。 したがって、Null値は、通常の意味での変数の値ではないことがわかります。 したがって、次の例のように、結果としてブール値のTrueまたはFalse値ではなく、Null値を受け取るため、Null値を含む変数または式の値を比較することは不可能になります: (x < Null); (バツ ≤ ヌル); (x=ヌル); (x ≠ Null); (x > Null); (x ≥ ヌル) ≔ ヌル; したがって、空の値との類推により、式でNull値をチェックするには、特別な述語を使用する必要があります。 IsNull(<式>)、これは文字通り「ヌル」を意味します。 Boolean 関数は、式に Null が含まれているか Null に等しい場合に True を返し、それ以外の場合は False を返しますが、Null を返すことはありません。 IsNull 述語は、任意の型の変数および式に適用できます。 空の型の式に適用すると、述語は常に False を返します。 たとえば、次のように
したがって、実際、最初のケースでは、IsNull述語がゼロから取得されたときに、出力がFalseであることがわかります。 XNUMX番目とXNUMX番目を含むすべての場合で、論理関数の引数がNull値に等しいことが判明したとき、およびXNUMX番目の場合、引数自体が最初にNull値に等しいとき、述語はTrueを返しました。 4.ヌル値と論理演算 通常、データベース管理システムで直接サポートされている論理演算は、否定 ¬、結合 &、および分離 ∨の XNUMX つだけです。 継承⇒と同値⇔の操作は、代入を使って表現されます。 (x ⇒ y) ≔ (зx ∨ y); (x⇔y)≔(x⇒y)&(y⇒x); Null 値を使用する場合、これらの置換は完全に保持されることに注意してください。 興味深いことに、否定演算子「¬」を使用すると、論理積 & または論理和 ∨ のいずれかを次のように繰り返し表現できます。 (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); これらの置換は、前のものと同様に、Null 値の影響を受けません。 次に、否定、論理積、論理和の論理演算の真理値表を示しますが、通常の True 値と False 値に加えて、Null 値もオペランドとして使用します。 便宜上、次の表記法を導入します。True の代わりに t、False の代わりに - f、Null の代わりに - n と書きます。 1. 否認 xx.
Null値を使用した否定操作に関して次の興味深い点に注意する価値があります。 1) ¬¬x ≔ x - 二重否定の法則。 2)¬Null≔Null-Null値は固定小数点です。 2. 接続詞x&y.
この操作には、独自のプロパティもあります。 1)x&y≔y&x-可換性; 2)x&x≔x-べき等; 3)False&y≔False、ここでFalseは吸収要素です。 4)True&y≔y、ここでTrueは中立要素です。 3. 論理和x ∨ y.
特徴: 1)x∨y≔y∨x-可換性; 2) x ∨ x ≔ x - 冪等性; 3)False∨y≔y、ここでFalseは中立要素です。 4) True ∨ y ≔ True、ここで True は吸収要素です。 一般的なルールの例外は、アクションの条件下での論理演算論理積 & および論理和 ∨ を計算するためのルールです。 吸収法則: (False&y)≔(x&False)≔False; (真 ∨ y) ≔ (x ∨ 真) ≔ 真; これらの追加ルールは、Null値をFalseまたはTrueに置き換えた場合でも、結果がこの値に依存しないように作成されています。 他のタイプの操作について前に示したように、ブール演算でNull値を使用すると、予期しない値が発生する可能性もあります。 たとえば、一見したところロジックは壊れています XNUMX番目の除外の法則 (x∨¬x)および 再帰性の法則 (x = x)、x ≔ Null の場合: (x∨¬x)、(x = x)≔ヌル。 法律は施行されていません! これは以前と同じ方法で説明されています:Null値が式に代入されると、この値が同じ変数によって報告されるという情報が失われ、Null値を操作するための一般的なルールが有効になります。 したがって、次のように結論付けます。オペランドとしてNull値を使用して論理演算を実行する場合、これらの値はデータベース管理システムによって次のように決定されます。 該当するが不明. 5.ヌル値と条件チェック したがって、上記のことから、データベース管理システムのロジックには、XNUMXつの論理値(TrueとFalse)ではなく、XNUMXつの論理値があると結論付けることができます。これは、Null値も可能な論理値のXNUMXつと見なされるためです。 そのため、不明な値、不明な値と呼ばれることがよくあります。 ただし、これにも関わらず、データベース管理システムにはXNUMX値論理しか実装されていません。 したがって、Null値を持つ条件(未定義の条件)は、マシンによってTrueまたはFalseとして解釈される必要があります。 デフォルトでは、DBMS言語はNull値を持つ条件をFalseとして認識します。 これを、データベース管理システムでの条件付きIfおよびWhileステートメントの実装の次の例で説明します。 Pの場合はA、それ以外の場合はB; このエントリは、PがTrueと評価された場合、アクションAが実行され、PがFalseまたはNullと評価された場合、アクションBが実行されることを意味します。 この演算子に否定演算を適用すると、次のようになります。 ¬Pの場合はB、それ以外の場合はA; 次に、この演算子は次のことを意味します。¬P が True と評価された場合はアクション B が実行され、¬P が False または Null と評価された場合はアクション A が実行されます。 また、ご覧のとおり、Null値が表示されると、予期しない結果が発生します。 重要なのは、この例のXNUMXつのIfステートメントは同等ではないということです。 一方は、条件を否定してブランチを再配置することによって、つまり標準操作によって、もう一方から取得されます。 このような演算子は一般的に同等です! しかし、この例では、最初のケースの条件Pのnull値はコマンドBに対応し、XNUMX番目のケースでは-Aに対応していることがわかります。 ここで、while条件ステートメントのアクションについて考えてみましょう。 PがAをしている間に; B; このオペレーターはどのように機能しますか? P が True である限りアクション A が実行され、P が False または Null になるとすぐにアクション B が実行されます。 ただし、Null値は常にFalseとして解釈されるとは限りません。 たとえば、整合性制約では、未定義の条件がTrueとして認識されます(整合性制約は、入力データに課せられ、その正確性を保証する条件です)。 これは、このような制約では、意図的に誤ったデータのみを拒否する必要があるためです。 また、データベース管理システムには、特別なものがあります 置換関数IfNull(整合性制約、True)、Null値と未定義の条件を明示的に表すことができます。 この関数を使用して、条件付きのIfステートメントとWhileステートメントを書き直してみましょう。 1) IfNull ( P, False) then A else B; 2) IfNull( P, False) が A を実行している間。 B; したがって、置換関数IfNull(式1、式2)は、Null値が含まれていない場合は最初の式の値を返し、それ以外の場合はXNUMX番目の式の値を返します。 IfNull関数によって返される式のタイプに制限が課されていないことに注意してください。 したがって、この関数を使用すると、Null値を操作するためのルールを明示的にオーバーライドできます。 講義#3。リレーショナルデータオブジェクト 1. 関係を表す表形式の要件 1.関係の表現の表形式の最初の要件は有限性です。 無限のテーブル、リレーションシップ、またはその他の表現やデータ編成を操作することは不便であり、費やされた労力を正当化することはめったにありません。さらに、この方向性はほとんど実用的ではありません。 しかし、これに加えて、かなり予想されることですが、他の要件があります。 2. 関係を表す表の見出しは、必ず XNUMX 行 (列の見出し) と固有の名前で構成する必要があります。 マルチレベル ヘッダーは使用できません。 たとえば、次のとおりです。
適切な見出しを選択することにより、すべての多層見出しが単一層見出しに置き換えられます。 この例では、指定された変換後のテーブルは次のようになります。
各列の名前は一意であるため、好きなように入れ替えることができます。つまり、順序は関係ありません。 そして、これはXNUMX番目のプロパティであるため、非常に重要です。 3.行の順序は重要ではありません。 ただし、どのテーブルも必要な形式に簡単に縮小できるため、この要件も厳密に制限されているわけではありません。 たとえば、行の順序を決定する追加の列を入力できます。 この場合、線の再配置からも何も変わりません。 このようなテーブルの例を次に示します。
4.関係を表す重複する行がテーブルにないようにする必要があります。 テーブルに重複する行がある場合、これは、各行の重複の数を担当する追加の列を導入することで簡単に修正できます。次に例を示します。
次のプロパティも、プログラミングとリレーショナル データベースの設計のすべての原則の根底にあるため、非常に期待されています。 5.すべての列のデータは同じタイプである必要があります。 その上、それらは単純なタイプでなければなりません。 単純なデータ型と複雑なデータ型とは何かを説明しましょう。 単純なデータ型は、データ値が非複合である、つまり、構成要素を含まないデータ型です。 したがって、リスト、配列、ツリー、または同様の複合オブジェクトは、テーブルの列に存在してはなりません。 そのようなオブジェクトは 複合データ型 - リレーショナル データベース管理システムでは、それら自体が独立したテーブル リレーションシップの形式で表示されます。 2.ドメインと属性 ドメインと属性は、データベースの作成と管理の理論における基本的な概念です。 それが何であるかを説明しましょう。 正式には、 属性ドメイン (によって示される dom(a))、ここで、a は属性であり、対応する属性 a の同じタイプの有効な値のセットとして定義されます。 この型は単純でなければなりません。つまり: dom(a)⊆{x | type(x)= type(a)}; 属性 (aで示される)は、属性名name(a)と属性ドメインdom(a)で構成される順序対として定義されます。 a =(name(a):dom(a)); この定義では、通常の「、」の代わりに「:」を使用します(標準の順序対定義の場合と同様)。 これは、属性のドメインと属性のデータ型の関連付けを強調するために行われます。 さまざまな属性の例を次に示します。 а1 = (コース: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | type(x) = real, x 0}); а3 =(LengthSm:{x | type(x)= real、x 0}); 属性aに注意してください2 と3 ドメインは正式に一致します。 しかし、質量と長さの値を比較することは無意味であるため、これらの属性の意味的な意味は異なります。 したがって、属性ドメインは、有効な値のタイプだけでなく、意味的な意味にも関連付けられます。 表形式の関係では、属性はテーブルの列見出しとして表示され、属性のドメインは指定されていませんが、暗黙的に示されています。 これは次のようになります。
ここで各見出しが1 2 3 関係を表すテーブルの列は、個別の属性です。 3.関係のスキーム。 名前付き値タプル DBMS の理論と実践では、リレーション スキーマと属性のタプルの名前付き値の概念が基本です。 それらを持って行きましょう。 関係スキーム (によって示される S)は、一意の名前を持つ属性の有限セットとして定義されます。つまり、次のようになります。 S = {a | a ∈ S}; リレーションを表す各テーブルでは、すべての列見出し (すべての属性) がリレーションのスキーマに結合されます。 リレーションシップ スキーマ内の属性の数によって決定されます 度 この 関係 セットのカーディナリティとして示されます。S|. 関係スキーマは、関係スキーマ名に関連付けることができます。 表形式の関係表現では、簡単にわかるように、関係スキーマは列見出しの行にすぎません。
S = {a1 2 3 4}-このテーブルの関係スキーマ。 リレーション名は、テーブルの概略見出しとして表示されます。 テキスト形式では、リレーションシップ スキーマは属性名の名前付きリストとして表すことができます。次に例を示します。 生徒(教科書番号、姓、名、父称、生年月日)。 ここでは、表形式の場合と同様に、属性ドメインは指定されていませんが、暗示されています。 定義から、関係のスキーマが空になることもあります (S = ∅)。 確かに、これは理論上のみ可能です。実際には、データベース管理システムでは空の関係スキーマの作成が許可されないためです。 属性の名前付きタプル値 (によって示される t(a))は、属性名と属性値で構成される順序対としての属性との類推によって定義されます。つまり、次のようになります。 t(a) = (名前(a) : x), x ∈ dom(a); 属性値が属性ドメインから取得されていることがわかります。 表形式のリレーションでは、属性のタプルの各名前付き値は、対応するテーブルセルです。
ここでt(a1)、t(a2)、t(a3)-属性aのタプルtの名前付き値1と2と3. 属性の名前付きタプル値の最も単純な例: (コース:5)、(スコア:5); ここで、CourseとScoreはそれぞれ5つの属性の名前であり、XNUMXはそれらのドメインから取得された値のXNUMXつです。 もちろん、これらの値はどちらの場合も同じですが、どちらの場合もこれらの値のセットが互いに異なるため、意味的に異なります。 4. タプル。 タプル型 データベース管理システムにおけるタプルの概念は、さまざまな属性でのタプルの名前付き値について説明した前のポイントから、すでに直感的に理解できます。 そう、 タプル (によって示される t、 英語から。 タプル - 「タプル」) リレーション スキーム S を持つこのリレーション スキーム S に含まれるすべての属性について、このタプルの名前付き値のセットとして定義されます。つまり、属性は次から取得されます。 タプルのスコープ、def(t)、つまり: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;。 XNUMX つの属性名に対応する属性値は XNUMX つだけにすることが重要です。 表形式のリレーションシップでは、タプルはテーブルの任意の行になります。つまり、次のようになります。
ここでt1(S)= {t(a1)、t(a2)、t(a3)、t(a4)}およびt2(S)= {t(a5)、t(a6)、t(a7)、t(a8)} - タプル。 DBMSのタプルは 種類 定義域によって異なります。 タプルは次のように呼ばれます。 1) 部分的、その定義領域が関係のスキーマに含まれるか一致する場合、つまり def(t) ⊆ S。 これは、データベースの実践では一般的なケースです。 2) コンプリート、それらの定義領域が完全に一致する場合、関係スキーム、つまり def(t) = S と等しくなります。 3) 不完全な、定義域が関係スキームに完全に含まれている場合、つまり def(t) ⊂ S; 4) どこにも定義されていない、定義域が空集合に等しい場合、つまり def(t) = ∅ です。 例を挙げて説明しましょう。 次の表に示す関係があるとしましょう。
ここで1 = {10, 20, 30}, t2 = {10、20、Null}、t3 = {ヌル、ヌル、ヌル}。 次に、タプル t が1 -定義域がdef(t)であるため、完了1) = {a, b, c} = S. タプル t2 -不完全、def(t2) = { a, b} ⊂ S. 最後に、タプル t3 - def(t3) = ∅ であるため、どこにも定義されていません。 どこにも定義されていないタプルは空のセットですが、関係スキームに関連付けられていることに注意してください。 どこにも定義されていないタプルは、∅(S) と表記されることがあります。 上記の例で既に見たように、そのようなタプルは Null 値のみで構成されるテーブル行です。 興味深いことに、 同程度の、つまり、おそらく等しいのは、同じ関係スキーマを持つタプルのみです。 したがって、たとえば、関係スキームが異なるXNUMXつのどこにも定義されていないタプルは、予想どおりに等しくなりません。 それらは、それらの関係パターンと同じように異なります。 5. 関係。 関係の種類 そして最後に、関係をピラミッドの一種として定義しましょう。これまでのすべての概念で構成されています。 そう、 態度 (によって示される r、 英語から。 関係)と関係スキーマSは、同じ関係スキーマSを持つ必然的に有限のタプルのセットとして定義されます。 r ≡ r(S) = {t(S) | t∈r}; リレーション スキームとの類推により、リレーション内のタプルの数が呼び出されます。 関係力 セットのカーディナリティとして示されます。r|. タプルのような関係は、タイプが異なります。 したがって、この関係は次のように呼ばれます。 1) 部分的、関係内のいずれかのタプルに対して次の条件が満たされる場合:[def(t)⊆S]。 これは(タプルと同様に)一般的なケースです。 2) コンプリート、場合 ∀t ∈ r(S) [def(t) = S]; 3) 不完全な、∃t∈r(S)def(t)⊂Sの場合; 4) どこにも定義されていない、∀t∈r(S)[def(t)=∅]の場合。 どこにも定義されていない関係に特別な注意を払いましょう。 タプルとは異なり、このような関係での作業には少し微妙な点があります。 重要なのは、どこにも定義されていない関係にはXNUMXつのタイプがあり、空であるか、どこにも定義されていない単一のタプルを含めることができるということです(このような関係は{∅(S)}で示されます)。 同程度の (タプルとの類推により)、つまり、等しい可能性があるのは、同じ関係スキーマを持つ関係のみです。 したがって、異なる関係パターンを持つ関係は異なります。 表形式では、リレーションはテーブルの本体であり、行(列の見出し、つまり文字通り)が、見出しを含む最初の行とともにテーブル全体に対応します。 講義番号 4. 関係代数。 単項演算 関係代数ご想像のとおり、これは特別なタイプの代数であり、すべての操作がリレーショナル データ モデル、つまり関係に対して実行されます。 表形式では、関係には行、列、および行(列の見出し)が含まれます。 したがって、自然な単項演算は、特定の行または列を選択し、列ヘッダーを変更する操作、つまり属性の名前を変更する操作です。 1.単項選択演算 最初に見る単項演算は次のとおりです。 フェッチ操作 -ある原則に従って、リレーションを表すテーブルから行を選択する操作、つまり、特定の条件を満たす行タプルを選択します。 フェッチ演算子 σで表される、 サンプリング条件 - P 、つまり、演算子 σ は常にタプル P の特定の条件で使用され、条件 P 自体は関係 S のスキームに応じて記述されます。これらすべてを考慮に入れると、 フェッチ操作 関係 r に関連する関係 S のスキームは、次のようになります。 σ r(S) ≡ σ r = {t(S)|t∈r&P t} = {t(S)|t∈r&IfNull(P t、False}; この操作の結果は、選択条件を満たす元の関係オペランドのタプルt(S)で構成される、同じ関係スキーマSを持つ新しい関係になります。 タプルにある種の条件を適用するには、属性名の代わりにタプル属性の値を置き換える必要があることは明らかです。 この操作がどのように機能するかをよりよく理解するために、例を見てみましょう。 次の関係スキームが与えられます。 S: セッション (成績表番号、姓、科目、成績)。 選択条件を次のように考えてみましょう。 P = (件名 = 'コンピュータ サイエンス' と評価 > 3)。 最初の関係から抽出する必要があります-オペランドと、主題「コンピュータサイエンス」を少なくともXNUMXポイント通過した学生に関する情報を含むタプル。 この関係から次のタプルも与えられます。 t0(S) ∈ r(S): {(Gradebook #: 100), (Surname: 'Ivanov'), (Subject: 'Databases'), (Score: 5)}; 選択条件をタプルtに適用する0、 我々が得る: P t0 = ('データベース' = 'コンピュータ サイエンス' および 5 > 3); この特定のタプルでは、選択条件が満たされていません。 一般に、この特定のサンプルの結果は σ<Subject='ComputerScience' and Grade> 3> Session 選択条件を満たす行が残っている「セッション」テーブルがあります。 2. 単項射影演算 私たちが研究するもうXNUMXつの標準的な単項演算は、射影演算です。 投影操作 何らかの属性に従って、関係を表すテーブルから列を選択する操作です。 つまり、マシンは、プロジェクションで指定された元のオペランド関係の属性 (つまり、文字通り列) を選択します。 射影演算子 [S']またはπで表されます。 ここで、S'は、リレーションSの元のスキーマ、つまりその列の一部のサブスキーマです。 これは何を意味するのでしょうか? これは、投影条件が満たされたS'に残っているのは属性のみであるため、S'の属性はSよりも少ないことを意味します。 また、リレーションr(S')を表すテーブルには、テーブルr(S)と同じ数の行があり、残りの属性に対応する列のみが残っているため、列は少なくなります。 したがって、関係r(S)に適用された射影演算子π<S'>は、元のタプルの射影t(S)[S']で構成される、異なる関係スキームr(S')を持つ新しい関係になります。関係。 これらのタプルプロジェクションはどのように定義されていますか? 投影 サブサーキットS'に対する元の関係r(S)のタプルt(S)は、次の式で決定されます。 t(S)[S'] = {t(a)|a∈def(t)∩S'}、S'⊆S。 重複するタプルは結果から除外されることに注意することが重要です。つまり、新しいタプルを表す重複する行はテーブルにありません。 上記のすべてを念頭に置いて、データベース管理システムに関する投影操作は次のようになります。 π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S'] = {t(S) [S'] | t ∈ r}; フェッチ操作がどのように機能するかを示す例を見てみましょう。 リレーション「Session」とこのリレーションのスキームを指定します。 S:セッション(クラスブック番号、名前、件名、成績); このスキームのXNUMXつの属性、つまり学生の「Gradebook#」と「LastName」のみに関心があるため、Sのサブスキーマは次のようになります。 S':(レコードブック番号、名前)。 初期関係 r(S) を部分回路 S' に射影する必要があります。 次に、タプルtを与えましょう0(S) 元の関係から: t0(S) ∈ r(S): {(Gradebook #: 100), (Surname: 'Ivanov'), (Subject: 'Databases'), (Score: 5)}; したがって、このタプルの特定のサブサーキットS'への投影は次のようになります。 t0(S)S':{(帳簿番号:100)、(名前:'Ivanov')}; テーブルの観点から投影操作について話す場合、元のリレーションの投影セッション [成績表番号、姓] はセッション テーブルであり、そこから XNUMX つの列 (成績表番号と姓) を除くすべての列が削除されます。 さらに、すべての重複行も削除されました。 3.単項名前変更操作 そして、私たちが見る最後の単項演算は 属性の名前変更操作. リレーションシップをテーブルとして説明する場合、すべてまたは一部の列の名前を変更するには、名前変更操作が必要です。 名前変更演算子 次のようになります:ρ<φ>、ここではφ- リネーム機能. この関数は、スキーマ属性名SとŜの間にXNUMX対XNUMXの対応を確立します。ここで、それぞれSは元のリレーションのスキーマであり、Ŝは名前が変更された属性を持つリレーションのスキーマです。 したがって、関係r(S)に適用される演算子ρ<φ>は、名前が変更された属性のみを持つ元の関係のタプルで構成されるスキーマŜとの新しい関係を提供します。 データベース管理システムの観点から属性の名前を変更する操作を書いてみましょう。 ρ<φ>r(S)≡ρ<φ> r ={ρ<φ>t(S)| t∈r}; この操作の使用例を次に示します。 スキームを使用して、すでにおなじみの Session 関係を考えてみましょう。 S:セッション(クラスブック番号、名前、件名、成績); 既存の属性名の代わりに表示したいさまざまな属性名を使用して、新しい関係スキーマŜを紹介しましょう。 Ŝ : (No. ZK、姓、件名、スコア); たとえば、データベースの顧客は、すぐに使用できるリレーションで他の名前を見たいと思っていました。 この順序を実装するには、次の名前変更関数を設計する必要があります。 φ:(レコードブックの数、名前、件名、成績)→(番号ZK、名前、件名、スコア); 実際、名前を変更する必要があるのはXNUMXつの属性だけなので、現在の属性の代わりに次の名前変更関数を作成することは合法です。 φ:(記録簿の数、グレード) → (番号 ZK、スコア); さらに、Sessionリレーションに属するすでにおなじみのタプルも指定します。 t0(S) ∈ r(S): {(Gradebook #: 100), (Surname: 'Ivanov'), (Subject: 'Databases'), (Score: 5)}; このタプルに名前変更演算子を適用します。 ρ<φ>t0(S): {(ZK #: 100), (姓: 'イワノフ'), (件名: 'データベース'), (スコア: 5)}; つまり、これはリレーションのタプルのXNUMXつであり、その属性の名前が変更されています。 表形式で、比率 ρ < 成績表番号、成績 → 「いいえ。ZK、スコア>セッション- これは、指定された属性の名前を変更することによって「セッション」関係テーブルから取得された新しいテーブルです。 4. 単項演算の性質 単項演算は、他の演算と同様に、特定のプロパティを持っています。 それらの中で最も重要なものを考えてみましょう。 単項選択、射影、および名前変更操作の最初のプロパティは、関係のカーディナリティの比率を特徴付けるプロパティです。 (カーディナリティは、XNUMXつまたは別の関係にあるタプルの数であることを思い出してください。)ここでは、初期関係と、XNUMXつまたは別の操作を適用した結果として得られる関係をそれぞれ検討していることは明らかです。 単項演算のすべてのプロパティは、それらの定義に直接従うので、簡単に説明でき、必要に応じて独立して推定することもできます。 だから: 1) 電力比: a)選択操作の場合:| σ r|≤|r|; b)投影操作の場合:| r [S'] | ≤|r|; c)名前変更操作の場合:| ρ<φ>r| = | r |; 合計すると、XNUMXつの演算子、つまり選択演算子と射影演算子の場合、元の関係オペランドの累乗は、対応する演算を適用することによって元の関係から取得された関係の累乗よりも大きいことがわかります。 これは、これらXNUMXつの選択操作とプロジェクト操作に伴う選択で、選択条件を満たす行または列が除外されるためです。 すべての行または列が条件を満たす場合、パワー(つまり、タプルの数)が減少することはないため、式の不等式は厳密ではありません。 名前の変更操作の場合、名前を変更するときにリレーションから除外されるタプルがないため、リレーションの力は変わりません。 2) べき等プロパティ: a)サンプリング操作の場合:σ σ r=σ ; b) 射影操作の場合: r [S'] [S'] = r [S']; c)名前変更操作の場合、一般的な場合、べき等のプロパティは適用されません。 このプロパティは、同じ演算子を任意のリレーションに XNUMX 回続けて適用することは、XNUMX 回適用することと同じであることを意味します。 リレーション属性の名前変更の操作については、一般的に言えば、このプロパティを適用できますが、特別な予約と条件があります。 べき等の性質は、式の形式を単純化し、より経済的で実際の形式にするために非常によく使用されます。 そして最後に検討する特性は、単調性の特性です。 興味深いことに、どのような条件下でも XNUMX つの演算子はすべて単調です。 3) 単調性プロパティ: a)フェッチ操作の場合:r1 ⊆ r2 ⇒σ r1 はこちらをご覧ください。⇒ σ r2; b) 投影操作: r1 ⊆ r2 はこちらをご覧ください。⇒ r1[S'] ⊆ r2 [S']; c) 名前変更操作の場合: r1 ⊆ r2 はこちらをご覧ください。⇒ ρ<φ>r1 ⊆ ρ<φ>r2; 関係代数における単調性の概念は、通常の一般的な代数の同じ概念に似ています。 明確にしましょう: 最初に関係 r1 およびr2 r ⊆ r のような方法で互いに関連していた2、その後、XNUMXつの選択、投影、または名前変更演算子のいずれかを適用した後でも、この関係は保持されます。 講義5。関係代数。 二項演算 1.和集合、積集合、差の演算 どの操作にも独自の適用規則があり、式やアクションの意味が失われないように遵守する必要があります。 和、積、差の二項集合論演算は、必ず同じ関係スキーマを持つ XNUMX つの関係にのみ適用できます。 このような二項演算の結果は、演算の条件を満たすタプルで構成される関係になりますが、オペランドと同じ関係スキームを持ちます。 1。 結果 組合運営 XNUMX つの関係 r1(S) と r2(S)新しい関係がありますr3(S) 関係 r のタプルからなる1(S) と r2(S) 元の関係の少なくとも XNUMX つに属し、同じ関係スキーマを持つもの。 したがって、XNUMX つの関係の交点は次のようになります。 r3(S) = r1(S) r2(S) = {t(S) | t∈r1 ∪t∈r2}; わかりやすくするために、表に関する例を次に示します。 XNUMXつの関係を与えましょう: r1(S):
r2(S):
XNUMX 番目と XNUMX 番目のリレーションのスキームは同じですが、タプルの数が異なるだけです。 これら XNUMX つの関係の和集合は、関係 r になります。3(S)、これは次の表に対応します。 r3(S)= r1(S) r2(S):
したがって、リレーションSのスキーマは変更されておらず、タプルの数だけが増加しています。 2.次の二項演算の検討に移りましょう- 交差操作 XNUMX つの関係。 学校の幾何学からわかるように、結果の関係には、両方の関係 r に同時に存在する元の関係のタプルのみが含まれます。1(S) と r2(S)(繰り返しますが、同じ関係パターンに注意してください)。 XNUMX つのリレーションの交点の操作は次のようになります。 r4(S) = r1(S)∩r2(S)= {t(S)| t∈r1 & t ∈ r2}; 繰り返しになりますが、この操作がテーブルの形式で表された関係に与える影響を考えてみましょう。 r1(S):
r2(S):
関係rの共通部分による操作の定義によると1(S) と r2(S)新しい関係がありますr4(S)、そのテーブルビューは次のようになります。 r4(S) = r1(S)∩r2(S):
実際、最初と2番目の初期関係のタプルを見ると、それらの間で共通しているのは{b、XNUMX}だけです。 それは新しい関係rの唯一のタプルになりました4(S)。 3. 差演算 XNUMX つのリレーションは、前の操作と同様の方法で定義されます。 オペランドのリレーションは、前の操作と同様に、同じリレーション スキームを持つ必要があります。結果のリレーションには、XNUMX 番目のリレーションにない最初のリレーションのすべてのタプルが含まれます。つまり、 r5(S) = r1(S)\ r2(S)= {t(S)| t∈r1 &t∉r2}; すでによく知られている関係r1(S) と r2(S)、次のような表形式のビューで: r1(S):
r2(S):
5つの関係の共通部分の操作では、両方のオペランドを考慮します。 次に、この定義に従うと、結果の関係rXNUMX(S)は次のようになります。 r5(S) = r1(S)\ r2(S):
考慮される二項演算は基本的なものであり、他の演算、より複雑な演算はそれらに基づいています。 2.デカルト積と自然結合操作 デカルト積演算と自然結合演算は、積タイプのバイナリ演算であり、前述の XNUMX つの関係演算の結合に基づいています。 デカルト積演算の動作は多くの人に馴染みがあるように思われるかもしれませんが、それでも最初の演算よりも一般的なケースであるため、自然積演算から始めます。 したがって、自然な結合操作を検討してください。 このアクションのオペランドは、結合、交差、および名前変更の XNUMX つのバイナリ操作とは対照的に、さまざまなスキームとの関係である可能性があることにすぐに注意する必要があります。 異なる関係スキーム r を持つ XNUMX つの関係を考えると、1(S1) と r2(S2)、次にそれらの 天然化合物 新しい関係があるでしょう r3(S3)。これは、関係スキームの共通部分で一致するオペランドのタプルのみで構成されます。 したがって、新しい関係のスキームは、元の関係のスキームのいずれよりも大きくなります。これは、それらの接続、「接着」であるためです。 ちなみに、この「接着」が発生するXNUMXつのオペランド関係が同一のタプルは、 接続可能. データベース管理システムの式言語で自然結合操作の定義を書きましょう。 r3(S3)= r1(S1)xr2(S2)= {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2)∈r2}; 自然なつながり、その「接着」の働きをよく説明する例を考えてみましょう。 XNUMXつの関係r1(S1) と r2(S2)、表形式の表現では、それぞれ次のようになります。 r1(S1):
r2(S2):
これらの関係には、スキームSの交点で一致するタプルがあることがわかります。1 そして、S2 関係。 それらをリストしましょう: 1)関係rのタプル{a、1}1(S1)関係rのタプル{1、x}に一致します2(S2); 2)rからのタプル{b、1}1(S1) は、r のタプル {1, x} にも一致します2(S2); 3)タプル{c、3}はタプル{3、z}と一致します。 したがって、自然結合の下で、新しい関係r3(S3) は、これらのタプルを正確に「接着」することによって得られます。 そうそう3(S3) テーブル ビューでは次のようになります。 r3(S3)= r1(S1)xr2(S2):
それは定義によって判明します:スキームS3 スキームSと一致しません1、スキームSでも2、タプルを交差させてXNUMXつの元のスキーマを「接着」し、自然に結合しました。 自然な結合操作を適用するときにタプルがどのように結合されるかを図式的に示しましょう。 関係 r1 条件付きの形式があります:
そして比率r2 - 見る:
その場合、それらの自然な接続は次のようになります。
関係オペランドの「接着」は、例を考慮して、前に示したのと同じスキームに従って発生することがわかります。 操作 デカルト接続 自然結合操作の特殊なケースです。 より具体的には、関係に対するデカルト積演算の影響を考慮するとき、この場合、非交差関係スキームについてのみ話すことができると意図的に規定します。 両方の操作を適用した結果、オペランド関係のスキーマの結合に等しいスキーマとの関係が得られます。オペランドのスキーマは決して交差してはならないため、それらのタプルのすべての可能なペアのみが XNUMX つの関係のデカルト積になります。 したがって、前述の内容に基づいて、デカルト積演算の数式を記述します。 r4(S4)= r1(S1)xr2(S2)= {t(S1 ∪S2)| t [S1] ∈ r1 &t(S2)∈r2}、S1 ∩S2= ∅; 次に、デカルト積演算を適用したときに結果のリレーションシップ スキーマがどのようになるかを示す例を見てみましょう。 XNUMXつの関係r1(S1)およびr2(S2)、表形式で次のように表示されます。 r1(S1):
r2(S2):
したがって、関係のタプルはどれもrではないことがわかります。1(S1) と r2(S2)、実際、それらの交点は一致しません。 したがって、結果の関係 r4(S4) XNUMX 番目と XNUMX 番目のオペランド関係のタプルのすべての可能なペアが該当します。 得る: r4(S4)= r1(S1)xr2(S2):
新しい関係スキーム r を取得しました4(S4)前の場合のようにタプルを「接着」するのではなく、元のスキームの共通部分で一致しない可能性のあるすべての異なるタプルのペアを列挙することによって。 ここでも、自然結合の場合と同様に、デカルト積演算の動作の概略例を示します。 みましょう1 次のように設定します。
そして比率r2 与えられた:
次に、それらのデカルト積は次のように概略的に表すことができます。
このようにして、デカルト積演算を適用したときに結果の関係が得られます。 3.二項演算のプロパティ 和集合、共通部分、差、デカルト積、および自然結合のXNUMX項演算の上記の定義から、プロパティは次のようになります。 1. 単項演算の場合と同様に、最初のプロパティは次のことを示しています。 パワーウェイトレシオ 関係: 1)ユニオン操作の場合: |r1 ∪r2| ≤ |r1| + | r2|; 2)交差点操作の場合: |r1 ∩r2 | ≤ min(| r1|、|r2|); 3) 差分操作の場合: |r1 \r2| | ≤ |r1|; 4)デカルト積演算の場合: |r1 xr2| = | r1| | r2|; 5) 自然結合操作の場合: |r1 xr2| | ≤ |r1| | r2|. パワーの比率は、私たちが覚えているように、何らかの操作を適用した後、関係内のタプルの数がどのように変化するかを特徴づけます。 では、何が見えますか? 力 協会 XNUMX つの関係 r1 およびr2 元の関係オペランドのカーディナリティの合計よりも少ない。 なぜこうなった? 重要なのは、マージすると、一致するタプルが消え、互いに重なり合うということです。 したがって、この操作を実行した後に検討した例を参照すると、最初の関係では2つのタプルがあり、XNUMX番目の関係ではXNUMXつ、結果のXNUMXつ、つまりXNUMX未満(合計関係のカーディナリティ-オペランド)。 タプル{b、XNUMX}を一致させることにより、これらの関係は「接着」されます。 結果の力 交差点 XNUMXつのリレーションは、元のオペランドリレーションの最小カーディナリティ以下です。 この操作の定義に目を向けましょう。両方の初期関係に存在するタプルのみが、結果の関係に入ります。 これは、新しいリレーションのカーディナリティが、タプルの数がXNUMXつのうち最小であるリレーションオペランドのカーディナリティを超えることができないことを意味します。 また、カーディナリティの低いリレーションのすべてのタプルがXNUMX番目のリレーションオペランドのタプルと一致する場合は常に許可されるため、結果のパワーはこの最小カーディナリティに等しくなります。 操作の場合 違い すべてが非常に些細なことです。 実際、XNUMX番目の関係にも存在するすべてのタプルが最初の関係オペランドから「減算」されると、それらの数(およびその結果としてそれらのパワー)は減少します。 最初の関係の単一のタプルがXNUMX番目の関係のどのタプルとも一致しない場合、つまり「減算」するものがない場合、そのパワーは減少しません。 興味深いことに、操作の場合 デカルト積 結果の関係の累乗は、XNUMXつのオペランド関係の累乗の積に正確に等しくなります。 元の関係のタプルの可能なすべてのペアが結果に書き込まれ、何も除外されないため、これが発生することは明らかです。 そして最後に、操作 自然なつながり XNUMXつの元の関係の累乗の積以上の累乗の関係が取得されます。 繰り返しますが、これは、オペランドの関係が一致するタプルによって「接着」され、一致しないものが結果から完全に除外されるために発生します。 2. べき等性: 1)ユニオン操作の場合:r∪r= r; 2)交差操作の場合:r∩r= r; 3)差分演算の場合:r\r≠r; 4) デカルト積演算の場合 (一般的な場合、プロパティは適用されません)。 5) 自然結合演算の場合: rxr = r。 興味深いことに、冪等性は上記のすべての演算に当てはまるわけではなく、デカルト積の演算にはまったく当てはまりません。 確かに、自分自身との関係を組み合わせたり、交差したり、自然に接続したりすると、それは変わりません。 しかし、それと正確に等しいリレーションから減算すると、結果は空のリレーションになります。 3. 可換性: 1)ユニオン操作の場合: r1 ∪r2 = r2 ∪r1; 2)交差点操作の場合: r ∩ r = r ∩ r; 3) 差分操作の場合: r1 \r2 ≠r2 \r1; 4)デカルト積演算の場合: r1 xr2 = r2 xr1; 5) 自然結合操作の場合: r1 xr2 = r2 xr1. 可換性は、差分演算を除くすべての演算に適用されます。 これは、それらの構成(タプル)が場所の関係の再配置から変更されないため、理解しやすいです。 また、差分演算を適用する場合、どのオペランド関係が最初に来るかが重要です。これは、どの関係のどのタプルが参照として使用されるか、つまり、他のタプルと比較されて除外されるタプルに依存するためです。 4. 結合性プロパティ: 1)ユニオン操作の場合: (r1 ∪r2)∪r3 = r1 ∪(r2 ∪r3); 2)交差点操作の場合: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) 差分操作の場合: (r1 \r2)\r3 ≠r1 \(r2 \r3); 4)デカルト積演算の場合: (r1 xr2)xr3 = r1 x(r2 xr3); 5) 自然結合操作の場合: (r1 xr2)xr3 = r1 x(r2 xr3). また、差分操作を除くすべての操作に対してプロパティが実行されることがわかります。 これは、可換性を適用する場合と同じように説明されます。 概して、結合、交差、差、および自然結合の操作は、オペランド関係の順序を気にしません。 しかし、関係が互いに「奪われる」と、秩序が支配的な役割を果たします。 上記の特性と推論に基づいて、次の結論を導き出すことができます。最後のXNUMXつの特性、つまりべき等性、可換性、結合性の特性は、XNUMXつの関係の差の演算を除いて、検討したすべての演算に当てはまります。 、示されたXNUMXつのプロパティのいずれもまったく満たされておらず、XNUMXつのケースでのみプロパティが適用できないことが判明しました。 4. 接続操作オプション 選択、射影、改名の単項演算と、和、積、差、直積、自然結合の二項演算を基本として(これらはすべて一般に 接続操作)、上記の概念と定義を使用して派生した新しい操作を導入できます。 このアクティビティはコンパイルと呼ばれます。 結合操作オプション. このような結合操作の最初のバリアントは、次の操作です。 内部接続 指定された接続条件に従います。 ある特定の条件による内部結合の操作は、デカルト積および選択操作からの派生操作として定義されます。 この操作の公式定義を書きます。 r1(S1) NS P r2(S2)=σ (r1 xr2)、S1 ∩S2 = ∅; ここで P = P<S1 ∪S2> - 元の関係オペランドの XNUMX つのスキームの和集合に課される条件。 関係 r からタプルが選択されるのは、この条件によるものです。1 およびr2 結果の関係に。 内部結合操作は、異なる関係スキーマを持つ関係に適用できることに注意してください。 これらのスキームはどのようなものでもかまいませんが、交差してはなりません。 内部結合演算の結果である元のオペランド関係のタプルは、と呼ばれます。 結合可能なタプル. 内部結合操作の操作を視覚的に説明するために、次の例を示します。 XNUMX つの関係 r が与えられたとしましょう1(S1) と r2(S2) 異なる関係スキーム: r1(S1):
r2(S2):
次の表は、条件 P = (b1 = b2) に内部結合演算を適用した結果を示しています。 r1(S1) NS P r2(S2):
したがって、リレーションシップを表す 1 つのテーブルの「接着」は、内部結合操作 P = (b2 = bXNUMX) の条件が満たされるタプルに対して正確に発生したことがわかります。 これで、すでに導入した内部結合操作に基づいて、操作を導入できます。 左アウタージョイン и 右外部結合。 説明しましょう。 左外部結合操作の結果は、内部結合の結果であり、左ソース関係オペランドの結合不可能なタプルで完了します。 同様に、右外部結合操作の結果は、右手系ソース関係オペランドの結合不可能なタプルで増補された内部結合操作の結果として定義されます。 左右の外部結合の操作の結果の関係がどのように補充されるかという問題は、かなり予想されます。 XNUMX つの関係オペランドのタプルは、別の関係オペランドのスキーマで補完されます ヌル値. このように導入された左右の外部結合操作は、内部結合操作から派生した操作であることに注意してください。 左右の外部結合操作の一般的な式を書き留めるために、いくつかの追加の構造を実行します。 XNUMX つの関係 r が与えられたとしましょう1(S1) と r2(S2) 異なるスキームの関係 S1 そして、S2、互いに交差しません。 左と右の内部結合操作は導関数であることを既に規定しているため、左外部結合操作を決定するための次の補助式を取得できます。 1) r3 (S2 ∪S1) ≔ r1(S1) NS Pr2(S2); r 3 (S2 ∪S1) は単にリレーション r の内部結合の結果です1(S1) と r2(S2)。 左外部結合は内部結合の派生操作です。 2) r4(S1) ≔ r 3(S2 ∪S1)[S1]; したがって、単項射影演算の助けを借りて、左の初期関係のすべての結合可能なタプルを選択しました-オペランドr1(S1)。 結果はrと指定されます4(S1) 使いやすさのため。 3) r5 (S1) ≔ r1(S1)\r4(S1); ここでr1(S1) はすべて左ソース関係オペランドのタプルであり、r4(S1)-接続されているだけの独自のタプル。 したがって、rに関して、差の二項演算を使用します。5(S1) 左オペランド関係のすべての結合不可能なタプルを取得しました。 4) r6(S2)≔{∅(S2)}; {∅(S2)} は、スキーマ (S2)タプルをXNUMXつだけ含み、Null値で構成されます。 便宜上、この比率をrと表記しました。6(S2); 5) r7 (S2 ∪S1) ≔ r5(S1)xr6(S2); ここでは、左オペランド関係の接続されていないタプルを取得しました(r5(S1)) XNUMX番目の関係オペランドSのスキームでそれらを補足しました2 ヌル値、つまりデカルトは、これらの同じ結合不可能なタプルで構成される関係に関係rを掛けました6(S2)パラグラフXNUMXで定義されています。 6) r1(S1)→× P r2(S2)≔(r1 x P r2)∪r7 (S2 ∪S1); これは 左アウタージョイン、見てわかるように、元の関係オペランド r のデカルト積の和集合によって得られます。1 およびr2 と関係r7 (S2 ∪ S1) パラグラフ XNUMX で定義されています。 これで、左外部結合の操作だけでなく、類推によって右外部結合の操作を決定するために必要なすべての計算ができました。 そう: 1)操作 左アウタージョイン 厳密な形式では、次のようになります。 r1(S1)→× P r2(S2)≔(r1 x P r2) ∪ [(r1 \(r1 x P r2)[S1])×{∅(S2)}]; 2)操作 右外部結合 左外部結合操作と同様の方法で定義され、次の形式を持ちます。 r1(S1)→× P r2(S2)≔(r1 x P r2) ∪ [(r2 \(r1 x P r2)[S2])×{∅(S1)}]; これら XNUMX つの派生操作には、言及する価値のあるプロパティが XNUMX つだけあります。 1.可換性の性質: 1)左外部結合操作の場合: r1(S1)→× P r2(S2) ≠ r2(S2)→× P r1(S1); 2)右外部結合操作の場合: r1(S1) ←× P r2(S2) ≠ r2(S2) ←× P r1(S1) したがって、一般的な形式では、これらの操作の可換性は満たされていませんが、同時に、左右の外部結合の操作は相互に逆です。つまり、次のことが当てはまります。 1)左外部結合操作の場合: r1(S1)→× P r2(S2)= r2(S2)→× P r1(S1); 2)右外部結合操作の場合: r1(S1) ←× P r2(S2)= r2(S2) ←× Pr1(S1). 2.左右の外部結合操作の主な特性は、次のことを可能にすることです。 復元する 特定の結合操作の最終結果に応じた初期関係オペランド、つまり、以下が実行されます。 1)左外部結合操作の場合: r1(S1) = (r1 →× P r2)[S1]; 2)右外部結合操作の場合: r2(S2)=(r1 ←× P r2)[S2]. したがって、最初の元の関係オペランドは、左右の結合操作の結果から、より具体的には、この結合の結果に適用することによって復元できることがわかります(r1 xr2)スキームSへの射影の単項演算1、 [NS1]. 同様に、XNUMX 番目の元の関係オペランドは、右外部結合 (r1 xr2)関係Sのスキームへの射影の単項演算2. 左右の外部結合の操作の操作をより詳細に検討するための例を示しましょう。 すでにおなじみの関係を紹介しましょうr1(S1) と r2(S2) 異なる関係スキーム: r1(S1):
r2(S2):
左関係オペランド r の結合不可能なタプル2(S2) はタプル {d, 4} です。 定義に従って、XNUMX つの初期関係オペランドの内部接続の結果を補足するのは彼らです。 リレーション r の内部結合条件1(S1) と r2(S2) また、同じままにします: P = (b1 = b2). 次に、操作の結果 左アウタージョイン 次の表があります。 r1(S1)→× P r2(S2):
実際、ご覧のとおり、左外部結合の操作の影響の結果として、内部結合操作の結果は、左の結合不可能なタプルで補充されました。つまり、この場合、最初の関係-オペランド。 XNUMX 番目 (右) のソース関係オペランドのスキームでのタプルの補充は、定義上、Null 値の助けを借りて行われました。 そして、結果に似ています 右外部結合 前と同じように、元の関係オペランド r の条件 P = (b1 = b2)1(S1) と r2(S2)は次の表です。 r1(S1) ←× P r2(S2):
実際、この場合、内部結合操作の結果は、右側の結合不可能なタプル (この場合は XNUMX 番目の最初の関係オペランド) で補充する必要があります。 このようなタプルは、見るのが難しくないので、XNUMX 番目の関係 r2(S2)2つ、つまり{XNUMX、y}。 次に、右外部結合の演算の定義に基づいて、最初のオペランドのスキームの最初の(左)オペランドのタプルをNull値で補足します。 最後に、上記の結合操作の XNUMX 番目のバージョンを見てみましょう。 完全外部結合操作. この操作は、内部結合操作から派生した操作としてだけでなく、左右の外部結合操作の和集合と見なすこともできます。 完全外部結合操作 左と右の両方の初期オペランド関係の結合不可能なタプルを使用して、同じ内部結合 (左と右の外部結合の定義の場合と同様) を完了した結果として定義されます。 この定義に基づいて、この定義の公式形式を示します。 r1(S1) ↔x P r2(S2)=(r1 →× P r2)∪(r1 ←× P r2); 完全外部結合操作にも、左および右外部結合操作と同様のプロパティがあります。 完全外部結合操作の本来の相反する性質 (結局のところ、左右の外部結合操作の和集合として定義されていた) のみにより、次のように実行されます。 可換性: r1(S1) ↔x P r2(S2)= r2(S2) ↔ × P r1(S1); 結合操作のオプションの検討を完了するために、完全な外部結合操作の操作を示す例を見てみましょう。 XNUMX つの関係 r を紹介します1(S1) と r2(S2)および結合条件。 みましょう r1(S1)
r2(S2):
そして、関係の接続条件を r1(S1) と r2(S2) は、前の例のように、P = (b1 = b2) になります。 次に、関係 r の完全外部結合操作の結果1(S1) と r2(S2)条件P =(b1 = b2)により、次の表が作成されます。 r1(S1) ↔x P r2(S2):
したがって、完全外部結合操作は、左右の外部結合操作の結果の結合としての定義を明確に正当化することがわかります。 結果として得られる内部結合操作の関係は、左側のように同時に結合できないタプルによって補完されます(first、r1(S1))、および右(XNUMX番目、r2(S2))元の関係のオペランド。 5.微分演算 したがって、結合操作のさまざまな変形、つまり、内部結合、左結合、右結合、および完全外部結合の操作を検討しました。これらは、リレーショナル代数の元の XNUMX つの操作の派生物です。和、交点、差、デカルト積、自然結合。 しかし、これらの元の操作の中にも派生的な操作の例があります。 1.例えば、操作 交差点 XNUMX つの比率は、同じ XNUMX つの比率の差の演算の導関数です。 見せてみましょう。 交差操作は、次の式で表すことができます。 r1(S)∩r2(S) = r1 \r1 \r2 または、同じ結果が得られます。 r1(S)∩r2(S) = r2 \r2 \r1; 2.別の例として、XNUMXつの元の操作からの基本操作の派生物は次の操作です。 自然なつながり。 最も一般的な形式では、この演算はデカルト積のXNUMX項演算と、属性の選択、射影、および名前変更の単項演算から派生します。 ただし、次に、内部結合演算は、デカルト積の関係の同じ演算の微分演算です。 したがって、自然結合操作が派生操作であることを示すために、次の例を検討してください。 自然結合操作と内部結合操作の前の例を比較してみましょう。 XNUMX つの関係 r が与えられたとしましょう1(S1) と r2(S2) オペランドとして機能します。 それらは等しい: r1(S1):
r2(S2):
すでに前に受け取ったように、これらの関係の自然結合操作の結果は、次の形式のテーブルになります。 r3(S3) ≔ r1(S1)xr2(S2):
そして、同じ関係 r の内部結合の結果1(S1) と r2(S2)条件P =(b1 = b2)により、次の表が作成されます。 r4(S4) ≔ r1(S1) NS P r2(S2):
これらXNUMXつの結果を比較してみましょう。結果として得られる新しい関係r3(S3) と r4(S4). 自然結合操作が内部結合操作によって表現されることは明らかですが、最も重要なのは、特別な形式の結合条件です。 内部結合操作の派生物としての自然結合操作のアクションを記述する数式を書きましょう。 r1(S1)xr2(S2)= {ρ<ϕ1> r1 x E ρ<ϕ2>r2}[S1 ∪S2], どこで E - 接続状態 タプル; E=∀a∈S1 ∩S2 [IsNull(b1)&IsNull(2)∪b1= b2]; b1 = φ1 (名前(a))、b2 = φ2 (名前(a)); これがそのXNUMXつです 名前変更機能 ϕ1 は同一であり、別の名前変更関数(つまり、ϕ2)スキーマが交差する属性の名前を変更します。 タプルの接続条件 E は、Null 値の発生の可能性を考慮して、一般的な形式で記述されます。これは、(前述のように) 内部結合操作が XNUMX つの関係のデカルト積の操作から派生した操作であるためです。単項選択操作。 6. 関係代数の表現 前述の関係代数の式と操作が、さまざまなデータベースの実際の操作でどのように使用できるかを示しましょう。 たとえば、いくつかの商用データベースのフラグメントを自由に使えるようにしましょう。 サプライヤー (サプライヤーコード、ベンダー名、ベンダー都市); ツール (ツールコード、ツール名、...); 配達 (サプライヤーコード、部品コード); 下線の付いた属性名[1] は、それぞれ独自の関係にある重要な (つまり、識別する) 属性です。 このデータベースの開発者およびこの主題に関する情報の管理者として、これらのサプライヤがツールを提供しない場合に、サプライヤの名前(サプライヤ名)とその場所(サプライヤシティ)を取得するように指示されたとします。総称「プライヤー」。 おそらく非常に大規模なデータベースでこの要件を満たすすべてのサプライヤーを決定するために、リレーショナル代数のいくつかの式を記述します。 1. 「サプライヤー」と「サプライズ」の関係の自然なつながりを形成し、各サプライヤーと、彼が提供する部品のコードを一致させます。 新しい関係 - 自然結合の操作を適用した結果 - さらなる適用の便宜上、r で表します1. サプライヤー x 供給量 ≔ r1 (サプライヤーコード、サプライヤー名、サプライヤー都市、 括弧内に、この自然な結合操作に関係する関係のすべての属性をリストしました。 「Vendor ID」属性が重複していることがわかりますが、取引概要レコードでは、各属性名は XNUMX 回だけ表示されます。 サプライヤー x 供給量 ≔ r1 (サプライヤーコード、サプライヤー名、サプライヤー都市、機器コード); 2.再び自然なつながりを形成しますが、今回はパラグラフXNUMXで得られた関係と楽器の関係だけです。 これは、このツールの名前を前の段落で取得した各ツールコードと一致させるために行います。 r1 x ツール [ツールコード、ツール名] ≔ r2 (サプライヤーコード、サプライヤー名、サプライヤー都市、 結果は r で表されます。2、重複する属性は除外されます: r1 x ツール [ツールコード、ツール名] ≔ r2 (サプライヤーコード、サプライヤー名、サプライヤー都市、機器コード、機器名); Tools リレーションから「Tool Code」と「Tool Name」の XNUMX つの属性のみを取得することに注意してください。 これを行うには、関係 r の表記からわかるように、2、単項射影演算を適用しました:ツール[ツールコード、ツール名]、つまり、関係ツールがテーブルの形式で提示された場合、この射影演算の結果は、見出しが「ツールコード」の最初のXNUMX列になります。と「ツール名」それぞれ「。 すでに検討した最初のXNUMXつのステップは非常に一般的であることに注意してください。つまり、他の要求を実装するために使用できます。 しかし、次のXNUMXつのポイントは、私たちの前に設定された特定のタスクを達成するための具体的なステップを表しています。 3.比率rに関して<"ツール名"="ペンチ"という条件で単項選択演算を書く2前の段落で取得しました。 そして、これらの属性のすべての値を取得するために、この操作の結果に単項射影操作[サプライヤーコード、サプライヤー名、サプライヤー都市]を適用します。これは、に基づいてこの情報を取得する必要があるためです。注文。 だから: (σ<工具名=「ペンチ」> r2)[サプライヤーコード、サプライヤー名、サプライヤー都市]≔r3 (仕入先コード、仕入先名、仕入先都市、工具コード、工具名)。 結果として得られる比率では、rで表されます3、それらのサプライヤー(すべての識別データを含む)のみが、一般名「プライヤー」のツールを提供することが判明しました。 しかし、注文のおかげで、逆にそのようなツールを提供しないサプライヤーを特定する必要があります。 したがって、アルゴリズムの次のステップに進み、最後のリレーショナル代数式を書き留めます。これにより、探している情報が得られます。 4.まず、「サプライヤー」の比率と比率rの差をつけましょう。3、この二項演算を適用した後、「仕入先名」属性と「仕入先都市」属性に単項射影演算を適用します。 (サプライヤー\r3) [サプライヤー名、サプライヤー都市] ≔ r4 (サプライヤーコード、サプライヤー名、サプライヤー都市); 結果はrと指定されます4、この関係には、注文の条件に対応する元の「サプライヤー」関係のタプルのみが含まれていました。 そこで、関係代数の式と演算を使用して、任意のデータベースであらゆる種類のアクションを実行したり、さまざまな順序を実行したりする方法を示しました。 第6回 SQL言語 まず、歴史的背景を少し説明しましょう。 データベースと対話するように設計された SQL 言語は、1970 年代半ばに登場しました。 (最初の出版は 1974 年にさかのぼります) であり、実験的なリレーショナル データベース管理システム プロジェクトの一環として IBM によって開発されました。 言語の元の名前は SEQUEL (構造化された English クエリ言語) - この言語の本質を部分的にしか反映していません。 当初、その発明直後と SQL 言語の運用の初期段階では、その名前は「Structured Query Language」と訳される「Structured Query Language」というフレーズの省略形でした。 もちろん、この言語は主に、ユーザーにとって便利で理解しやすいリレーショナル データベースへのクエリの作成に重点を置いていました。 しかし、実際には、ほとんど最初から完全なデータベース言語であり、クエリを作成してデータベースを操作する手段に加えて、次の機能を提供します。 1) データベーススキーマを定義および操作する手段。 2) 完全性制約とトリガーを定義する手段 (後述)。 3) データベース ビューを定義する手段。 4) 要求の効率的な実行をサポートする物理層構造を定義する手段。 5) リレーションとそのフィールドへのアクセスを許可する手段。 この言語には、並列トランザクション側からデータベース オブジェクトへのアクセスを明示的に同期する手段がありませんでした。最初から、必要な同期はデータベース管理システムによって暗黙的に実行されると想定されていました。 現在、SQL は省略形ではなく、独立した言語の名前です。 また、現在、構造化クエリ言語は、すべての商用リレーショナル データベース管理システムと、元はリレーショナル アプローチに基づいていなかったほぼすべての DBMS に実装されています。 すべての製造会社は、自社の実装が SQL 標準に準拠していると主張しており、実際、構造化照会言語の実装された方言は非常に近いものです。 これはすぐには達成されませんでした。 SQL の既存の方言を比較することを困難にしている最新の商用データベース管理システムの特徴は、言語の統一された記述がないことです。 通常、説明はさまざまなマニュアルに散らばっており、構造化クエリ言語に直接関係のないシステム固有の言語機能の説明と混在しています。 それにもかかわらず、SQL ステートメントの基本セット (データベース スキーマの決定、データのフェッチと操作、データ アクセスの承認、プログラミング言語への SQL の埋め込みのサポート、および動的 SQL ステートメントを含む) は、十分に確立されていると言えます。商用実装であり、多かれ少なかれ標準に準拠しています。 時間をかけて構造化照会言語に取り組み、データ検索ステートメントの構文とセマンティクス、データ操作、およびデータベース整合性制約の修正を明確に標準化するための標準を達成することができました。 リレーションシップの主キーと外部キー、およびいわゆる整合性チェック制約を定義するための手段が指定されています。これらは、即時にチェックされる SQL 整合性制約のサブセットです。 外部キーを定義するためのツールを使用すると、いわゆるデータベースの参照整合性の要件を簡単に定式化できます (これについては後で説明します)。 リレーショナル データベースで一般的なこの要件は、SQL 整合性制約の一般的なメカニズムに基づいて定式化することもできますが、外部キーの概念に基づく定式化はより単純で理解しやすいものです。 したがって、これらすべてを考慮すると、現在、構造化クエリ言語はXNUMXつの言語の名前だけでなく、言語のクラス全体の名前です。これは、既存の標準にもかかわらず、構造化クエリ言語のさまざまな方言が実装されているためです。さまざまなデータベース管理システムで、もちろん、XNUMXつの共通の基盤があります。 1. Selectステートメントは、構造化照会言語の基本ステートメントです。 SQL 構造化クエリ言語の中心は、データベースを操作する際に最も要求の厳しい操作であるクエリを実装する Select ステートメントによって占められています。 Select 演算子は、関係代数式と疑似関係代数式の両方を評価します。 このコースでは、すでに説明した関係代数の単項および二項演算のみの実装と、いわゆるサブクエリを使用したクエリの実装について検討します。 ちなみに、関係代数演算を使用する場合、結果の関係に重複するタプルが表示される可能性があることに注意してください。 構造化クエリ言語のルールのリレーションに重複行が存在することを厳密に禁止することはないため(通常の関係代数とは異なり)、結果から重複を除外する必要はありません。 それでは、Select ステートメントの基本構造を見てみましょう。 これは非常に単純で、次の標準的な必須フレーズが含まれています。 選択... から... どこ... ; 各行の省略記号の代わりに、特定のデータベースの関係、属性、条件、およびそのデータベースのタスクを指定する必要があります。 最も一般的なケースでは、基本的な Select 構造は次のようになります。 選択 いくつかの属性を選択します そのような関係から 場所 タプルをサンプリングするためのそのような条件で したがって、リレーションシップ スキーム (いくつかの列の見出し) から属性を選択し、どのリレーションシップ (ご覧のとおり、いくつかある場合もあります) から選択を行い、最後に、どの条件に基づいて停止するかを示します。特定のタプルに対する私たちの選択。 属性の参照はそれらの名前を使用して行われることに注意することが重要です。 したがって、次が得られます。 仕事のアルゴリズム この基本的な Select ステートメント: 1) リレーションからタプルを選択するための条件が記憶されます。 2)指定されたプロパティを満たすタプルがチェックされます。 そのようなタプルは記憶されています。 3)Selectステートメントの基本構造の最初の行にリストされている属性とその値が出力されます。 (関係の表形式について説明すると、テーブルのそれらの列が表示され、その見出しは必要な属性としてリストされています。もちろん、列は完全には表示されず、それぞれにそれらのタプルのみが表示されます。指定された条件を満たすものは残ります。) 例を考えてみましょう。 次の関係rが与えられたとしましょう1、いくつかの書店データベースのフラグメントとして:
Select ステートメントで次の式も指定されているとします。 選択 本のタイトル、本の著者 r1 場所 書籍価格>200; この演算子の結果は、次のタプル フラグメントになります。 (携帯電話、S。キング)。 (以下では、この基本構造を使用したクエリ実装の多くの例を検討し、そのアプリケーションを詳細に検討します。) 2. 構造化照会言語の単項演算 このセクションでは、選択、射影、および名前変更のすでにおなじみの単項演算が、Select演算子を使用して構造化照会言語でどのように実装されるかを検討します。 以前は個々の操作しか操作できなかった場合、一般的なケースではXNUMXつのSelectステートメントでも、XNUMXつの操作だけでなく、リレーショナル代数式全体を定義できることに注意してください。 それでは、構造化クエリの言語での単項演算の表現の分析に直接進みましょう。 1. サンプリング動作. SQLでの選択操作は、次の形式のSelectステートメントによって実装されます。 選択 すべての属性 関係名 場所 選択条件; ここでは、「すべての属性」を記述する代わりに、「*」記号を使用できます。 構造化照会言語理論では、このアイコンは、関係スキーマからすべての属性を選択することを意味します。 ここでの (および演算の他のすべての実装における) 選択条件は、標準接続詞 not (not)、および (and)、または (or) を使用した論理式として記述されます。 関係属性は、その名前で参照されます。 例を考えてみましょう。 次の関係スキームを定義しましょう。 学業成績(成績表番号、学期、科目コード、評価、日付); ここで、前述のように、下線の付いた属性が関係キーを形成します。 単項選択操作を実装する次の形式の Select ステートメントを作成しましょう。 選択* 学業成績から 成績表#=100および学期=6の場合。 このオペレーターの結果として、機械は第 XNUMX 学期の記録数 XNUMX で学生の進行状況を表示することは明らかです。 2. 投影操作. 構造化照会言語の射影操作は、フェッチ操作よりも実装がさらに簡単です。 射影操作を適用する場合、(選択操作を適用する場合のように) 行が選択されるのではなく、列が選択されることを思い出してください。 したがって、余分な条件を指定せずに、必要な列のヘッダー (つまり、属性名) をリストするだけで十分です。 合計すると、次の形式の演算子が得られます。 選択 属性名のリスト 関係名; このステートメントを適用すると、マシンは、この Select ステートメントの最初の行で名前が指定されたリレーション テーブルの列を返します。 前に述べたように、結果の関係から重複する行と列を除外する必要はありません。 ただし、注文またはタスクで重複を排除する必要がある場合は、構造化クエリ言語の特別なオプションを使用する必要があります- 明確な. このオプションは、重複するタプルをリレーションから自動的に削除するように設定します。 このオプションを適用すると、Select ステートメントは次のようになります。 選択 属性名の個別のリスト 関係名; SQL では、式のオプションの要素に対する特別な表記法 (角括弧 [...]) があります。 したがって、最も一般的な形式では、射影操作は次のようになります。 選択 [個別]属性名のリスト 関係名; ただし、操作を適用した結果に重複が含まれないことが保証されている場合、または重複が許容される場合は、オプション 明確な オペレーターのパフォーマンス上の理由から、レコードが乱雑にならないように指定しない方がよいでしょう。 重複がない場合に XNUMX% の信頼性が得られる可能性を示す例を考えてみましょう。 すでに知られている関係のスキームが与えられます。 学業成績(成績表番号、学期、科目コード、評価、日付)。 次のSelectステートメントを指定します。 選択 成績表番号、学期、科目コード 学業成績; ここで、オペレーターによって返されるXNUMXつの属性がリレーションのキーを形成していることが簡単にわかります。 そのため、オプション 明確な 重複がないことが保証されているため、冗長になります。 これは、一意の制約と呼ばれるキーの要件に基づいています。 このプロパティについては後で詳しく説明しますが、属性がキーである場合、重複はありません。 3. 名前変更操作. 構造化照会言語で属性の名前を変更する操作は非常に簡単です。 つまり、実際には次のアルゴリズムによって具体化されます。 1) Select 句の属性名のリストに、名前を変更する必要がある属性がリストされています。 2) 指定された各属性に追加される特別なキーワード as。 3)asという単語が出現するたびに、対応する属性の名前が示されます。これには、元の名前を変更する必要があります。 したがって、上記のすべてを考慮すると、属性の名前変更の操作に対応するステートメントは次のようになります。 選択 属性名 1 を新しい属性名 1 として、... 関係名; この演算子がどのように機能するかを例で示しましょう。 すでに私たちに馴染みのある関係スキームを与えましょう: 学業成績(成績表番号、学期、科目コード、評価、日付); いくつかの属性の名前を変更するように命令しましょう。つまり、「帳簿番号」の代わりに「口座番号」があり、「スコア」の代わりに「スコア」があるはずです。 この名前変更操作を実装する Select ステートメントがどのようになるかを書き留めましょう。 選択 成績表番号としての成績表、学期、件名コード、スコアとしての成績、日付 学業成績; したがって、この演算子を適用した結果は、元の「達成」関係スキーマとは XNUMX つの属性の名前が異なる新しい関係スキーマになります。 3.構造化クエリの言語での二項演算 単項演算と同様に、二項演算にも構造化クエリ言語またはSQLで独自の実装があります。 それで、私たちがすでに渡した二項演算のこの言語での実装、すなわち、和集合、共通部分、差分、直積、自然結合、内側と左、右、完全外側結合の操作を考えてみましょう。 1. ユニオン操作. XNUMXつのリレーションを組み合わせる操作を実装するには、XNUMXつのSelect演算子を同時に使用する必要があります。各演算子は、元のリレーションオペランドのXNUMXつに対応します。 そして、これらXNUMXつの基本的なSelectステートメントに特別な操作を適用する必要があります Union。 上記のすべてを考慮して、構造化クエリ言語のセマンティクスを使用して、ユニオン操作がどのように見えるかを書き留めましょう。 選択 リレーション 1 の属性名をリストする 関係名1 Union 選択 リレーション 2 の属性名をリストする 関係名 2; 結合される XNUMX つの関係の属性名のリストは、互換性のあるタイプの属性を参照し、一貫した順序でリストされている必要があることに注意してください。 この要件が満たされていない場合、リクエストは実行されず、コンピューターにエラー メッセージが表示されます。 しかし、注目すべき興味深い点は、これらの関係における属性自体の名前が異なる可能性があることです。 この場合、結果のリレーションには、最初のSelectステートメントで指定された属性名が割り当てられます。 また、Union操作を使用すると、結果のリレーションからすべての重複するタプルが自動的に除外されることを知っておく必要があります。 したがって、Union操作の代わりに、重複するすべての行を最終結果に保持する必要がある場合は、この操作の変更を使用する必要があります-操作 ユニオンオール。 この場合、XNUMXつの関係を組み合わせる操作は次のようになります。 選択 リレーション 1 の属性名をリストする 関係名1 ユニオンオール 選択 リレーション 2 の属性名をリストする 関係名 2; この場合、重複するタプルは結果のリレーションから削除されません。 Selectステートメントのオプション要素とオプションについて前述の表記法を使用して、構造化クエリ言語でXNUMXつのリレーションを結合する操作の最も一般的な形式を記述します。 選択 リレーション 1 の属性名をリストする 関係名1 ユニオン[すべて] 選択 リレーション 2 の属性名をリストする 関係名 2; 2.交差点操作. 構造化クエリ言語での共通部分の操作とXNUMXつの関係の差の操作は、同様の方法で実装されます(最も単純な表現方法を検討します。これは、方法が単純であるほど、経済的で、関連性が高く、したがって、最も単純な方法であるためです。需要がある)。 そこで、を使用して交差操作を実装する方法を分析します。 キーの. このメソッドには XNUMX つの Select 構造の参加が含まれますが、(和集合操作の表現のように) それらは等しくなく、そのうちの XNUMX つは、いわば「サブ構造」、「サブサイクル」です。 そのような演算子は通常呼び出されます サブクエリ. では、XNUMX つの関係スキーム (R1 そしてR2)、大まかに次のように定義されます。 R1 (鍵、...) そして R2 (鍵、...); この操作を記録するときは、特別なオプションも使用します in、これは文字通り「in」または(この特定の場合のように)「containedin」を意味します。 したがって、上記のすべてを考慮して、構造化クエリ言語を使用した XNUMX つの関係の交差の操作は次のように記述されます。 選択 * R1 場所 キー入力 (選択 ключ Rから2); したがって、この場合のサブクエリは括弧内の演算子になることがわかります。 この場合のこのサブクエリは、リレーションRのキー値のリストを返します2. そして、演算子の表記と選択条件の分析から次のように、関係 R のタプルのみが結果の関係に分類されます。1、そのキーはリレーションRのキーのリストに含まれています2. つまり、最後のリレーションでは、XNUMX つのリレーションの交差の定義を思い出すと、両方のリレーションに属するタプルのみが残ります。 3. 差分演算. 前述のように、XNUMX つの関係の差の単項演算は、交差の演算と同様に実装されます。 ここでは、Select 演算子を使用したメイン クエリに加えて、XNUMX 番目の補助クエリ、いわゆるサブクエリが使用されます。 ただし、前の操作の実装とは異なり、差分操作を実装する場合は、別のキーワードを使用する必要があります。 ありませんで、これは、直訳では「含まれていない」または(検討中のケースでは翻訳するのが適切であるため)-「含まれていない」を意味します。 前の例のように、XNUMX つの関係スキーム (R1 そしてR2)、おおよそ次の式で与えられます。 R1 (鍵、...) そして R2 (鍵、...); ご覧のとおり、これらのリレーションの属性の中でキー属性が再び設定されます。 したがって、構造化クエリ言語で差分操作を表すために、次の形式が得られます。 選択* R1 場所 ключ ありませんで (選択 ключ R2); したがって、関係 R のタプルのみ1、そのキーは関係 R のキーのリストに含まれていません2. 表記を文字どおりに考えると、関係 R から1 比率Rを「差し引いた」2。 ここから、この演算子の選択条件が正しく記述され(結局、XNUMXつの関係の差の定義が実行される)、交差操作の実装の場合のようにキーの使用が完全に正当化されると結論付けます。 。 私たちが見た「キーメソッド」のXNUMXつの使用法が最も一般的です。 これで、関係を表す演算子の構築におけるキーの使用の研究は終わりです。 関係代数の残りのすべての二項演算は、他の方法で記述されます。 4.デカルト積の操作 以前の講義で覚えているように、XNUMXつの関係オペランドのデカルト積は、属性上のタプルの名前付き値のすべての可能なペアのセットとして構成されています。 したがって、構造化照会言語では、デカルト積演算は、キーワードで示されるクロス結合を使用して実装されます。 クロスジョイン、文字通り「交差結合」または「交差結合」に変換されます。 構造体には、構造化照会言語でデカルト積演算を表すSelect演算子がXNUMXつだけあり、次の形式になっています。 選択* R1 クロスジョイン R2 ここでR1 そしてR2 - 初期関係オペランドの名前。 オプション クロスジョイン 結果のリレーションには、リレーション タプル R のすべてのペアに対応するすべての属性 (演算子の最初の行に "*" 記号があるため、すべて) が含まれます。1 そしてR2. デカルト積演算の実装のXNUMXつの機能を覚えておくことは非常に重要です。 この機能は、デカルト積の二項演算の定義の結果です。 それを思い出してください: r4(S4)= r1(S1)xr2(S2)= {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2)∈r2}、S1 ∩S2= ∅; 上記の定義からわかるように、タプルのペアは、必然的に交差しない関係スキームで形成されます。 したがって、SQL構造化照会言語で作業する場合、初期オペランド関係の属性名が一致しないように常に規定されています。 ただし、これらの関係の名前が同じである場合は、属性の名前変更操作を使用して現在の状況を簡単に解決できます。つまり、このような場合は、オプションを使用するだけです。 as、前述のとおりです。 同じ属性名のいくつかを持つXNUMXつの関係のデカルト積を見つける必要がある例を考えてみましょう。 したがって、次の関係が与えられます。 R1 (A、B)、 R2 (紀元前); R属性が1.BおよびR2.B は同じ名前です。 これを念頭に置いて、構造化クエリ言語でこのデカルト積演算を実装する Select ステートメントは次のようになります。 選択 あ、あ1.B as B1、R2.B as B2、C R1 クロスジョイン R2; したがって、名前変更オプションをとして使用すると、マシンには、XNUMXつの元のオペランド関係の一致する名前に関する「質問」がありません。 5.内部結合操作 一見、自然結合演算の前に内部結合演算を検討するのは奇妙に思えるかもしれません。二項演算を実行したとき、すべてが逆だったからです。 しかし、構造化照会言語での操作の表現を分析することにより、自然結合操作は内部結合操作の特殊なケースであるという結論に達することができます。 そのため、これらの操作をこの順序で検討するのが合理的です。 したがって、最初に、以前に実行した内部結合操作の定義を思い出してみましょう。 r1(S1) NS P r2(S2)=σ (r1 xr2)、S1 ∩ S2 =∅。 私たちにとって、この定義では、関係の考慮されたスキーム-オペランドSが特に重要です。1 そして、S2 交差してはなりません。 構造化照会言語で内部結合操作を実装するために、特別なオプションがあります 内部結合、これは文字通り英語から「内部結合」または「内部結合」として翻訳されています。 内部結合操作の場合の Select ステートメントは次のようになります。 選択* R1 内部結合 R2; ここでは、前と同じように、R1 そしてR2 -初期関係の名前-オペランド。 この操作を実装する場合、関係オペランドのスキームを交差させてはなりません。 6.自然結合操作 すでに述べたように、自然結合操作は内部結合操作の特殊なケースです。 なんで? はい。自然結合のアクション中に、元のオペランド関係のタプルが特別な条件に従って結合されるためです。 つまり、関係オペランドの交差点でのタプルの等価性の条件により、内部結合演算のアクションでは、このような状況は許容されませんでした。 検討している自然結合操作は内部結合操作の特殊なケースであるため、前に検討した操作と同じオプション、つまりオプションを使用して実装します。 内部結合。 ただし、自然結合操作用にSelect演算子をコンパイルする場合は、スキーマの共通部分で元のオペランド関係のタプルが等しいという条件も考慮する必要があるため、指定されたオプションに加えて、キーワード適用されます on。 英語から翻訳すると、文字通り「オン」を意味し、私たちの意味に関連して、「対象」と翻訳することができます。 自然結合操作を実行するためのSelectステートメントの一般的な形式は次のとおりです。 選択* 関係名1 内部結合 関係名2 on タプル等価条件; 例を考えてみましょう。 XNUMXつの関係を与えましょう: R1 (A、B、C)、 R2 (B、C、D); これらの関係の自然結合操作は、次の演算子を使用して実装できます。 選択 あ、あ1.B、R1。CD R1 内部結合 R2 on R1.B=R2.B と R1.C=R2.C この操作の結果、Select演算子の最初の行で指定された、指定された交差点で等しいタプルに対応する属性が結果に表示されます。 ここでは、名前だけでなく、共通の属性BおよびCを参照していることに注意してください。 これは、デカルト積演算を実装する場合と同じ理由ではなく、そうでない場合、それらがどの関係を参照しているかが明確にならないために実行する必要があります。 興味深いことに、結合条件 (R1.B=R2.B と R1.C=R2.C) は、結合された Null 値関係の共有属性が許可されていないことを前提としています。 これは、Structured Query Language システムに最初から組み込まれています。 7.左外部結合操作 左外部結合操作のSQL構造化照会言語式は、キーワードを置き換えることにより、自然結合操作の実装から取得されます。 内側の キーワードごと 左アウター. したがって、構造化クエリの言語では、この操作は次のように記述されます。 選択* 関係名1 左外部結合 関係名2 on タプル等価条件; 8.右外側結合操作 構造化照会言語の右外部結合操作の式は、キーワードを置換して自然な結合操作を実行することで得られます。 内側の キーワードごと 右外側. したがって、SQL構造化クエリ言語では、右外部結合の操作は次のように記述されます。 選択* 関係名1 右外部結合 関係名2 on タプル等価条件; 9. 完全外部結合操作 完全外部結合操作の構造化照会言語式は、前のXNUMXつの場合と同様に、キーワードを置き換えることにより、自然結合操作の式から取得されます。 内側の キーワードごと フルアウター. したがって、構造化照会言語では、この操作は次のように記述されます。 選択* 関係名1 完全外部結合 関係名2 on タプル等価条件; これらのオプションがSQL構造化照会言語のセマンティクスに組み込まれていると非常に便利です。そうしないと、各プログラマーがそれらを個別に出力して、新しいデータベースに入力する必要があるためです。 4. サブクエリの使用 カバーされた資料から理解できるように、構造化クエリ言語の「サブクエリ」の概念は基本的な概念であり、非常に広く適用できます(ちなみに、SQLクエリとも呼ばれます。実際、プログラミングとデータベースを操作すると、さまざまな関連タスクを解決するためにサブクエリのシステムをコンパイルすることがわかります-構造化された情報を操作する他のいくつかの方法と比較してはるかにやりがいのあるアクティビティです。したがって、サブクエリを使用したアクションをよりよく理解するための例を考えてみましょう、それらのコンパイルと使用します。 特定のデータベースの次のフラグメントがあり、どの教育機関でも使用できるとします。 アイテム(アイテムコード、 項目名); 学生 (記録簿番号、 フルネーム); セッション (科目コード、成績簿番号、 学年); 学生の成績表番号、姓とイニシャル、および「データベース」という名前の科目の成績を示すステートメントを返す SQL クエリを定式化してみましょう。 大学はそのような情報を常にタイムリーに受け取る必要があるため、次のクエリは、おそらくそのようなデータベースを使用する最も一般的なプログラミング ユニットです。 便宜上、「Last Name」、「First Name」、および「Patronymic」属性が Null 値を許可せず、空でないことをさらに仮定しましょう。 新入生の最初のデータが教育機関のデータベースに入力されるのは、彼の姓、名、父称に関するデータであるため、この要件は非常に理解しやすく論理的です。 言うまでもなく、そのようなデータベースに学生に関するデータが含まれているエントリはありませんが、同時に彼の名前は不明です。 「アイテム」関係スキーマの「アイテム名」属性はキーであるため、定義から次のように (これについては後で詳しく説明します)、すべてのアイテム名は一意であることに注意してください。 これは、キーの表現を説明しなくても理解できます。教育機関で教えられるすべての科目は異なる名前を持っている必要があるためです。 さて、演算子自体のテキストのコンパイルを開始する前に、作業を進める上で役立つ XNUMX つの関数を紹介します。 まず、関数が必要です トリム、Trim ("string") と書かれています。つまり、この関数の引数は文字列です。 この関数は何をしますか? この関数は、この行の先頭と末尾にスペースを入れずに引数自体を返します。つまり、この関数は、たとえば次の場合に使用されます。いくつかの余分なスペースの価値があります。 次に、Left (string, number) と書かれた Left 関数、つまり既に XNUMX つの引数を持つ関数を考慮する必要があります。 XNUMX 番目の引数は数値で、文字列の左側から何文字を結果に出力するかを示します。 たとえば、操作の結果: 左 ("ミハイル、1") + "." + 左 ("Zinovievich, 1") 「M.Z.」のイニシャルになります。 クエリでこの関数を使用するのは、生徒のイニシャルを表示するためです。 それでは、目的のクエリのコンパイルを開始しましょう。 まず、小さな補助クエリを作成し、それをメインのメイン クエリで使用します。 選択 成績表番号、成績 セッション 場所 アイテムコード = (選択 アイテムコード オブジェクト 場所 項目名 = "データベース") as "推定" データベース "; ここで as オプションを使用すると、このクエリに "Database Estimates" という別名が付けられます。 これは、このリクエストでさらに作業を進めるのに便利なためです。 次に、このクエリでは、サブクエリ: 選択 アイテムコード オブジェクト 場所 項目名 = "データベース"; リレーション「セッション」から、検討中のサブジェクト、つまりデータベースに関連するタプルを選択できます。 興味深いことに、この内部サブクエリは XNUMX つの値しか返すことができません。これは、「アイテム名」属性が「アイテム」関係のキーであるためです。つまり、その値はすべて一意です。 また、クエリ「Scores "Database"」全体を使用すると、サブクエリで指定された条件を満たす学生 (成績表の番号と成績) に関する「セッション」関係データ、つまり、「データベース」と呼ばれる科目に関する情報を選択できます。 次に、すでに受け取った結果を使用して、メインのリクエストを行います。 選択 学生。 レコード番号、 トリム (姓) + " " + 左 (名前、1) + "." + 左 (愛称、1) + "."as フルネーム、推定「データベース」。 学年 学生 内部結合 ( 選択 成績表番号、成績 セッション 場所 アイテムコード = (選択 アイテムコード オブジェクト 場所 項目名 = "データベース") )as 「推定」データベース」。 on 学生。 Gradebook # = "データベース" の成績。 書籍番号を記録します。 そのため、最初に、クエリの完了後に表示する必要がある属性をリストします。 属性「成績表番号」は学生関係からのものであり、そこから属性「姓」、「名」、および「パトロニミック」であることに注意してください。 確かに、最後の XNUMX つの属性は完全には推定されませんが、最初の文字だけが推定されます。 前に入力した「データベース スコア」クエリの「スコア」属性についても言及します。 「Students」リレーションとクエリ「Database grades」の内部結合から、これらすべての属性を選択します。 ご覧のとおり、この内部結合は、レコードブックの数字が等しいという条件の下で行われます。 この内部結合操作の結果として、成績が Students リレーションに追加されます。 条件による属性「Last Name」、「First Name」および「Patronymic」は Null 値を許可せず、空ではないため、属性「Name」を返す計算式 (トリム (姓) + " " + 左 (名前、1) + "." + 左 (愛称、1) + "."as フルネーム)、それぞれ、追加のチェックを必要とせず、簡素化されています。 講義番号7.基本的な関係 すでにご存じのとおり、データベースは一種のコンテナーのようなものであり、その主な目的は、関係の形で提示されたデータを格納することです。 その性質と構造に応じて、関係は次のように分類されることを知っておく必要があります。 1) 基本的な関係; 2) 仮想関係. ベース ビュー リレーションシップには独立したデータのみが含まれ、他のデータベース リレーションシップで表現することはできません。 商用データベース管理システムでは、基本的な関係は通常、単に次のように呼ばれます。 テーブル 仮想関係の概念に対応する表現とは対照的です。 このコースでは、基本的な関係、主なテクニック、およびそれらを扱う原則のみを詳細に検討します。 1. 基本データ型 リレーションシップと同様に、データ型は次のように分類されます。 基本的な и バーチャル. (仮想データ型については少し後で説明します。このトピックについては別の章を割く予定です。) 基本データ型 - これらは、データベース管理システムで最初に定義されたデータ型です。つまり、デフォルトでそこに存在します (ユーザー定義のデータ型とは対照的に、基本データ型を通過した直後に分析します)。 実際の基本的なデータ型の検討に進む前に、一般的なデータ型を次に示します。 1) 数値データ; 2) 論理データ。 3) 文字列データ。 4) 日時を定義するデータ。 5) 識別データ。 デフォルトでは、データベース管理システムはいくつかの最も一般的なデータ型を導入しており、それぞれがリストされたデータ型のいずれかに属しています。 それらを呼びましょう。 1 で 数値 データ型は次のように区別されます。 1) 整数。 このキーワードは通常、整数データ型を示します。 2) 実数。実数データ型に対応します。 3) XNUMX 進数 (n, m)。 これは XNUMX 進データ型です。 また、表記において、nは数字の総桁数を固定する数字、mは小数点以下何桁かを表す。 4) Money または Currency。通貨データ型の便利なデータ表現のために特別に導入されました。 2 で 論理的 通常、データ型は XNUMX つの基本型のみを割り当てます。これは Logical です。 3. 弦 データ型には XNUMX つの基本型 (もちろん、最も一般的な型) があります。 1) ビット(n)。 これらは、固定長 n のビット文字列です。 2) Varbit(n)。 これらもビットの文字列ですが、可変長は n ビットを超えません。 3) Char(n)。 これらは一定長 n の文字列です。 4) Varchar(n)。 これらは、n 文字を超えない可変長の文字列です。 4.タイプ 日時 次の基本的なデータ型が含まれます。 1) 日付 - 日付データ型。 2) 時刻 - 時刻を表すデータ型。 3) 日時は、日付と時刻の両方を表すデータ型です。 5. 識別 データ型には、データベース管理システムにデフォルトで含まれる XNUMX つの型のみが含まれます。それは GUID (Globally Unique Identifier) です。 すべての基本データ型は、異なるデータ表現範囲のバリアントを持つことができることに注意してください。 例を挙げると、XNUMX バイト整数データ型のバリアントは、XNUMX バイト (bigint) および XNUMX バイト (smallint) データ型にすることができます。 基本的な GUID データ型について個別に説明しましょう。 このタイプは、いわゆるグローバル一意識別子の XNUMX バイトの値を格納することを目的としています。 この識別子のすべての異なる値は、特別な組み込み関数が呼び出されると自動的に生成されます NewId(). この指定は、文字通り「新しい識別子の値」を意味する完全な英語のフレーズ New Identification に由来します。 特定のコンピューターで生成された各識別子の値は、製造されたすべてのコンピューター内で一意です。 GUID 識別子は、特に、データベースのレプリケーションを整理するために、つまり既存のデータベースのコピーを作成するときに使用されます。 このような GUID は、データベース開発者が他の基本的な型と共に使用できます。 GUID 型と他の基本型の中間の位置は、別の特別な基本型 (型) によって占められています。 カウンター. このタイプのデータを指定するには、特別なキーワードが使用されます。 カウンター(×0、Δx)、これは文字通り英語から翻訳され、「カウンター」を意味します。 パラメータ x0 初期値を設定し、 Δx - インクリメント ステップ。 この Counter 型の値は必ず整数です。 この基本的なデータ型の操作には、非常に興味深い機能が多数含まれていることに注意してください。 たとえば、このカウンタータイプの値は設定されていません。他のすべてのデータタイプを操作するときに慣れているため、グローバルに一意の識別子タイプの値と同様に、必要に応じて生成されます。 テーブルを定義するときにのみカウンターの種類を指定できるのも珍しいことです。 この型はコードでは使用できません。 また、テーブルを定義するときは、カウンターの種類を XNUMX つの列にしか指定できないことに注意してください。 行が挿入されると、カウンターデータ値が自動的に生成されます。 さらに、この生成は繰り返しなしで実行されるため、カウンターは常に各行を一意に識別します。 ただし、これにより、カウンター データを含むテーブルを操作するときに不便が生じます。 たとえば、テーブルによって指定された関係のデータが変更され、それらを削除または交換する必要がある場合、特に経験の浅いプログラマーが作業している場合、カウンター値は簡単に「カードを混乱させる」可能性があります。 そのような状況を説明する例を挙げましょう。 ある関係を表す次の表が与えられ、そこに XNUMX つの行が入力されているとします。
カウンターは、新しい各行に一意の名前を自動的に付けました。 次に、テーブルから XNUMX 行目と XNUMX 行目を削除し、XNUMX 行追加します。 これらの操作により、ソース テーブルが次のように変換されます。
したがって、カウンタは XNUMX 番目と XNUMX 番目の行をそれらの一意の名前とともに削除し、予想されるようにそれらを新しい行に「再割り当て」しませんでした。 さらに、データベース管理システムでは、カウンターの値を手動で変更することはできません。これは、XNUMX つのテーブルで複数のカウンターを同時に宣言することを許可しないのと同じです。 通常、カウンタはサロゲート、つまりテーブル内の人工キーとして使用されます。 毎秒 100 つの値の生成速度で XNUMX バイトのカウンターの一意の値が XNUMX 年以上続くことを知ることは興味深いことです。 計算方法を示しましょう。 1 年 = 365 日 * 24 時間 * 60 秒 * 60 秒 < 366 日 * 24 時間 * 60 秒 * 60 秒 < 225 P。 1 秒 > 2-25 年 24*8 値 / 1 値/秒 = 232 c > 27 年 > 100 年。 2. カスタムデータ型 カスタム データ型は、最初はデータベース管理システムに組み込まれておらず、既定のデータ型として宣言されていないという点で、すべての基本型とは異なります。 このタイプは、任意のユーザーおよびデータベース プログラマが、それぞれの要求と要件に従って作成できます。 したがって、ユーザー定義データ型は、ある基本型のサブタイプです。つまり、許可される値のセットにいくつかの制限がある基本型です。 疑似コード表記では、次の標準ステートメントを使用してカスタム データ型が作成されます。 サブタイプを作成 サブタイプ名 タイプ ベースタイプ名 As サブタイプの制約; したがって、最初の行では、新しいユーザー定義のデータ型の名前を指定する必要があります。XNUMX 番目の行では、既存の基本的なデータ型のどれをモデルとして使用して独自のデータ型を作成し、最後に XNUMX 番目の行で指定する必要があります。 - 基本データ型の値のセットに関する既存の制限に追加する必要がある制限 - サンプル。 サブタイプ制約は、定義されているサブタイプの名前に依存する条件として記述されます。 Create ステートメントのしくみをよりよく理解するために、次の例を検討してください。 たとえば、メールで機能するために、独自の特殊なデータ型を作成する必要があるとします。 これは、郵便番号などのデータを扱うタイプになります。 私たちの数字は、通常の XNUMX 進数の XNUMX 桁の数字とは異なり、正の数しかありません。 必要なサブタイプを作成する演算子を書きましょう。 サブタイプを作成 郵便番号 タイプ 6 進数 (0, XNUMX) As 郵便番号 > 0。 なぜ decimal(6, 0) を選んだのですか? インデックスの通常の形式を思い出すと、そのような数は XNUMX から XNUMX までの XNUMX つの整数で構成されている必要があることがわかります。 これが、基本データ型として decimal 型を採用した理由です。 一般に、基本データ型に課せられる条件、つまりサブタイプの制約には論理接続詞 not、and、or、および be が一般に任意の複雑さの式であることに注意してください。 この方法で定義されたカスタム データ サブタイプは、プログラム コードでも、テーブル列でデータ型を定義するときにも、他の基本データ型と一緒に自由に使用できます。つまり、基本データ型とユーザー データ型は、それらを操作するときに完全に等しくなります。 ビジュアル開発環境では、有効な型のリストに他の基本データ型とともに表示されます。 独自の新しいデータベースを設計するときに、文書化されていない (ユーザー定義の) データ型が必要になる可能性は非常に高いです。 実際、デフォルトでは、最も一般的なタスクを解決するのに適した、最も一般的なデータ型のみがデータベース管理システムに組み込まれています。 サブジェクト データベースをコンパイルする場合、独自のデータ型を設計せずに行うことはほとんど不可能です。 しかし、不思議なことに、同じ確率で、作成したサブタイプを削除して、コードが混乱して複雑にならないようにする必要があるかもしれません。 これを行うために、通常、データベース管理システムには特別なオペレーターが組み込まれています。 ドロップ、これは「削除」を意味します。 不要なカスタム型を削除するためのこの演算子の一般的な形式は次のとおりです。 サブタイプを削除 カスタム タイプの名前。 一般に、カスタム データ型は、十分に一般的なサブタイプに推奨されます。 3. デフォルト値 データベース管理システムには、任意のデフォルト値、またはデフォルトとも呼ばれる値を作成する機能がある場合があります。 ほとんどすべてのタスクで、不変のデフォルト値である定数を導入することが必要になる可能性があるため、どのプログラミング環境でも、この操作にはかなり大きな重みがあります。 データベース管理システムでデフォルトを作成するには、ユーザー定義のデータ型の通過からすでにおなじみの機能が使用されます 創造する. デフォルト値を作成する場合のみ、追加のキーワードも使用されます デフォルト、これは「デフォルト」を意味します。 つまり、既存のデータベースにデフォルト値を作成するには、次のステートメントを使用する必要があります。 デフォルトを作成 デフォルト名 As 定数式; この演算子を適用するときに定数値の代わりに、デフォルト値または式にしたい値または式を記述する必要があることは明らかです。 そしてもちろん、データベースで使用するのに便利な名前を決定し、この名前を演算子の最初の行に書き込む必要があります。 この特定のケースでは、この Create ステートメントは、Microsoft SQL Server システムに組み込まれている Transact-SQL 構文に従っていることに注意してください。 それで、私たちは何を手に入れましたか? デフォルトは、そのオブジェクトと同様に、データベースに格納された名前付き定数であると推測しました。 ビジュアル開発環境では、強調表示されたデフォルトのリストにデフォルトが表示されます。 デフォルトの作成例を次に示します。 私たちのデータベースが正しく機能するためには、何かの無制限の寿命という意味で値が機能する必要があるとします。 次に、このデータベースの値のリストに、この要件を満たすデフォルト値を入力する必要があります。 コードテキストでこのやや面倒な式に遭遇するたびに、それを再度書き出すのは非常に不便であるという理由だけで、これが必要になる場合があります。 そのため、上記の Create ステートメントを使用して、何かの無制限の有効期間を意味するデフォルトを作成します。 デフォルトを作成 「時間制限なし」 As ‘9999-12-31 23: 59:59’ ここでは Transact-SQL 構文も使用され、「日時」型の定数の値 (この場合は「9999-12-31 23:59:59」) が次の文字列として書き込まれます。特定の方向。 日時値としての文字列の解釈は、文字列が使用されるコンテキストによって決まります。 たとえば、特定のケースでは、最初に年の制限値が定数行に書き込まれ、次に時刻が書き込まれます。 ただし、すべての有用性のために、デフォルトは、ユーザー定義のデータ型のように、削除する必要がある場合もあります。 通常、データベース管理システムには、不要になったユーザー定義のデータ型を削除する演算子に似た、特別な組み込み述語があります。 これは述語です Drop オペレーター自体は次のようになります。 デフォルトを削除 デフォルト名; 4. 仮想属性 データベース管理システムのすべての属性は、(関係との絶対的な類推によって) 基本と仮想に分けられます。 いわゆる 基本属性 複数回使用する必要がある保存属性であるため、保存することをお勧めします。 そして、順番に、 仮想属性 保存されませんが、計算された属性です。 どういう意味ですか? これは、いわゆる仮想属性の値が実際には格納されていないことを意味しますが、指定された式を使用してオンザフライで基本属性を介して計算されます。 この場合、計算された仮想属性のドメインは自動的に決定されます。 リレーションを定義するテーブルの例を挙げましょう。このテーブルでは、XNUMX つの属性が通常の基本属性であり、XNUMX 番目の属性が仮想属性です。 特別に入力された式に従って計算されます。
したがって、属性「Weight Kg」と「Price Rub per Kg」は基本的な属性であることがわかります。これは、通常の値があり、データベースに保存されているためです。 ただし、属性「Cost」は仮想属性です。これは、計算式によって設定され、実際にはデータベースに格納されないためです。 興味深いことに、仮想属性はその性質上、デフォルト値を取ることができません。一般に、仮想属性のデフォルト値の概念そのものが無意味であり、適用されません。 また、仮想属性のドメインは自動的に決定されますが、計算された値のタイプを既存のものから別のものに変更する必要がある場合があることにも注意する必要があります。 これを行うために、データベース管理システムの言語には、計算式の型を再定義できる特別な Convert 述語があります。 Convert は、いわゆる明示的な型変換関数です。 次のように書かれています。 変換 (データ型、式); Convert 関数の第 XNUMX 引数である式が計算され、関数の第 XNUMX 引数で示される型のデータとして出力されます。 例を考えてみましょう。 式「2 * 2」の値を計算する必要があるとしますが、これを整数「4」としてではなく、文字列として出力する必要があります。 このタスクを達成するために、次の Convert 関数を記述します。 変換 (文字(1)、2 * 2)。 したがって、Convert 関数のこの表記法がまさに必要な結果を与えることがわかります。 5. キーの概念 ベースリレーションのスキーマを宣言するとき、複数のキーの宣言を与えることができます。 これまで何度も遭遇しました。 最後に、一般的なフレーズやおおよその定義に限定されることなく、関係キーとは何かについて詳しく説明する時が来ました。 そこで、関係キーの厳密な定義を与えましょう。 リレーションシップ スキーマ キー 元のスキーマのサブスキーマであり、宣言された XNUMX つ以上の属性で構成されます 一意性条件 関係タプルの値。 一意性条件とは何かを理解するために、または、それとも呼ばれるように、 一意の制約、タプルの定義とタプルをサブサーキットに射影する単項演算から始めましょう。 それらを持って行きましょう: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - タプルの定義、 t(S) [S'] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S は単項射影演算の定義です。 サブスキーマへのタプルの射影がテーブル行のサブストリングに対応することは明らかです。 では、キー属性の一意性制約とは正確には何でしょうか? 関係 S のスキームに対するキー K の宣言は、すでに述べたように、次の不変条件の定式化につながります。 一意性制約 次のように表されます。 在庫 < K → S > r(S): Inv < K → S > r(S) = ∀t1、T2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S))、K ⊆ S; したがって、このキー K の一意性制約 Inv < K → S > r(S) は、任意の XNUMX つのタプル t1 иのトン2、関係 r(S) に属し、キー K への射影で等しい場合、これは必然的にこれら XNUMX つのタプルの等価性と関係 S のスキーマ全体への射影を伴います。つまり、すべての値キー属性に属するタプルのうち、一意であり、その点で一意です。 リレーション キーの XNUMX 番目の重要な要件は、 冗長性要件. どういう意味ですか? この要件は、キーの厳密なサブセットが一意である必要がないことを意味します。 直感的なレベルでは、キー属性は、関係の各タプルを一意かつ正確に識別する関係属性であることは明らかです。 たとえば、テーブルによって与えられる次の関係では:
キー属性は「Gradebook #」属性です。これは、異なる生徒が同じ成績表番号を持つことはできないためです。つまり、この属性には一意の制約が適用されます。 興味深いのは、あらゆる関係のスキーマで、さまざまなキーが発生する可能性があることです。 キーの主な種類を次に示します。 1) シンプルなキー XNUMX つ以上の属性から構成されるキーです。 たとえば、特定の科目の試験問題では、単純なキーはクレジット カード番号です。これは、学生を一意に識別することができるためです。 2) 複合キー XNUMX つ以上の属性で構成されるキーです。 たとえば、教室のリストの複合キーは、建物番号と教室番号です。 結局のところ、これらの属性の XNUMX つを使用して各オーディエンスを一意に識別することは不可能であり、それらの全体、つまり複合キーを使用してこれを行うのは非常に簡単です。 3) スーパーキー 任意のキーの任意のスーパーセットです。 したがって、関係自体のスキーマは確かにスーパーキーです。 このことから、どのリレーションも理論的には少なくとも XNUMX つのキーを持ち、複数のキーを持つ可能性があると結論付けることができます。 ただし、通常のキーの代わりにスーパーキーを宣言することは、自動的に強制される一意性制約を緩和することになるため、論理的に違法です。 結局のところ、スーパーキーには一意性の特性がありますが、非冗長性の特性はありません。 4) 主キー 基本リレーションが定義されたときに最初に宣言されたキーです。 主キーを XNUMX つだけ宣言することが重要です。 さらに、主キー属性は null 値を取ることはできません。 疑似コード エントリでベース リレーションを作成する場合、主キーが示されます。 主キー 括弧内は、このキーである属性の名前です。 5) 候補キー 主キーの後に宣言された他のすべてのキーです。 候補キーと主キーの主な違いは何ですか? まず、複数の候補キーが存在する可能性がありますが、前述のように主キーは XNUMX つしか存在できません。 次に、主キーの属性が Null 値を取ることができない場合、この条件は候補キーの属性に課せられません。 擬似コードでは、ベース リレーションを定義するときに、次の単語を使用して候補キーが宣言されます。 候補キー 次の括弧内には、主キーを宣言する場合と同様に、指定された候補キーである属性の名前が示されます。 6) 外部キー 同じまたは他の基本関係の主キーまたは候補キーも参照する基本関係で宣言されたキーです。 この場合、外部キーが参照する関係を参照 (または 親) 態度。 外部キーを含むリレーションが呼び出されます 子. 疑似コードでは、外部キーは次のように示されます。 外部キー、これらの単語の直後の括弧内に、外部キーであるこの関係の属性の名前が示され、その後にキーワードが記述されます リファレンス ("refers to") を指定し、ベース リレーションの名前と、この特定の外部キーが参照する属性の名前を指定します。 また、基本リレーションを作成するとき、外部キーごとに条件が記述され、 参照整合性制約、しかし、これについては後で詳しく説明します。 講義#8 この講義の主題は、ベース リレーション作成演算子のかなり詳細な説明です。 演算子自体を疑似コード レコードで分析し、そのすべてのコンポーネントとその作業を分析し、変更方法、つまり基本的な関係を変更する方法を分析します。 1.メタ言語記号 ベース関係作成演算子を疑似コードで記述する際に使用される構文構造を記述する場合、さまざまな方法が使用されます。 メタ言語記号. これらは、あらゆる種類の開き括弧と閉じ括弧、ドットとコンマのさまざまな組み合わせ、つまり、それぞれが独自の意味を持ち、プログラマーがコードを記述しやすくする記号です。 基本的な関係の設計で最も頻繁に使用される主要なメタ言語記号の意味を紹介して説明しましょう。 そう: 1) メタ言語文字「{}」。 中括弧内の構文構造は次のとおりです。 必須 構文単位。 基本リレーションを定義する場合、必要な要素は、たとえば基本属性です。 基本属性を宣言しないと、関係を設計できません。 したがって、疑似コードで基本リレーション作成演算子を記述する場合、基本属性は中括弧でリストされます。 2) メタ言語記号 "[]"。 この場合、逆のことが当てはまります。角括弧内の構文構造は、 オプション 構文要素。 ベース リレーション作成演算子のオプションの構文単位は、主キー、候補キー、および外部キーの仮想属性です。 もちろん、微妙な点もありますが、基本リレーションを作成するための演算子の設計に直接進むときに、後で説明します。 3) メタ言語記号「|」。 この記号は文字通り意味します "また"、数学の類似記号のように。 このメタ言語記号の使用は、この記号でそれぞれ区切られた XNUMX つ以上の構造から選択する必要があることを意味します。 4) メタ言語記号「...」。 構文単位の直後に置かれた省略記号は、可能性を意味します。 繰り返し メタ言語記号の前にあるこれらの構文要素。 5) メタ言語記号 ",..". この記号は前のものとほぼ同じ意味です。 メタ言語記号「,..」を使用する場合のみ、 繰り返し 構文構造が発生する カンマで区切られた多くの場合、はるかに便利です。 これを念頭に置いて、次の XNUMX つの構文構造の等価性について説明できます。 単位 [, 単位]... и 単位、.. ; 2. 疑似コード エントリで基本的な関係を作成する例 ベース関係作成演算子を疑似コードで記述するときに使用される主なメタ言語記号の意味を明らかにしたので、この演算子自体の実際の考察に進むことができます。 上記の参照から理解できるように、疑似コード エントリで基本関係を作成するための演算子には、基本属性と仮想属性、主キー、候補キー、および外部キーの宣言が含まれます。 さらに、上で示され説明されるように、この演算子は、属性値の制約とタプルの制約、およびいわゆる参照整合性制約もカバーします。 最初の XNUMX つの制約、つまり属性値制約とタプル制約は、特別な予約語の後に宣言されます。 チェック. 参照整合性制約には、次の XNUMX つのタイプがあります。 更新時、これは「更新時」を意味し、 削除時、これは「削除時」を意味します。 どういう意味ですか? これは、外部キーによって参照される関係の属性を更新または削除するときに、状態の整合性を維持する必要があることを意味します。 (これについては後で詳しく説明します。) 基本リレーション作成演算子自体は、すでに学習した私たちが使用しています - 演算子 創造する、基本的な関係を作成するためだけに、キーワードが追加されます テーブル ("態度")。 そしてもちろん、リレーション自体はより大きく、以前に説明したすべての構成要素と新しい追加の構成要素を含むため、create 演算子は非常に印象的です。 それでは、基本的な関係を作成するために使用される演算子の一般的な形式を疑似コードで書きましょう。 テーブルを作成 ベースリレーション名 { 基本属性名 基本属性値タイプ チェック (属性値制限) {ヌル | ヌルではない} デフォルト (デフォルト値) }、.. 【仮想属性名 as (計算式) ]、.. [,チェック (タプル制約)] [,主キー (属性名、..)] [,候補キー (属性名、..)]... [,外部キー (属性名、..) リファレンス 参照関係名 (属性名、..) 更新時 { 制限する | カスケード | カスケードヌルを設定} 削除時 { 制限 | カスケード | カスケードヌルを設定} ] ... したがって、対応する構文構造の後にメタ言語記号「,..」があるため、いくつかの基本属性と仮想属性、候補キーと外部キーを宣言できることがわかります。 主キーの宣言後、このシンボルは存在しません。前述のように、ベース リレーションでは主キーが XNUMX つしか許可されないためです。 次に、宣言のメカニズムを詳しく見てみましょう。 基本属性. 基本リレーション作成演算子で任意の属性を記述する場合、一般的には、その名前、型、その値の制限、Null 値の有効フラグ、およびデフォルト値が指定されます。 属性のタイプとその値の制約がそのドメイン、つまり文字通りその特定の属性の有効な値のセットを決定することは簡単にわかります。 属性値の制限 属性名に依存する条件として記述します。 この資料を理解しやすくするための小さな例を次に示します。 テーブルを作成 ベースリレーション名 もちろん 整数 チェック (1 <= コースおよびコース <= 5; ここで、条件「1 <= 見出しおよび見出し <= 5」は、整数データ型の定義とともに、属性の許容値のセット、つまり文字通りそのドメインを完全に条件付けます。 Null 値許容フラグ (Null | not Null) は、属性値の間で Null 値の出現を禁止 (not Null) または許可 (Null) します。 前述の例を取り上げると、Null 有効性フラグを適用するメカニズムは次のようになります。 テーブルを作成 ベースリレーション名 もちろん 整数 チェック (1 <= コースおよびコース <= 5); Null ではありません。 そのため、学生のコース番号が null になることはありません。また、データベース コンパイラに認識されないことも、存在しないこともありません。 デフォルト値(デフォルト (デフォルト値)) は、insert ステートメントで属性値が明示的に設定されていない場合に、タプルをリレーションシップに挿入するときに使用されます。 特定の属性の Null 値が有効であると宣言されている限り、デフォルト値も Null 値になる可能性があることに注意してください。 ここで定義を考えてみましょう 仮想属性 基本リレーション作成演算子。 前に述べたように、仮想属性を設定するには、他の基本属性を介して計算式を設定します。 仮想属性「Cost Rub」を宣言する例を考えてみましょう。 基本属性「重量キロ」と「キロ当たりの価格」に応じた式の形式で。 テーブルを作成 ベースリレーション名 重量、kg ベース属性値タイプ 重量 Kg チェック (属性値 Weight Kg の制限) ヌルではない デフォルト (デフォルト値) 価格、こすります。 キロあたり 基本属性 Price Rub の値型。 キロあたり チェック (属性 Price Rub. per Kg の値の制限) ヌルではない デフォルト (デフォルト値) ... コスト、こすります。 as (重量 Kg * Kg あたりの価格摩擦) 少し前に、属性名に依存する条件として記述された属性制約を見てきました。 ここで、ベース リレーションを作成するときに宣言される XNUMX 番目の種類の制約について考えてみましょう。 タプル制約. タプル制約とは何ですか? 属性制約とどう違うのですか? ベース属性名に依存する条件としてタプル制約も書きますが、タプル制約の場合のみ複数の属性名に同時に条件を依存させることができます。 タプル制約を操作するメカニズムを示す例を考えてみましょう。 テーブルを作成 ベースリレーション名 最小重量キロ ベース属性の値のタイプ min Weight Kg チェック (属性値 min Weight Kg の制限) ヌルではない デフォルト (デフォルト値) 最大重量キロ 基本属性の値のタイプ 最大重量 Kg チェック (属性値最大重量Kgの制限) ヌルではない デフォルト (デフォルト値) チェック (0 < 分 体重 Kg & 最小重量 Kg < 最大重量 Kg); したがって、タプルに制約を適用することは、属性名をタプルの値に置き換えることになります。 ベースリレーション作成演算子について考えてみましょう。 宣言されると、基本属性と仮想属性は宣言される場合と宣言されない場合があります。 キー: プライマリ、候補、および外部。 前に述べたように、別の (または同じ) ベース リレーションで最初のリレーションのコンテキストの主キーまたは候補キーに対応するベース リレーションのサブスキーマが呼び出されます。 外部キー. 外部キーが表す リンク機構 他のリレーションのタプルに対するいくつかのリレーションのタプル、つまり、すでに述べたいわゆる 参照整合性制約. (状態の整合性 (つまり、整合性制約によって強制される整合性) は、ベース リレーションとデータベース全体の成功にとって重要であるため、この制約は次の講義の焦点となります。) 次に、主キーと候補キーを宣言すると、前述の基本リレーション スキーマに適切な一意性制約が課されます。 そして最後に、基本リレーションを削除する可能性について述べておく必要があります。 多くの場合、データベース設計の実践では、プログラム コードが乱雑にならないように、古い不要なリレーションを削除する必要があります。 これは、すでに使い慣れた演算子を使用して実行できます Drop. 完全な一般的な形式では、ベース リレーションの削除演算子は次のようになります。 ドロップテーブル ベース リレーションの名前。 3. 状態による整合性制約 整合性制約 リレーショナル データ オブジェクト 現在 いわゆるデータ不変です。 同時に、完全性は自信を持ってセキュリティと区別する必要があります。これは、データを開示、変更、または破壊するための不正アクセスからデータを保護することを意味します。 一般に、リレーショナル データ オブジェクトの整合性制約は次のように分類されます。 階層レベル別 これらの同じリレーショナル データ オブジェクト (リレーショナル データ オブジェクトの階層は、ネストされた概念のシーケンスです: 「属性 - タプル - 関係 - データベース」)。 これは何を意味するのでしょうか? これは、整合性制約が以下に依存することを意味します。 1) 属性レベル - 属性値から。 2)タプルレベル - タプルの値から、つまりいくつかの属性の値から。 3) 関係のレベルで - 関係から、つまり複数のタプルから。 4) データベース レベルで - いくつかの関係から。 したがって、上記の各概念の状態に対する整合性の制約をより詳細に検討する必要があります。 しかし、最初に、状態の整合性制約に対する手続き型および宣言型サポートの概念を示しましょう。 したがって、整合性制約のサポートには、次の XNUMX つのタイプがあります。 1) 手続き的な、つまり、プログラムコードを書くことによって作成されます。 2) 宣言的、つまり、上記のネストされた概念のそれぞれに対して特定の制限を宣言することによって作成されます。 整合性制約の宣言サポートは、基本リレーションを作成するための Create ステートメントのコンテキストで実装されます。 これについて詳しく説明しましょう。 リレーショナル データ オブジェクトの階層的なはしごの一番下、つまり属性の概念から一連の制限について考えてみましょう。 属性レベルの制約 含まれるもの: 1) 属性値のタイプに関する制限。 たとえば、値の整数条件、つまり、前述の基本関係の XNUMX つからの「コース」属性の整数条件。 2) 属性名に依存する条件として記述された属性値の制約。 たとえば、前の段落と同じ基本的な関係を分析すると、その関係には、オプションを使用して属性値にも制約があることがわかります チェック、つまり: チェック (1 <= コースおよびコース <= 5); 3) 属性レベルの制約には、既知の有効性フラグ (Null) または逆に、Null 値の非許容 (Null ではない) によって定義される Null 値制約が含まれます。 前述したように、最初の XNUMX つの制約は属性のドメイン制約、つまりその定義セットの値を定義します。 さらに、リレーショナル データ オブジェクトの階層的なはしごに従って、タプルについて説明する必要があります。 そう、 タプル レベルの制約 タプル制約に縮小され、関係スキーマのいくつかの基本的な属性の名前に依存する条件として記述されます。つまり、この状態整合性制約は、同様のものよりもはるかに小さく単純であり、属性にのみ対応します。 繰り返しになりますが、以前に行った基本的なリレーションの例を思い出すと便利です。これには、今必要なタプル制約があります。つまり、次のとおりです。 チェック (0 < 分 体重 Kg & 最小重量 Kg < 最大重量 Kg); 最後に、状態に対する整合性制約のコンテキストにおける最後の重要な概念は、関係レベルの概念です。 前に言ったように、 関係レベルの制約 プライマリの値を制限することが含まれます (主キー) と候補 (候補キー) キー。 データベースに課せられた制限が、もはや状態整合性制約ではなく、参照整合性制約であることは興味深いことです。 4. 参照整合性制約 したがって、データベース レベルの制約には、外部キーの参照整合性制約 (外部キー)。 これについては、ベース リレーションシップと外部キーを作成するときの参照整合性制約について説明したときに、すでに簡単に説明しました。 今度は、この概念について詳しく説明します。 前に述べたように、宣言されたベース リレーションの外部キーは、他の (ほとんどの場合) ベース リレーションの主キーまたは候補キーを参照します。 この場合、外部キーによって参照されるリレーションが呼び出されることを思い出してください。 参照 または 親のこれは、参照元のリレーションで XNUMX つまたは複数の属性を「生成」するためです。 次に、外部キーを含むリレーションが呼び出されます 子、これも明らかな理由からです。 は何ですか 参照整合性制約? また、子関係の外部キーの各値は、外部キーの値に属性に Null 値が含まれていない限り、必ず親関係の任意のキーの値に対応している必要があります。 この条件に違反する子リレーションのタプルが呼び出されます ぶら下げ. 実際、子リレーションの外部キーが親リレーションに実際には存在しない属性を参照する場合、それは何も参照しません。 あらゆる方法で回避しなければならないのはまさにこれらの状況であり、これは参照整合性を維持することを意味します。 しかし、ダングリング タプルの作成を許可するデータベースは存在しないことを知っているので、開発者はデータベースに最初にダングリング タプルが存在しないこと、および使用可能なすべてのキーが親リレーションシップの実際の属性を参照していることを確認します。 それにもかかわらず、ダングリングタプルがデータベースの操作中にすでに形成されている場合があります。 これらの状況は何ですか? タプルが親リレーションから削除された場合、または親リレーションのタプルのキー値が更新された場合、参照整合性に違反する、つまりダングリング タプルが発生する可能性があることが知られています。 外部キー値を宣言するときにそれらが発生する可能性を排除するには、次のいずれかを指定します。 3 利用可能 ルール 親リレーションのキー値を更新するときに、それに応じて適用される参照整合性の維持 (つまり、前述のように、 更新時) または親リレーションからタプルを削除するとき (削除時)。 親リレーションシップに新しいタプルを追加しても、明らかな理由から、参照整合性を壊すことはできないことに注意してください。 結局のところ、このタプルがベース リレーションに追加されたばかりの場合、そのタプルが存在しないため、以前はどの属性もそれを参照できませんでした! では、データベースの参照整合性を維持するために使用されるこれら XNUMX つのルールは何でしょうか? それらをリストしましょう。 1. 制限しますまたは 制限ルール. 基本リレーションを設定するとき、参照整合性制約で外部キーを宣言するときに、それを維持するこのルールを適用した場合、親リレーションのキーを更新したり、親リレーションからタプルを削除したりすることは、このタプルが子リレーションの少なくとも XNUMX つのタプル、つまり操作によって参照される 制限します ぶら下がっているタプルの出現につながる可能性のあるアクションの実行を厳密に禁止します。 この規則の適用を次の例で説明します。 XNUMXつの関係を与えましょう: 親の態度
子関係
子関係タプル (2,...) と (2,...) が親関係タプル (..., 2) を参照し、子関係タプル (3,...) が参照していることがわかります。 ( ..., 3) 親の態度。 子リレーションのタプル (100,...) はぶら下がっており、無効です。 ここで、親リレーションのタプル (..., 1) と (..., 4) のみが、子リレーションの外部キーによって参照されていないため、キー値の更新とタプルの削除を許可します。 上記のすべてのキーの宣言を含む、基本的なリレーションを作成するための演算子を作成しましょう。 テーブルを作成 親の態度 主キー 整数 ヌルではない 主キー (主キー) テーブルを作成 子関係 外部キー 整数 ヌル 外部キー (外部キー) リファレンス 親関係 (Primary_key) 更新時 制限する 制限を削除 2. カスケードまたは カスケード変更規則. 基本リレーションで外部キーを宣言するときに、参照整合性を維持するルールを使用した場合 カスケードの場合、親リレーションのキーを更新するか、親リレーションからタプルを削除すると、子リレーションの対応するキーとタプルが自動的に更新または削除されます。 カスケード変更ルールがどのように機能するかをよりよく理解するために、例を見てみましょう。 前の例からすでにおなじみの基本的な関係を与えてみましょう。 親の態度
и 子関係
「親関係」関係を定義するテーブル内のいくつかのタプルを更新するとします。つまり、タプル (..., 2) をタプル (..., 20) に置き換えます。つまり、新しい関係を取得します。 親の態度
同時に、外部キーを宣言するときに基本リレーション「子リレーション」を作成するステートメントで、参照整合性を維持するルールを使用しました。 カスケード、つまり、基本関係を作成する演算子は次のようになります。 テーブルを作成 親の態度 主キー 整数 ヌルではない 主キー (主キー) テーブルを作成 子関係 外部キー 整数 ヌル 外部キー (外部キー) リファレンス 親関係 (Primary_key) 更新時 カスケード カスケード削除時 では、親リレーションが上記の方法で更新されると、子リレーションはどうなるでしょうか? 次の形式になります。 子関係
したがって、実際には、ルール カスケード 親リレーションへの更新に応答して、子リレーションのすべてのタプルのカスケード更新を提供します。 3. Nullを設定または null 割り当て規則. 基本関係を作成するステートメントで、外部キーを宣言するときに、参照整合性を維持する規則を適用する場合 Nullを設定その後、親リレーションのキーを更新するか、親リレーションからタプルを削除すると、Null 値を許可する子リレーションの外部キー属性に Null 値が自動的に割り当てられます。 したがって、そのような属性が存在する場合、ルールは適用されます。 以前に使用した例を見てみましょう。 XNUMX つの基本的な関係が与えられたとします。 「子育て」
子関係
ご覧のとおり、子リレーション属性は Null 値を許可するため、ルール Nullを設定 この特定の場合に適用されます。 前の例のように、タプル (..., 1) が親リレーションから削除され、タプル (..., 2) が更新されたと仮定します。 したがって、親関係は次の形式になります。 親の態度
次に、子リレーションの外部キーを宣言するときに、参照整合性を維持するルールを適用したことを考慮して、 Nullを設定、子リレーションは次のようになります。 子関係
タプル (..., 1) は子リレーション キーによって参照されていないため、削除しても影響はありません。 ルールを使用したベース リレーション作成オペレータ自体 Nullを設定 外部キーを宣言すると、関係は次のようになります。 テーブルを作成 親の態度 主キー 整数 ヌルではない 主キー (主キー) テーブルを作成 子関係 外部キー 整数 ヌル 外部キー (外部キー) リファレンス 親関係 (Primary_key) 更新時に Null を設定 削除時に Null を設定 したがって、参照整合性を維持するための XNUMX つの異なるルールが存在することで、次のことが保証されることがわかります。 更新時 и 削除時 機能が異なる場合があります。 子リレーションへのタプルの挿入または子リレーションのキー値の更新は、参照整合性の違反、つまりいわゆるダングリング タプルの出現につながる場合、実行されないことを覚えて理解する必要があります。 いかなる状況でも子リレーションからタプルを削除すると、参照整合性の違反につながる可能性があります。 興味深いのは、他の基本リレーションの外部キーがその属性の一部を主キーとして参照する場合、子リレーションが参照整合性を維持するための独自のルールを持つ親として同時に機能できることです。 プログラマーが、上記の標準ルール以外のルールによって参照整合性が強制されるようにしたい場合は、いわゆるトリガーを使用して、参照整合性を維持するためのそのような非標準ルールの手続きサポートが提供されます。 残念ながら、この概念の詳細な考察は、講義のコースには含まれていません。 5. 指数の概念 ベース リレーションシップでのキーの作成は、インデックスの作成に自動的にリンクされます。 インデックスの概念を定義しましょう。 インデックス - これは、これらの値が発生する関係のタプルへのリンクを含むキーの値の必然的に順序付けられたリストを含むシステムデータ構造です。 データベース管理システムには、次の XNUMX 種類のインデックスがあります。 1) 簡単. 単一の属性から、基本リレーションのスキーマ サブスキーマに対して単純なインデックスが取得されます。 2) 化合物. したがって、複合インデックスは、複数の属性で構成されるサブスキーマのインデックスです。 ただし、単純インデックスと複合インデックスへの分割に加えて、データベース管理システムでは、インデックスを一意と非一意に分割します。 そう: 1) ユニークな インデックスは、最大で XNUMX つの属性を参照するインデックスです。 通常、一意のインデックスはリレーションの主キーに対応します。 2) 一意でない インデックスは、同時に複数の属性に一致できるインデックスです。 非一意キーは、ほとんどの場合、関係の外部キーに対応します。 インデックスを一意と非一意に分割する例を考えてみましょう。つまり、テーブルによって定義される次の関係を考えてみましょう。
ここで、Primary key はリレーションシップの主キー、Foreign key は外部キーです。 これらの関係では、主キー属性のインデックスは主キー、つまり 20 つの属性に対応するため一意であり、外部キー属性のインデックスは外部キーに対応するため一意ではないことが明らかです。キー。 その値「XNUMX」は、関係テーブルの XNUMX 行目と XNUMX 行目の両方に対応します。 ただし、キーに関係なくインデックスを作成できる場合もあります。 これは、データベース管理システムで実行され、並べ替えおよび検索操作のパフォーマンスをサポートします。 たとえば、タプルのインデックス値の二分法検索は、XNUMX 回の反復でデータベース管理システムに実装されます。 この情報はどこから来たのですか? それらは、次のように簡単な計算によって得られました。 106 =(103)2 = 220; インデックスは、既知の Create ステートメントを使用してデータベース管理システムで作成されますが、index キーワードを追加するだけです。 このような演算子は次のようになります。 インデックスを作成 索引名 On ベースリレーション名 (属性名、..); ここでは、カンマで区切られた引数を繰り返す可能性を示すおなじみのメタ言語記号 ",.." が見られます。つまり、この演算子で複数の属性に対応するインデックスを作成できます。 一意のインデックスを宣言する場合は、一意のキーワードをインデックス ワードの前に追加すると、ベース インデックス リレーションの作成ステートメント全体が次のようになります。 一意のインデックスを作成する 索引名 On ベースリレーション名 (属性名); 次に、最も一般的な形で、オプションの要素 (メタ言語記号 []) を指定するためのルールを思い出すと、基本関係のインデックス作成演算子は次のようになります。 [一意の] インデックスを作成する 索引名 On ベースリレーション名 (属性名、..); ベース リレーションから既存のインデックスを削除する場合は、Drop 演算子を使用します。これも既に知られています。 ドロップインデックス {ベースリレーション名. インデックス名},..; ここで修飾インデックス名「ベースリレーション名.インデックス名」を使うのはなぜですか? インデックス名は同じリレーションシップ内で一意である必要があるため、インデックス削除演算子は常に修飾名を使用しますが、それ以上は使用できません。 6. 基本関係の修正 さまざまなベース リレーションシップを適切かつ生産的に処理するために、開発者はこのベース リレーションシップをなんらかの方法で変更する必要があることがよくあります。 データベース設計の実践で最も頻繁に遭遇する主な必須変更オプションは何ですか? それらをリストしましょう: 1) タプルの挿入。 非常に頻繁に、新しいタプルを既に形成されたベース リレーションに挿入する必要があります。 2) 属性値の更新。 また、プログラミングの実践におけるこの変更の必要性は、以前のものよりもさらに一般的です。データベースの引数に関する新しい情報が到着すると、必然的にいくつかの古い情報を更新する必要があるためです。 3) タプルの削除。 また、ほぼ同じ確率で、新しい情報を受け取ったためにデータベースに存在する必要がなくなったタプルをベース リレーションから削除する必要があります。 そのため、基本的なリレーションを変更する主なポイントを概説しました。 これらの目標のそれぞれをどのように達成できますか? データベース管理システムには、ほとんどの場合、組み込みの基本的なリレーションシップ変更演算子があります。 それらを擬似コード エントリで説明しましょう。 1) 挿入演算子 新しいタプルの基本リレーションに。 これが運営者 インセット. 次のようになります。 に挿入 ベースリレーション名 (属性名、..) 価値観 (属性値、..); 属性名と属性値の後のメタ言語記号 ",.." は、この演算子が複数の属性を基本リレーションに同時に追加できることを示しています。 この場合、コンマで区切られた属性名と属性値を一貫した順序でリストする必要があります。 キーワード に オペレーターの一般名と組み合わせて インセット は「挿入先」を意味し、括弧内の属性がどの関係に挿入されるかを示します。 キーワード 価値観 このステートメントでは、これらの新しく宣言された属性に割り当てられる「値」、「値」を意味します。 2)今考えます 更新演算子 基本リレーションの属性値。 この演算子は呼び出されます アップデイト、英語から翻訳され、文字通り「更新」を意味します。 この演算子の完全な一般形式を疑似コード表記で与えて解読しましょう。 アップデイト ベースリレーション名 作成セッションプロセスで {属性名 - 属性値},.. 場所 調子; したがって、キーワードの後の演算子の最初の行で アップデイト 更新が行われるベースリレーションの名前が書かれています。 Set キーワードは英語から「set」に翻訳され、ステートメントのこの行は、更新する属性の名前と対応する新しい属性値を指定します。 メタ言語記号 ",.." を使用すると、XNUMX つのステートメントで複数の属性を一度に更新できます。 キーワードの後の XNUMX 行目 場所 この基本リレーションのどの属性を更新する必要があるかを正確に示す条件が書き込まれます。 3) オペレーター 削除許可する 除去する 基本リレーションからの任意のタプル。 その完全な形式を疑似コードで書き、すべての個々の構文単位の意味を説明しましょう。 から削除 ベースリレーション名 場所 調子; キーワード から オペレーターの名前と組み合わせて 削除 「から取り除く」と訳されます。 そして、演算子の最初の行にあるこれらのキーワードの後に、タプルを削除する必要がある基本リレーションの名前が示されます。 そして、キーワードの後の演算子の XNUMX 行目 場所 ("where") は、基本リレーションで不要になったタプルが選択される条件を示します。 講義番号 9. 関数の依存関係 1. 機能依存の制限 リレーションの主キーおよび候補キー宣言によって課される一意性制約は、概念に関連付けられた制約の特殊なケースです。 機能依存性. 機能依存の概念を説明するために、次の例を考えてみましょう。 特定のセッションの結果に関するデータを含むリレーションが与えられたとします。 この関係のスキーマは次のようになります。 セッション (記録簿番号、 フルネーム、 件名、 学年); 属性「Gradebook number」と「Subject」は、この関係の複合主キーを形成します (XNUMX つの属性がキーとして宣言されているため)。 実際、これら XNUMX つの属性は、他のすべての属性の値を一意に決定できます。 ただし、このキーに関連付けられた一意性制約に加えて、関係は必ず XNUMX つの成績表が XNUMX 人の特定の人に発行されるという条件に従う必要があり、したがって、この点で、同じ成績表番号を持つタプルには同じ値が含まれている必要があります。 「姓」属性のうち、「名とミドルネーム」。
特定のセッションの後、教育機関の学生の特定のデータベースの次のフラグメントがある場合、成績表番号が 100 のタプルでは、属性「姓」、「名」、および「愛称」は同じです。および属性「件名」と「評価」-一致しません(異なる件名とそのパフォーマンスについて話しているため、これは理解できます)。 これは、属性「姓」、「名」、および「愛称」を意味します。 機能的に依存 属性「成績表番号」について、属性「科目」と「評価」は機能的に独立しています。 このように、 機能依存 データベース管理システムで集計される単一値の依存関係です。 ここで、機能的依存の厳密な定義を示します。 定義: X, Y を関係 S のスキームのサブスキームとし、スキーム S を定義する 機能依存図 X → Y (「X矢印Y」と読みます)。 定義しましょう 機能依存制約 inv<X → Y> スキーマ S に関して、サブスキーマ X への射影で一致する XNUMX つのタプルは、サブスキーマ Y への射影でも一致する必要があるというステートメントとして。 同じ定義を式の形で書きましょう: Inv<X → Y> r(S) = t1、T2 ∈ r(t1[X] = トン2[X] はこちらをご覧ください。⇒ t1[Y]=t2 [Y])、X、Y ⊆ S; 興味深いことに、この定義は、以前に遭遇した単項射影演算の概念を使用しています。 実際、この操作を使用しない場合、行ではなくリレーション テーブルの XNUMX つの列が互いに等しいことを示すにはどうすればよいでしょうか? したがって、この操作に関して、いくつかの属性または複数の属性 (サブスキーマ X) への射影におけるタプルの一致は、Y が機能的に依存している場合に、サブスキーマ Y 上の同じ列タプルの一致を確かに伴うことを書きました。 X。 Y が X に機能的に依存している場合、X は 機能的に定義する Yまたは何Y 機能的に依存 X → Y 機能依存スキームでは、サブ回路 X は左側と呼ばれ、サブ回路 Y は右側と呼ばれます。 データベース設計の実践では、関数従属性スキーマは一般に、簡潔にするために関数従属性と呼ばれます。 定義の終わり。 機能依存性の右側、つまりサブスキーマ Y が関係のスキーマ全体と一致する特殊なケースでは、機能依存性の制約は主キーまたは候補キーの一意性制約になります。 本当: 反対r(S) = ∀ t1、T2 ∈ r(t1[K] = t2 [K] → t1(S) = t2(S))、K ⊆ S; サブスキームXの代わりに、機能依存を定義する際に、キーKの指定を取得する必要があり、機能依存の右側であるサブスキームYの代わりに、関係Sのスキーム全体を取得する必要があります。つまり、実際、関係のキーの一意性に対する制限は、右側が関係スキーム全体で関数依存の等しいスキームである場合、関数依存の制限の特殊なケースです。 機能依存のイメージの例を次に示します。 {帳簿番号} → {姓、名、父称}; {成績表番号、件名} → {成績}; 2. アームストロングの推論規則 基本的な関係がベクトルで定義された関数の依存関係を満たす場合、さまざまな特別な推論規則の助けを借りて、この基本的な関係が確実に満たす他の関数の依存関係を取得できます。 そのような特別な規則の良い例は、アームストロングの推論規則です。 しかし、アームストロングの推論規則自体の分析に進む前に、新しいメタ言語記号「├」を紹介しましょう。 導出可能性メタアサーション シンボル. この記号は、規則を定式化するときに、XNUMX つの構文式の間に記述され、その右側の式がその左側の式から導出されることを示します。 アームストロングの推論規則自体を次の定理の形で定式化しましょう。 定理。 アームストロングの推論規則と呼ばれる次の規則が有効です。 推論ルール 1。 § X → X; 推論ルール 2。 X → Y§ X ∪ Z → Y; 推論ルール 3。 X → Y、Y ∪ W → Z § X ∪ W → Z; ここで、X、Y、Z、W は、関係 S のスキーマの任意のサブスキームです。導出可能性のメタステートメント シンボルは、前提のリストと主張 (結論) のリストを分離します。 1. 最初の推論規則は「反射性" そして次のように読みます: "ルールは演繹されます:" X は機能的に X を含意します"". これは、アームストロングの導出ルールの中で最も単純なものです。 左部分と右部分の両方を持つ機能依存が呼び出されることに注意するのは興味深いことです。 反射的な. reflexivity ルールに従って、reflexive 依存の制約が自動的に実行されます。 2. XNUMX つ目の推論規則は「補充「X が機能的に Y を決定する場合、次のルールが導出されます。「サブサーキット X と Z の和集合は、機能的に Y を含意します」」. 補完ルールにより、機能依存制約の左側を拡張できます。 3. XNUMX つ目の推論規則は「疑似推移性「サブ回路 X がサブ回路 Y を機能的に含意し、サブ回路 Y と W の和集合が Z を機能的に含意する場合、次の規則が導出されます。「サブ回路 X と W の和集合がサブ回路 Z を機能的に決定します」。 疑似推移性規則は、特殊なケース W: = 0 に対応する推移性規則を一般化します。この規則の形式的な表記法を示しましょう。 X→Y、Y→Z├X→Z。 以前に与えられた前提と結論は、機能依存スキームの指定によって省略形で提示されたことに注意する必要があります。 拡張形式では、次の機能依存制約に対応します。 推論ルール 1。 投資r(S); 推論ルール 2。 投資r(S) ⇒ inv r(S); 推論ルール 3。 投資r(S)&inv r(S) ⇒ inv r(S); 描く 証拠 これらの推論規則。 1. 規則の証明 反射性 サブスキーム X がサブ回路 Y に置き換えられた場合、機能依存制約の定義から直接従います。 実際、機能依存制約を取り上げます。 反対r(S) に Y の代わりに X を代入すると、次のようになります。 反対r(S) であり、これが反射規則です。 再帰規則が証明されました。 2. 規則の証明 補充 関数の依存関係を図で説明しましょう。 最初の図はパッケージ図です。 前提:X→Y
XNUMX 番目の図: 結論: X ∪ Z → Y
タプルが X ∪ Z で等しいとします。次に、それらは X で等しくなります。前提によれば、それらは Y でも等しくなります。 補充則が証明されました。 3. 規則の証明 疑似推移性 また、図で説明しますが、この特定のケースでは XNUMX つになります。 最初の図は最初の前提です。 前提 1: X → Y
前提 2: Y ∪ W → Z
最後に、XNUMX 番目の図は結論図です。 結論: X ∪ W → Z
タプルが X ∪ W で等しいとすると、それらは X と W の両方で等しくなります. 前提 1 によれば、それらは Y でも等しくなります. したがって、前提 2 によれば、それらは Z でも等しくなります. 疑似推移性規則が証明されました。 すべてのルールは証明されています。 3. 導出された推論規則 必要に応じて、機能依存の新しいルールを導き出すことができるルールの別の例は、いわゆる 派生推論規則. これらの規則とは何ですか、どのように取得されますか? 正当な論理的方法によって既存の規則から他の規則が推定される場合、これらの新しい規則は、 デリバティブ、元のルールと一緒に使用できます。 これらの非常に恣意的なルールは、以前に調べたアームストロングの推論ルールから正確に「派生物」であることに特に注意する必要があります。 次の定理の形で、関数の依存関係を導出するための導出規則を定式化しましょう。 定理 次の規則は、Armstrong の推論規則から派生したものです。 推論ルール 1。 § X ∪ Z → X; 推論ルール 2。 X → Y、X → Z § X ∪ Y → Z; 推論ルール 3。 X → Y ∪ Z § X → Y、X → Z; ここで、X、Y、Z、W は、前の場合と同様に、関係 S のスキームの任意のサブスキームです。 1. 最初に導出されたルールが呼び出されます 些細なルール そして次のように読みます: 「ルールが導き出されます:「サブサーキットXとZの結合は機能的にXを伴います」. 左側が右側のサブセットである機能依存関係が呼び出されます 些細な. 自明性規則に従って、自明な依存関係の制約が自動的に適用されます。 興味深いことに、自明性ルールは再帰性ルールの一般化であり、後者と同様に、機能依存性制約の定義から直接導き出すことができます。 このルールが導き出されたのは偶然ではなく、アームストロングのルール体系の完成度に関係しています。 アームストロングのルール体系の完全性については、後で詳しく説明します。 2. XNUMX 番目の派生ルールが呼び出されます 加算規則 「サブサーキット X が機能的にサブサーキット Y を決定し、X が同時に機能的に Z を決定する場合、これらのルールから次のルールが導き出されます。「X はサブサーキット Y と Z の和集合を機能的に決定します」」。 3. XNUMX 番目の派生ルールが呼び出されます 射影規則 またはルール加法的反転「サブサーキット X がサブサーキット Y と Z の和集合を機能的に決定する場合、この規則から次のルールが導き出されます。「X はサブサーキット Y を機能的に決定し、同時に X はサブサーキットを機能的に決定します」 Z" "、つまり、実際、この派生ルールは逆加法性ルールです。 同じ左辺を持つ関数の依存関係に適用される加法性と射影性の規則により、依存性の右辺を結合したり、逆に分割したりできるのは興味深いことです。 推論チェーンを構築するとき、すべての前提を定式化した後、推移性のルールを適用して、右辺との機能依存性を結論に含めます。 描く 証拠 任意の推論規則をリストします。 1. 規則の証明 些細なこと. 後続のすべての証明と同様に、順を追って実行してみましょう。 1) X → X (アームストロングの推論の再帰性規則から); 2) さらに、X ∪ Z → X (最初にアームストロングの推論完了規則を適用し、次に証明の最初のステップの結果として得られる) が得られます。 自明の法則が証明されました。 2.ルールの段階的な証明を行います 加法性: 1) X → Y (これは前提 1) です。 2) X → Z (これは前提 2 です); 3) Y ∪ Z → Y ∪ Z (アームストロングの推論の再帰性規則から); 4) X ∪ Z → Y ∪ Z (アームストロングの推論の疑似推移性の規則を適用し、証明の最初と XNUMX 番目のステップの結果として得られる); 5) X ∪ X → Y ∪ Z (アームストロングの疑似推移性の推論規則を適用することによって得られ、XNUMX 番目と XNUMX 番目のステップに従います); 6) X → Y ∪ Z (XNUMX 番目のステップから続く) があります。 加法定理が証明されました。 3。 そして最後に、ルールの証明を構築します 射影性: 1) X → Y ∪ Z, X → Y ∪ Z (これは前提です); 2) Y → Y, Z → Z (アームストロングの推論の再帰性規則を使用して導出); 3) Y ∪ z → y, Y ∪ z → Z (アームストロングの推論完了規則と証明の第 XNUMX ステップの系から得られる); 4) X → Y, X → Z (アームストロングの推論の疑似推移規則を適用し、証明の最初と XNUMX 番目のステップの結果として得られる)。 射影則が証明されました。 すべての微分推論規則が証明されています。 4. アームストロング規則体系の完全性 F(S) を、関係スキーム S に対して定義された関数依存関係の特定のセットとします。 で表す INV この一連の機能依存関係によって課せられる制約。 書き留めましょう: 反対r(S) = ∀X → Y ∈F(S) [inv r(S)]。 したがって、機能依存関係によって課せられる制限のこのセットは、次のように解読されます。 r(S) は、リレーション r(S) の集合に対して定義されます。 ある関係 r(S) がこの制約を満たすとします。 アームストロングの推論規則をセット F(S) に対して定義された機能依存関係に適用することにより、既に述べ、以前に証明したように、新しい機能依存関係を取得できます。 そして、アームストロングの推論規則の拡張形式からわかるように、関係 F(S) はこれらの機能依存関係の制限を自動的に満たします。 これらの拡張推論規則の一般的な形式を思い出してください。 推論ルール 1。 inv < X → X > r(S); 推論ルール 2。 投資r(S) はこちらをご覧ください。⇒ inv<X ∪ Z → Y> r(S); 推論ルール 3。 投資r(S) & inv <Y ∪ W → Z> r(S) はこちらをご覧ください。⇒ inv<X ∪ W→Z>; 推論に戻って、セット F(S) に、アームストロングの規則を使用して派生した新しい依存関係を補充しましょう。 新しい機能依存関係が得られなくなるまで、この補充手順を適用します。 この構築の結果、関数依存関係の新しいセットが得られます。 閉鎖 F(S) を設定し、 F+(S). 確かに、そのような名前は非常に論理的です。なぜなら、私たちは個人的に、長い構築を通じて、既存の機能依存関係のセットをそれ自体に「閉じ」、既存のものから生じるすべての新しい機能依存関係を追加 (したがって「+」) したからです。 これらすべての構築が実行される関係スキーム自体が有限であるため、クロージャを構築するこのプロセスは有限であることに注意する必要があります。 言うまでもなく、クロージャーはクローズされるセットのスーパーセットであり (実際、それよりも大きいです!)、再びクローズされても変化しません。 今述べたことを定型的な形で書くと、次のようになります。 F(S) ⊆ F+(S)、[F+(S)]+=F+(S); さらに、アームストロングの推論規則の証明された真実 (つまり、合法性、正当性) とクロージャの定義から、関数依存関係の特定のセットの制約を満たす関係は、クロージャに属する依存関係の制約を満たすことになります。 . X → Y ∈ F+(S) はこちらをご覧ください。⇒ ∀r(S) [inv r(S) はこちらをご覧ください。⇒ 反対r(S)]; したがって、推論規則のシステムに対するアームストロングの完全性定理は、外部の含意は完全に正当かつ正当に同等性に置き換えることができると述べています。 (この定理の証明は考慮しません。なぜなら、証明のプロセス自体は、私たちの特定の講義ではそれほど重要ではないからです。) 講義番号 10. 通常形 1. データベース スキーマの正規化の意味 このセクションで検討する概念は、機能の依存関係の概念に関連しています。つまり、データベース スキーマを正規化することの意味は、機能の依存関係のシステムによって課せられる制限の概念と密接に関連しており、主にこの概念に従います。 データベース設計の出発点は、ドメインを XNUMX つ以上のリレーションシップとして表すことです。各設計ステップでは、「強化された」プロパティを持つリレーションシップ スキーマのセットが生成されます。 したがって、設計プロセスは関係パターンを正規化するプロセスであり、連続する各正規形は、ある意味で前のものよりも優れた特性を持っています。 各正規形には特定の制約セットがあり、関係が独自の制約セットを満たす場合、関係は特定の正規形になります。 例として、最初の正規形の制限があります。関係のすべての属性の値はアトミックです。 リレーショナル データベース理論では、通常、次の一連の正規形が区別されます。 1) 最初の正規形 (1 NF); 2) 2 番目の正規形 (XNUMX NF)。 3) 第 3 正規形 (XNUMX NF)。 4) ボイス-コッド標準形 (BCNF); 5) 第 4 正規形 (XNUMX NF)。 6) 第 5 正規形、または射影結合正規形 (XNUMX NF または PJ/NF)。 (このコースの講義には、基本的な関係の最初の XNUMX つの正規形の詳細な説明が含まれているため、XNUMX 番目と XNUMX 番目の正規形については詳しく分析しません。) 通常のフォームの主なプロパティは次のとおりです。 1) 次の各正規形は、ある意味で前の正規形よりも優れています。 2) 次の正規形に渡すとき、前の正規形のプロパティが保持されます。 設計プロセスは、正規化の方法に基づいています。つまり、前の正規形の関係を、次の正規形の要件を満たす XNUMX つ以上の関係に分解します (これは、正規化する必要があるときに発生します)。資料を見ていきます)またはその他の基本的な関係)。 基本的な関係の作成に関するセクションで説明したように、関数の依存関係の特定のセットは、基本的な関係のスキーマに適切な制限を課します。 これらの制限は、通常、次の XNUMX つの方法で実装されます。 1) 宣言的に、つまり、さまざまなタイプの主キー、候補キー、および外部キーを基本リレーションで宣言することによって (これは最も広く使用されている方法です)。 2) 手続き的に、つまり、プログラムコードを書く (上記のいわゆるトリガーを使用して)。 単純なロジックの助けを借りて、データベース スキーマを正規化するポイントを理解できます。 データベースを正規化する、またはデータベースを通常の形式にするということは、プログラム コードを記述する必要性を最小限に抑え、データベースのパフォーマンスを向上させ、状態と参照整合性によるデータ整合性の維持を容易にするために、基本的な関係のスキームを定義することを意味します。 つまり、コードを作成し、開発者とユーザーにとって可能な限りシンプルで便利にすることです。 正規化されていないデータベースと正規化されたデータベースの操作を比較して視覚的に示すために、次の例を検討してください。 試験セッションの結果に関する情報を含むベース リレーションを作成してみましょう。 このようなデータベースについては、すでに検討済みです。 このように、 オプション1 データベース スキーマ。 セッション (記録簿番号、 フルネーム、 件名、 学年) このリレーションでは、基本リレーション スキーマ イメージからわかるように、複合主キーが定義されています。 主キー (教科書番号、件名); また、この点に関して、機能依存のシステムが設定されています。 {帳簿番号} → {姓、名、父称}; これは、このリレーション スキームを使用したデータベースの小さなフラグメントの表形式のビューです。 機能依存関係の制限を考慮する際にこのフラグメントを既に使用しているため、例を使用してこのトピックを理解することは非常に簡単です。
ここで、州ごとのデータの完全性を維持するため、つまり、姓などを変更する際に、機能依存のシステム {クラスブック番号} → {姓、名、愛称} の制限を満たすために、この基本的なリレーションのすべてのタプルを調べて、必要な変更を順番に入力する必要があります。 ただし、これはかなり面倒で時間のかかるプロセスであるため (特に大規模な教育機関のデータベースを扱っている場合)、データベース管理システムの開発者は、このプロセスを自動化する必要があるという結論に達しました。 、自動化。 現在、この (およびその他の) 関数の依存関係の実現に対する制御は、基本リレーションのさまざまなキーの正しい宣言と、このリレーションのいわゆる分解 (つまり、何かをいくつかの独立した部分に分割すること) を使用して自動的に編成できます。 . そこで、既存の「セッション」関係スキーマを XNUMX つのスキーマに分割しましょう。特定の教育機関の学生に関する情報のみを含む「学生」スキーマと、最後の過去のセッションに関する情報を含む「セッション」スキーマです。 次に、必要な情報を簡単に取得できるようにキーを宣言します。 キーを持つこれらの新しい関係スキームがどのように見えるかを示しましょう。 オプション2 データベース スキーマ。 学生 (記録簿番号、 フルネーム)、 主キー (成績表番号)。 セッション (レコードブック番号、件名、 学年)、 主キー(成績表番号、件名)、 外部キー (成績表番号) は、学生 (成績表番号) を参照します。 私たちは今何を持っていますか? 「学生」に関連して、主キー「成績表番号」は、他の XNUMX つの属性「姓」、「名」、および「愛称」を機能的に決定します。 また、「セッション」に関連して、複合主キー「Gradebook No.、Subject」も明確に、つまり、この関係スキームの最後の属性である「スコア」を文字通り機能的に定義します。 そして、これら XNUMX つのリレーション間の接続が確立されました。これは、「セッション」リレーションシップ「Gradebook No」の外部キーを介して実行されます。これは、「学生」リレーションシップの同じ名前の属性を参照し、要求された場合は、必要なすべての情報を提供します。 次に、対応するデータベース スキーマを指定する XNUMX 番目のオプションに対応するテーブルによって表される関係がどのようになるかを示します。
したがって、関数の依存関係によって課せられる制限に関する正規化の目標は、基本関係のさまざまなタイプの主キー、候補キー、および外部キーの宣言を使用して、必要な機能の依存関係を任意のデータベースに課す必要があることがわかります。 2. 第 1 正規形 (XNUMXNF) データベース設計およびデータベース管理スキームの開発の初期段階では、単純で明確な属性が最も生産的で合理的なコード単位として使用されていました。 次に、単純属性と複合属性、および単一値属性と複数値属性を使用しました。 これらの概念のそれぞれの意味を説明しましょう。 複合属性は、単純なものとは対照的に、複数の単純な属性で構成される属性です。 複数値の属性は、単一値の属性とは異なり、複数の値を表す属性です。 以下は、単純、複合、単一値、および複数値の属性の例です。 関係を表す次の表を検討してください。
ここで、"Phone" 属性は単純で明確であり、"Address" 属性は単純ですが多値です。 ここで、異なる属性を持つ別のテーブルを考えてみましょう。
表で表されるこの関係では、「Phones」属性は単純ですが多値であり、「Addresses」属性は複合的かつ多値です。 一般に、単純属性または複合属性のさまざまな組み合わせが可能です。 さまざまなケースで、関係を表すテーブルは一般的に次のようになります。
基本的な関係スキームを正規化する場合、プログラマーは、最も一般的な 1 つのタイプの正規形のいずれかを使用できます: 第 2 正規形 (3NF)、第 XNUMX 正規形 (XNUMXNF)、第 XNUMX 正規形 (XNUMXNF)、またはボイス・コッド正規形 (NFBC)。 . 明確にするために: 省略形 NF は、英語のフレーズ Normal Form の省略形です。 正式には、上記以外にも正規形がありますが、上記が代表的なものです。 現在、データベース開発者は、コードの記述を複雑にせず、構造を過負荷にせず、ユーザーを混乱させないように、複合属性や多値属性を避けようとしています。 これらの考慮事項から、最初の正規形の定義は論理的に続きます。 意味。 基本関係はすべて 第 XNUMX 正規形 この関係のスキーマに単純な単一値の属性のみが含まれ、同じセマンティクスを持つ必要がある場合にのみ。 正規化された関係と正規化されていない関係の違いを視覚的に説明するために、例を考えてみましょう。 次のスキームで、正規化されていない関係があるとしましょう。 このように、 オプション1 単純な主キーが定義された関係スキーム: 従業員 (社員番号、姓、名、父称、役職コード、電話番号、入学または解雇の日付); 一次キー (従業員番号); この関係スキームにどのようなエラーがあるかをリストしましょう。つまり、このスキームを正規化されていないものにする兆候を挙げます。 1) 属性「Surname First Name Patronymic」は複合的です。つまり、異種の要素で構成されています。 2) 「Phones」属性は多値です。つまり、その値は一連の値です。 3) 属性「受諾または解任日」には明確なセマンティクスがありません。つまり、後者の場合、どの日付が入力されているかが明確ではありません。 たとえば、日付の意味をより正確に定義するために追加の属性が導入された場合、この属性の値は意味的に明確になりますが、それでも各従業員に対して指定された日付の XNUMX つだけを保存することが可能です。 この関係を正常な形にするにはどうすればよいでしょうか? まず、複合属性を単純なものに分割して、これらの非常に複合的な属性や、複合的なセマンティクスを持つ属性を除外する必要があります。 次に、この関係を分解する必要があります。つまり、複数の値を持つ属性を除外するために、いくつかの新しい独立した関係に分割する必要があります。 したがって、上記のすべてを考慮して、「従業員」関係を分解して最初の正規形または 1NF に還元した後、主キーと外部キーが設定された次の関係のシステムを取得します。 このように、 オプション2 関係: 従業員 (社員番号、姓、名、父称、役職コード、入学日、解雇日); 一次キー (従業員番号); 電話 (社員番号、電話番号); 主キー (従業員番号、電話番号); 外部キー (従業員番号) は従業員 (従業員番号) を参照します。 それで、私たちは何を見ますか? 複合属性「Surname First Name Patronymic」は、もはや私たちの関係にはありません。代わりに、XNUMX つの単純な属性「Surname」、「First Name」、および「Patronymic」があるため、この関係の「異常」の理由は除外されました。 . また、セマンティクスが明確でない「採用日または解雇日」の属性の代わりに、セマンティクスが明確な「入社日」と「解雇日」の XNUMX つの属性が追加されました。 したがって、「従業員」関係が通常の形ではないという XNUMX つ目の理由も安全に解消されます。 最後に、"Employees" リレーションが正規化されなかった最後の理由は、多値属性 "Phones" の存在です。 この属性を取り除くには、関係全体を分解する必要がありました。 この分解の結果、属性「電話」は元のリレーション「従業員」から一般に除外されましたが、XNUMX 番目のリレーション「電話」が形成されました。このリレーションには、「従業員の従業員番号」と「電話」の XNUMX つの属性があります。 」、つまり、すべての属性 - これも単純ですが、最初の正規形に属するという条件が満たされています。 これらの属性「従業員番号」と「電話」は、「電話」関係の複合主キーを形成し、「従業員番号」属性は、「従業員」の同じ名前の属性を参照する外部キーです。 " リレーションシップ、つまりリレーション " Phones" 属性の主キー "personnel number" は、"Employees" リレーションシップの主キーを参照する外部キーでもあります。 したがって、XNUMX つの関係の間にリンクが提供されます。 このリンクを使用すると、複合属性を使用することなく、多くの労力と時間を費やすことなく、従業員の従業員番号ごとに電話の全リストを表示できます。 システムに関連して機能的な依存関係がある場合、上記のすべての変換の後、正規化は完了しないことに注意してください。 ただし、この特定の例では、機能依存の制約がないため、この関係をさらに正規化する必要はありません。 3. 第 2 正規形 (XNUMXNF) 関係には、第 2 正規形 (XNUMXNF) によって、より強い要件が課せられます。 これは、関係の第 XNUMX 正規形の定義が、第 XNUMX 正規形とは対照的に、関数の依存関係に対する制限のシステムの存在を意味するためです。 意味。 基本関係は 第 XNUMX 正規形 それが最初の正規形であり、さらに、各非キー属性が各キーに完全に機能的に依存している場合にのみ、特定の機能依存関係のセットに相対的です。 この定義では 非キー属性 リレーションの主キーまたは候補キーに含まれていないリレーション属性です。 キーへの完全な機能依存は、そのキーのどの部分にも機能依存がないことを意味します。 したがって、関係を正規化するときは、関係が最初の正規形になるための条件が満たされていることも監視する必要があります。機能依存の制限。 単純なキー (主および候補) との関係が確かに第 XNUMX 正規形であることは明らかです。 実際、この場合、鍵には別個の部分がないため、鍵の一部への依存は単純に不可能に見えます。 ここで、前のトピックのパッセージと同様に、正規化されていない関係スキームと正規化プロセス自体の例を考えてみましょう。 このように、 オプション1 関係スキーム: オーディエンス (建物番号、講堂番号、面積平方。 m、軍団のサービス司令官); 主キー (コーパス番号、聴衆番号); さらに、次の機能依存システムが定義されています。 {軍団の番号} → {軍団の軍司令官の番号}; 私たちは何を見ますか? この関係のすべての属性が明白で単純であるため、この関係「オーディエンス」が最初の正規形に留まるためのすべての条件が満たされています。 しかし、各非キー要素が完全に機能的にキーに依存していなければならないという条件は満たされていません。 なんで? はい、属性「軍団の参謀長の番号」は機能的に複合キー「軍団の番号、聴衆の番号」ではなく、このキーの一部、つまり属性に依存するためです。 「軍団の数」。 結局のところ、どの特定の司令官が割り当てられているかを完全に決定するのは軍団番号であり、軍団司令官の人員番号は、講堂の番号に依存することはできません。 したがって、正規化の主なタスクは、特に属性「No. これを達成するために、前の段落のように、関係の分解を再度適用する必要があります。 したがって、次の関係システムは次のとおりです。 オプション2 「オーディエンス」関係は、元の関係をいくつかの新しい独立した関係に分解することによって得られたものです。 軍団 (船体番号、軍団の人事司令官の数); 主キー (ケース番号); オーディエンス (建物番号、講堂番号、面積平方。 m); 主キー (コーパス番号、聴衆番号); 外部キー (ケース番号) は Cases (ケース番号) を参照します。 私たちは今何を見ていますか? 「Corpus」の非キー属性「Corps Commandant's Person Number」は、完全に機能的に主キー「Corps Number」に依存します。 ここで、第 XNUMX 正規形の関係を見つけるための条件が完全に満たされます。 次に、XNUMX 番目の関係である「オーディエンス」の検討に移りましょう。 「Audience」に関しては、主キー属性「Case #」も、「Case」関係の主キーを参照する外部キーです。 この点で、非キー属性「Area sq. m」は複合主キー「Building #, Auditorium #」全体に完全に依存しており、そのどの部分にも依存することはできません。 したがって、元の関係を分解することによって、第 XNUMX 正規形の定義からのすべての条件が完全に満たされるという結論に達しました。 この例では、主キー (ここには候補キーはありません) と外部キーの宣言によって、すべての機能依存要件が課されます。 したがって、それ以上の正規化は必要ありません。 4. 第 3 正規形 (XNUMXNF) 次の正規形は、第 3 正規形 (または XNUMXNF) です。 第 XNUMX の正規形や第 XNUMX の正規形とは異なり、第 XNUMX の正規形は、関係と一緒に関数の依存関係のシステムの割り当てを意味します。 関係が第 XNUMX 正規形に還元されるために必要なプロパティを定式化しましょう。 意味。 基本関係は 第 XNUMX 正規形 機能依存関係の特定のセットに関しては、それが第 XNUMX 正規形であり、各非キー属性が完全に機能的にキーのみに依存している場合に限ります。 したがって、第 XNUMX 正規形の要件は、第 XNUMX 正規形と第 XNUMX 正規形の要件を組み合わせた場合よりも強力です。 実際、第 XNUMX 正規形では、すべての非キー属性はキーとキー全体に依存し、キー以外には何も依存しません。 正規化されていない関係を第 XNUMX 正規形にするプロセスを説明しましょう。 これを行うには、例を考えてみましょう: 第 XNUMX 正規形ではない関係。 このように、 オプション1 関係「従業員」のスキーム: 従業員 (社員番号、姓、名、父称、役職コード、給与); 一次キー (従業員番号); さらに、この「従業員」関係の上に、次の機能依存システムが設定されています。 {役職コード} → {給与}; 実際、原則として、給与の額、つまり 賃金の額は、役職に直接依存するため、対応するデータベースのコードに依存します。 これが、この関係「従業員」が第 XNUMX 正規形ではない理由です。非キー属性「給与」は、キー属性ではありませんが、属性「役職コード」に機能的に完全に依存していることが判明したためです。 興味深いことに、どの関係も、これより前の XNUMX つの形式とまったく同じ方法、つまり分解によって第 XNUMX 正規形に還元されます。 「従業員」関係を分解すると、次の新しい独立した関係のシステムが得られます。 このように、 オプション2 関係「従業員」のスキーム: ポジション (位置コード、 給料); 主キー (位置コード); 従業員 (社員番号、姓、名、父称、役職コード); 主キー (位置コード); 外部キー (位置コード) は位置 (位置コード) を参照します。 ここでわかるように、「役職」に関連して、非キー属性「給与」は単純な主キー「役職コード」に機能的に完全に依存しており、このキーのみに依存しています。 「従業員」に関連して、「姓」、「名」、「愛称」、「役職コード」の XNUMX つの非キー属性はすべて、単純な主キー「雇用番号」に完全に依存していることに注意してください。 この点で、「位置 ID」属性は、「位置」関係の主キーを参照する外部キーです。 この例では、単純な主キーと外部キーを宣言することによってすべての要件が課せられるため、それ以上の正規化は必要ありません。 実際には、通常、データベースを第 XNUMX 正規形にすることに限定されていることを知っておくと、興味深く、役に立ちます。 同時に、同じ関係の他の属性に対する主要な属性のいくつかの機能依存性が課されない場合があります。 このような非標準の機能依存関係のサポートは、前述のトリガーを使用して (つまり、適切なプログラム コードを記述することによって) 実装されます。 さらに、トリガーはこの関係のタプルで動作する必要があります。 5. ボイス-コッド標準形 (NFBC) ボイス-コッド正規形は、第 XNUMX 正規形の直後の「複雑さ」に続きます。 したがって、ボイス-コッド標準形は、単に呼ばれることもあります。 強い第 XNUMX 正規形 (または強化された3 NF)。 なぜ彼女は強化されたのですか? ボイス・コッド正規形の定義を定式化します。 意味。 基本関係は ボイス通常形 - コッド 第 XNUMX 正規形であり、非キー属性がキーに完全に機能的に依存しているだけでなく、キー属性がキーに完全に機能的に依存している必要があります。 したがって、非キー属性が実際にはキー全体に依存し、キーのみに依存するという要件は、キー属性にも適用されます。 Boyce-Codd 正規形の関係では、関係内のすべての機能依存関係は、キーの宣言によって課されます。 ただし、データベースの関係をボイス-コッド形式に縮小すると、さまざまな関係の属性間の依存関係が機能的な依存関係を課されないことが判明する状況が発生する可能性があります。 異なるリレーションのタプルで動作するトリガーを使用してこのような関数依存関係をサポートすることは、トリガーが単一のリレーションのタプルで動作する場合の第 XNUMX 正規形の場合よりも困難です。 とりわけ、データベース管理システムの設計の実践では、基本的な関係をボイス-コッドの正規形に持ち込むことが常に可能であるとは限らないことが示されています。 指摘された例外の理由は、第 XNUMX 正規形と第 XNUMX 正規形の要件が、他の可能なキーのコンポーネントである属性の主キーへの最小限の機能的依存を必要としなかったことです。 この問題は、歴史的にボイス-コッド正規形と呼ばれる正規形によって解決されます。この正規形は、いくつかの重複する可能性のあるキーが存在する場合の XNUMX 番目の正規形を改良したものです。 一般に、データベース スキーマの正規化により、データベースの整合性を維持するためのチェックとバックアップの数が減るため、データベース管理システムによるデータベースの更新がより効率的になります。 リレーショナル データベースを設計するときは、ほとんどの場合、データベース内のすべてのリレーションシップの第 XNUMX 正規形を実現します。 頻繁に更新されるデータベースでは、通常、関係の第 XNUMX 正規形を提供しようとします。 Boyce-Codd 正規形はあまり注目されていません。これは、実際には、リレーションにいくつかの複合的な重複候補キーがある状況がまれであるためです。 上記のすべてにより、ボイス-コッド正規形はプログラム コードの開発時に使用するのにあまり便利ではありません。したがって、前述のように、実際には、開発者は通常、データベースを第 XNUMX 正規形にすることに制限されます。 ただし、独自のかなり興味深い機能もあります。 要点は、関係が第 XNUMX 正規形であるがボイス-コッド正規形ではない状況は、実際には非常にまれであるということです。外部キーであるため、トリガーが機能の依存関係をサポートする必要はありません。 ただし、機能の依存関係によってリンクされていない整合性制約をサポートするためのトリガーの必要性は残っています。 6. 通常形の入れ子 通常形の入れ子とはどういう意味ですか? 通常形の入れ子 -これは、弱体化された形態と強化された形態の概念の相互関係の比率です。 通常のフォームのネストは、それぞれの定義から完全に従います。 私たちに知られている正規形の入れ子関係を示す図を想像してみましょう:
具体的な例を使用して、弱化および強化された正規形の概念を互いに説明しましょう。 第 XNUMX 正規形は、第 XNUMX 正規形に比べて弱体化されています (他のすべての正規形にも弱体化されています)。 実際、これまでに行ったすべての正規形の定義を思い出すと、各正規形の要件には、最初の正規形に属するという要件が含まれていることがわかります (結局、それは後続の各定義に含まれていました)。 第 XNUMX 正規形は第 XNUMX 正規形よりも強力ですが、第 XNUMX 正規形およびボイス-コッド正規形よりも弱いです。 実際、第 XNUMX 正規形に属することは第 XNUMX 正規形の定義に含まれており、第 XNUMX 正規形自体も第 XNUMX 正規形を含んでいます。 ボイス-コッド正規形は、第 XNUMX 正規形に対して強化されているだけでなく、それ以前の他のすべての正規形に対しても強化されています。 また、XNUMX 番目の正規形は、ボイス-コッド正規形に対してのみ弱められています。 講義番号 11. データベース スキーマの設計 論理レベルで設計するときにデータベース スキーマを抽象化する最も一般的な手段は、いわゆる 実体関係モデル. と呼ばれることもあります 小胞体モデル、ここで ER は英語のエンティティ - 関係の略語であり、文字通り「エンティティ - 関係」と訳されます。 このようなモデルの要素は、エンティティ クラス、その属性、および関係です。 これらの各要素の説明と定義を示します。 エンティティ クラス オブジェクト指向プログラミングの意味でのメソッドのないオブジェクトのクラスのようなものです。 物理層に移動すると、エンティティ クラスは特定のデータベース管理システムの基本的なリレーショナル データベース関係に変換されます。 これらは、基本的なリレーション自体と同様に、独自の属性を持っています。 今与えられたオブジェクトのより正確で厳密な定義を与えましょう。 クラス 共通の属性、操作、関係、およびセマンティクスを持つオブジェクトのコレクションの名前付き記述と呼ばれます。 グラフィカルに、クラスは通常、長方形として表されます。 各クラスには、他のすべてのクラスと一意に区別できる名前 (テキスト文字列) が必要です。 クラス属性 このプロパティのインスタンスが取ることができる値のセットを記述するクラスの名前付きプロパティです。 クラスは、任意の数の属性を持つことができます (特に、属性を持たないことはできません)。 属性によって表現されるプロパティは、モデル化されたエンティティのプロパティであり、特定のクラスのすべてのオブジェクトに共通です。 したがって、属性はオブジェクトの状態の抽象化です。 どのクラス オブジェクトのどの属性にも何らかの値が必要です。 いわゆるリレーションシップは、外部キーの宣言を使用して実装されます (以前にも同様の現象に遭遇しました)。つまり、リレーションシップでは、他のリレーションシップの主キーまたは候補キーを参照する外部キーが宣言されます。 そしてこれにより、いくつかの異なる独立した基本的な関係が、データベースと呼ばれる単一のシステムに「リンク」されます。 さらに、エンティティ関係モデルのグラフィカルな基礎を形成する図は、統一モデリング言語 UML を使用して表されます。 オブジェクト指向モデリング言語である UML (または統一モデリング言語) に関する書籍は非常に多く、その多くはロシア語に翻訳されています (一部はロシア人の著者によって書かれています)。 一般に、UML を使用すると、さまざまなタイプのシステムをモデル化できます: 純粋なソフトウェア、純粋なハードウェア、ソフトウェアとハードウェアの混合、明示的に人間の活動を含むなど。 しかし、とりわけ、すでに述べたように、UML 言語はリレーショナル データベースの設計に積極的に使用されています。 このために、言語のごく一部 (クラス図) が使用されますが、それでも完全ではありません。 リレーショナル データベース設計の観点からは、モデリング機能は ER ダイアグラムの機能と大差ありません。 また、リレーショナル データベース設計のコンテキストにおいて、ER ダイアグラムの使用に基づく構造設計方法と UML 言語の使用に基づくオブジェクト指向方法は、主に用語のみが異なることを示したいと思いました。 ER モデルは UML よりも概念的に単純であり、概念、用語、およびアプリケーション オプションが少なくなっています。 さまざまなバージョンの ER モデルがリレーショナル データベース設計をサポートするために特別に開発されており、ER モデルにはリレーショナル データベース設計者の実際のニーズを超える機能がほとんど含まれていないため、これは理解できます。 UML はオブジェクトの世界に属します。 この世界は、リレーショナルな世界よりもはるかに複雑です (お望みであれば、より理解できず、より混乱します)。 UML はあらゆるオブジェクト指向の統合モデリングに使用できるため、この言語には、リレーショナル データベース設計の観点からは冗長な概念、用語、およびユース ケースが多数含まれています。 クラス図の一般的なメカニズムから、リレーショナル データベースの設計に本当に必要なものを抽出すると、異なる表記法と用語を使用した正確な ER 図が得られます。 UML でクラス名を作成するときに、文字、数字、さらには句読点の任意の組み合わせが許可されているのは興味深いことです。 ただし、実際には、大文字で始まる短くて意味のある形容詞と名詞をクラス名として使用することをお勧めします。 (ダイアグラムの概念については、講義の次の段落で詳しく説明します。) 1. 結合の種類と多重度 データベース スキーマの設計における関係間の関係は、エンティティ クラスを結ぶ線として表されます。 さらに、接続の各端は、名前 (つまり、接続のタイプ) と接続におけるクラスの役割の多重度によって特徴付けることができます (また、一般的にそうする必要があります)。 多重度と接続の種類の概念をより詳細に検討してみましょう。 多重度 (多重度) は、特定の役割を持つエンティティ クラスの属性が、何らかの関係の各インスタンスに参加できる、または参加する必要がある数を示す特性です。 関係ロールのカーディナリティを設定する最も一般的な方法は、特定の数値または範囲を直接指定することです。 たとえば、「1」を指定すると、特定のロールを持つ各クラスがこの接続のインスタンスに参加する必要があり、このロールを持つクラスの 0 つのオブジェクトだけが接続の各インスタンスに参加できることを示します。 範囲「1..XNUMX」を指定すると、特定のロールを持つクラスのすべてのオブジェクトがこの関係のインスタンスに参加する必要はありませんが、関係の各インスタンスに参加できるオブジェクトは XNUMX つだけであることを示します。 多重度について詳しく説明しましょう。 データベース設計システムの典型的で最も一般的なカーディナリティは、次のカーディナリティです。 1) 1 - 対応する端での接続の多重度は XNUMX です。 2) 0...1 - この表記形式は、対応する端での指定された接続の多重度が XNUMX を超えることができないことを意味します。 3) 0... ∞ - この多重度は単に「多い」と解読されます。 興味深いのは、原則として「たくさん」が「何もない」ことを意味するということです。 4) 1... ∞ - この指定は、多重度「XNUMX つ以上」に与えられました。 さまざまな多重度のリンクを使用した作業を説明する簡単な図の例を挙げましょう。
この図によると、各切符売り場には多くの切符があり、各切符は XNUMX つの (それ以上の) 切符売り場に配置されていることが容易に理解できます。 ここで、最も一般的なリンクの種類または名前を考えてみましょう。 それらをリストしましょう: 1) 1: 1 - この指定は接続に与えられました」一対一」、つまり、いわば、XNUMX つのセットの XNUMX 対 XNUMX の対応です。 2) 1 : 0... ∞ - これは「」のような接続の指定です。一対多簡潔にするために、このような関係は「1:M」と呼ばれます。前に検討した図では、ご覧のとおり、まさにそのような名前の関係があります。 3) 0... ∞ : 1 - これは前の接続の反転、またはタイプ「」の接続です。多対一"; 4) 0... ∞ : 0... ∞ は、「」のような接続の指定です。多対多"、つまり、リンクの両端に多くの属性があります。 5) 0... 1 : 0... 1 - これは、以前に紹介した「XNUMX 対 XNUMX」タイプの接続に似た接続であり、「」と呼ばれます。XNUMXつ以下からXNUMXつ以下"; 6) 0... 1 : 0... ∞ - これは XNUMX 対多の接続に似た接続であり、「XNUMX 対多以上ではない」と呼ばれます。 7) 0... ∞ : 0... 1 - これは多対 XNUMX タイプの接続に似た接続であり、「」と呼ばれます。多くからXNUMXつまで". ご覧のとおり、最後の XNUMX つの接続は、「XNUMX」の多重度を「XNUMX 以下」の多重度に置き換えることによって、講義で XNUMX、XNUMX、XNUMX の番号の下にリストされている接続から取得されました。 2. ダイアグラム。 チャートの種類 最後に、ダイアグラムとそのタイプの検討に直接進みましょう。 一般に、論理モデルには XNUMX つのレベルがあります。 これらのレベルは、データ構造に関する情報の表現の深さが異なります。 これらのレベルは、次の図に対応しています。 1) プレゼンテーション図; 2) キーダイアグラム; 3) 完全な属性図。 これらのタイプの図のそれぞれを分析し、データ構造に関する情報の表現の深さの違いの意味を詳細に説明しましょう。 1. プレゼンテーション図. このような図では、エンティティの最も基本的なクラスとそれらの関係のみが説明されています。 このような図のキーはまったく説明されていない可能性があり、したがって、接続はまったく個別化されていない可能性があります。 したがって、多対多の関係は許容されますが、通常は回避されるか、存在する場合は微調整されます。 複合属性と多値属性も完全に有効ですが、そのような属性を持つ基本関係は通常の形式に還元されないことを以前に書きました。 興味深いことに、検討した XNUMX つのタイプのダイアグラムのうち、最後のタイプ (完全な属性ダイアグラム) だけが、提示されたデータが何らかの標準形式であると想定しています。 すでに検討されているプレゼンテーション図と次のキー図は、そのようなことを意味するものではありません。 このような図は通常、プレゼンテーションに使用されます (したがって、その名前 - プレゼンテーション、つまり、過度の詳細が必要ないプレゼンテーションやデモンストレーションに使用されます)。 データベースを設計するときは、特定のデータベースが情報を扱う分野の専門家に相談する必要がある場合があります。 そして、プログラミングから離れた専門家から必要な情報を得るために、具体的な詳細を過度に明確にする必要はまったくないため、プレゼンテーション図も使用されます。 2. キーダイアグラム. プレゼンテーション ダイアグラムとは異なり、キー ダイアグラムは、エンティティのすべてのクラスとそれらの関係を必然的に記述しますが、主キーのみに関して記述します。 ここでは、多対多の関係がすでに必然的に詳細化されています (つまり、このタイプの関係を純粋な形でここで指定することはできません)。 多値属性は、プレゼンテーション図と同じように引き続き使用できますが、キー図に存在する場合、通常は独立したエンティティ クラスに変換されます。 しかし、不思議なことに、明確な属性が不完全に表現されたり、複合として記述されたりすることがあります。 これらの「自由」は、プレゼンテーションやキー ダイアグラムなどのダイアグラムではまだ有効ですが、基本関係が正規化されていないと判断されるため、次のタイプのダイアグラムでは許可されません。 したがって、将来のキー ダイアグラムは、既に記述されたエンティティ クラスの「ぶら下がっている」属性のみを想定していると結論付けることができます。それに必要な属性を追加し、最も重要なリンクをすべて指定します。 3. 完全な属性図. 完全な属性図は、上記のエンティティのすべてのクラス、それらの属性、およびこれらのエンティティ クラス間の関係を最も詳細に記述します。 原則として、このようなチャートは第 XNUMX 正規形のデータを表すため、このようなチャートで記述される基本的な関係では、複合属性または多値属性が許可されないのは当然です。多くの関係。 ただし、完全な属性チャートにはまだ欠点があります。つまり、データ表示に関して最も完全なチャートとは言えません。 たとえば、完全な属性図を使用する場合の特定のデータベース管理システムの特性はまだ考慮されておらず、特に、データ型は、必要な論理レベルのモデリングに必要な範囲でのみ指定されています。 3. 関連付けとキーの移行 少し前に、データベース内のリレーションシップについて説明しました。 特に、関係の外部キーを宣言するときに関係が確立されました。 しかし、コースのこのセクションでは、もはや基本的な関係についてではなく、エンティティのキャッシュ レジスタについて話します。 この意味で、関係を確立するプロセスは依然としてさまざまなキーの宣言に関連付けられていますが、ここではエンティティ クラスのキーについて話しています。 つまり、関係を確立するプロセスは、あるエンティティ クラスの単純または複合主キーを別のクラスに転送することに関連付けられています。 そのような転送のプロセスは、とも呼ばれます キーの移行. この場合、主キーが転送されるエンティティ クラスが呼び出されます。 親クラス、および外部キーが移行されるエンティティのクラスが呼び出されます 子クラス エンティティ。 子エンティティ クラスでは、キー属性は外部キー属性のステータスを受け取り、独自の主キーの形成に関与する場合と関与しない場合があります。 したがって、主キーが親から子エンティティ クラスに移行されると、親クラスの主キーを参照する外部キーが子クラスに表示されます。 キーの移行を形式的に表現する便宜上、次のキー マーカーを導入します。 1) PK - これは、主キー (主キー) の属性を表す方法です。 2) FK - このマーカーを使用して、外部キー (外部キー) の属性を示します。 3) PFK - このようなマーカーを使用して、主/外部キーの属性を示します。つまり、エンティティ クラスの唯一の主キーの一部であり、同時に同じエンティティ クラスの外部キーの一部である属性を示します。 . したがって、PK および FK マーカーを持つエンティティ クラスの属性は、このクラスの主キーを形成します。 FK マーカー付きの属性と PFK は、このエンティティ クラスのいくつかの外部キーの一部です。 一般に、キーはさまざまな方法で移行でき、そのようなさまざまなケースごとに、何らかの接続が発生します。 では、鍵の移行方式に応じて、どのような種類のリンクがあるかを考えてみましょう。 合計で、XNUMX つの主要な移行スキームがあります。 1. 移行スキーム ∀PK (PK |→PFK); このエントリでは、記号 "|→" は "移行" の概念を意味します。つまり、上記の式は次のように読み取られます: 親エンティティ クラスの主キー PK の任意の (各) 属性が、主キー PFもちろん、これはこのクラスの外部キーでもあります。 この場合、例外なく、親エンティティ クラスのすべてのキー属性を子エンティティ クラスに移行する必要があるという事実について話しています。 このタイプの接続は、 識別、親エンティティ クラスのキーは、子エンティティの識別に完全に関与するためです。 識別タイプのリンクの中には、さらに XNUMX つの可能な独立したタイプのリンクがあります。 そのため、識別リンクには次の XNUMX 種類があります。 1) 完全に識別する. 識別関係は、親エンティティ クラスの移行主キーの属性が子エンティティ クラスの主 (および外部) キーを完全に形成する場合にのみ、完全に識別されていると言われます。 完全識別関係は時々呼ばれます カテゴリカル、完全に識別される関係は、すべてのカテゴリにわたって子エンティティを識別するためです。 2) 完全に特定していない. 識別関係は、親エンティティ クラスの移行主キーの属性が子エンティティ クラスの主キー (および同時に外部キー) を部分的にしか形成しない場合にのみ、不完全識別と呼ばれます。 したがって、マーカー付きのキーに加えて PFK には、PK とマークされたキーもあります。 この場合、子エンティティ クラスの外部キー PFK は、親エンティティ クラスの主キー PK によって完全に決定されますが、単にこの子関係の主キー PK が親の主キー PK によって決定されるわけではありません。エンティティ クラス、それはそれ自体になります。 2. 移住のスキーム ∃PK (PK |→ FK); このような移行スキームは、次のように解釈する必要があります。移行中に、子エンティティ クラスの必須の非キー属性に転送される、親エンティティ クラスの主キー属性があります。 したがって、この場合、前のケースのように、親エンティティ クラスの主キー属性のすべてではなく一部が子エンティティ クラスに転送されるという事実について話しています。 さらに、以前の移行スキームが子リレーションの主キーへの移行を定義し、それが同時に外部キーにもなった場合、移行の最後のタイプは、親エンティティ クラスの主キー属性が通常のエンティティ クラスに移行することを決定します。 、最初は非キー属性で、その後外部キーステータスを取得します。 このタイプの接続は、 非識別、実際には、親キーは子エンティティの形成に完全には関与していないため、単にそれらを識別しません。 非識別関係の中で、考えられる XNUMX つのタイプの関係も区別されます。 したがって、非識別関係には次の XNUMX つのタイプがあります。 1) 必然的に非識別性. 非識別関係は、子エンティティ クラスのすべての移行キー属性の Null 値が禁止されている場合にのみ、必然的に非識別であると言われます。 2) オプションで非識別. 非識別関係は、子エンティティ クラスの一部の移行キー属性に null 値が許可されている場合にのみ、必ずしも非識別とは限りません。 提示された資料を体系化し、理解する作業を容易にするために、上記のすべてを次の表の形式で要約します。 また、この表には、どのタイプの関係 (「XNUMX 対 XNUMX を超えない」、「多対 XNUMX」、「多対 XNUMX を超えない」) がどのタイプの関係 (完全に識別できるか、完全ではない) に対応するかについての情報も含まれます。識別している、必ずしも識別していない、必ずしも識別していない)。 したがって、親エンティティ クラスと子エンティティ クラスの間には、関係の種類に応じて、次のような関係が確立されます。
したがって、最後のものを除くすべてのケースで、参照は空ではない (null ではない) → 1 であることがわかります。 最後の接続を除くすべてのケースで、接続の親側で多重度が「XNUMX」に設定されている傾向に注意してください。 これは、これらの関係 (つまり、完全に識別されるタイプ、完全に識別されないタイプ、および必ずしも識別されないタイプの関係) の場合の外部キーの値は、必ず次の主キーの値に対応する (さらに、唯一の) 必要があるためです。親エンティティ クラス。 そして後者の場合、外部キーの値が Null 値 (FK: null 有効フラグ) と等しくなる可能性があるため、多重度は親の端で「XNUMX を超えない」に設定されます。関係。 さらに分析を進めます。 接続の子側では、最初の場合を除いて、多重度は「多」に設定されます。 これは、XNUMX 番目のケースのように識別が不完全なため (または XNUMX 番目と XNUMX 番目のケースではそのような識別がまったくない)、親エンティティ クラスの主キーの値が値の中で繰り返し発生する可能性があるためです。子クラスの外部キーの。 最初のケースでは、関係は完全に識別されるため、親エンティティ クラスの主キーの属性は、子エンティティ クラスのキーの属性の中で XNUMX 回しか発生しません。 第12回 実体クラスの関係 したがって、図とそのタイプ、多重度と関係のタイプ、およびキーの移行のタイプなど、これまでに経験したすべての概念は、同じ関係についての資料を調べるのに役立ちますが、すでに特定のクラス間エンティティ。 その中には、これから見ていくように、さまざまな種類のつながりもあります。 1. 階層再帰関係 検討するエンティティクラス間の最初のタイプの関係は、いわゆる 階層再帰関係. 一般に 再帰 (または 再帰リンク) は、エンティティ クラスとそれ自体の関係です。 時々、生活状況との類推により、そのようなつながりは「釣り針」とも呼ばれます。 階層再帰関係 (または単に 階層再帰) は、「最大で XNUMX 対多」タイプの再帰的な関係です。 階層再帰は、データをツリー構造に格納するために最も一般的に使用されます。 階層的な再帰関係を指定する場合、親エンティティ クラス (この特定のケースでは子エンティティ クラスとしても機能する) の主キーを、同じエンティティ クラスの必須の非キー属性への外部キーとして移行する必要があります。 これはすべて、「階層再帰」の概念そのものの論理的整合性を維持するために必要です。 したがって、上記のすべてを考慮に入れると、階層的な再帰関係は 必ずしも特定できないわけではありません 他の種類の関係が使用された場合、外部キーの Null 値は無効になり、再帰は無限になるためです。 また、同じ名前で同じエンティティ クラスに属性を XNUMX 回出現させることはできないことを覚えておくことも重要です。 したがって、移行されたキーの属性には、いわゆるロール名を指定する必要があります。 したがって、階層的な再帰関係では、ノードの属性は、直接の祖先であるノードの主キーへのオプションの参照である外部キーで拡張されます。 リレーショナル データ モデルで階層再帰を実装するプレゼンテーションとキー ダイアグラムを作成し、表形式の例を示しましょう。 最初にプレゼンテーション図を作成しましょう。
それでは、より詳細なキー ダイアグラムを作成しましょう。
階層的な再帰的な関係のようなタイプの関係を明確に示す例を考えてみましょう。 前の例と同様に、「祖先コード」属性と「ノード コード」属性で構成される次のエンティティ クラスが与えられたとします。 まず、このエンティティ クラスの表形式の表現を示しましょう。
次に、このクラスのエンティティを表す図を作成しましょう。 これを行うには、これに必要なすべての情報をテーブルから選択します。コード「one」を持つノードの祖先が存在しないか定義されていないため、ノード「one」が頂点であると結論付けます。 同じノード「one」は、コード「two」および「three」を持つノードの祖先です。 次に、コード「XNUMX」のノードには、コード「XNUMX」のノードとコード「XNUMX」のノードの XNUMX つの子があります。 そして、コード「three」を持つノードには、コード「six」を持つノードが XNUMX つしか子がありません。 したがって、上記のすべてを考慮して、前のテーブルに含まれるデータに関する情報を反映するツリー構造を構築しましょう。
このように、階層的な再帰関係を使用してツリー構造を表現すると非常に便利であることがわかりました。 2. ネットワーク再帰通信 エンティティクラス間のネットワーク再帰接続は、いわば、すでに通過した階層再帰接続の多次元類似物です。 階層再帰が「最大で XNUMX 対多」の再帰関係として定義されている場合のみ、 ネットワーク再帰 同じ再帰関係を表しますが、「多対多」タイプのみです。 エンティティの多くのクラスが両側でこの接続に参加するため、ネットワーク接続と呼ばれます。 階層再帰との類似性からすでに推測できるように、ネットワーク再帰タイプのリンクはグラフ データ構造を表すように設計されています (階層リンクは、ツリー構造の実装にのみ使用されます)。 ただし、ネットワーク再帰のタイプの接続では、「多対多」タイプの接続が指定されているため、追加の詳細なしでは実行できません。 したがって、スキーマ内のすべての多対多の関係を改善するには、祖先と子孫の関係の親または子孫へのすべての参照を含む新しい独立したエンティティ クラスを作成する必要があります。 そのようなクラスは一般的に呼ばれます 連想エンティティ クラス. 私たちの特定のケース (私たちのコースで検討するデータベース) では、連想エンティティは独自の追加属性を持たず、呼び出されます 呼び出しこれは、祖先と子孫の関係を参照して名前を付けるためです。 したがって、ホストを表すエンティティ クラスの主キーは、関連付けられたエンティティ クラスに XNUMX 回移行する必要があります。 このクラスでは、移行されたキーが一緒になって複合主キーを形成する必要があります。 前述のことから、ネットワーク再帰を使用する場合のリンクの確立は、完全な識別だけであってはならないと結論付けることができます。 階層再帰関係を使用する場合と同様に、ネットワーク再帰を関係として使用する場合、同じ名前で同じエンティティ クラスに属性を XNUMX 回出現させることはできません。 したがって、前回と同様に、移行キーのすべての属性がロール名を受け取る必要があることが明確に規定されています。 ネットワーク再帰通信の動作を説明するために、リレーショナル データ モデルでネットワーク再帰を実装するプレゼンテーションとキー ダイアグラムを作成しましょう。 プレゼンテーション図から始めましょう。
それでは、より詳細なキー ダイアグラムを作成しましょう。
ここで何が見えるでしょうか? そして、この主要な図の両方の接続が「多対 0」接続であることがわかります。 さらに、多重度「XNUMX... ∞」または多重度「多」は、エンティティの名前付けクラスに面する接続の終端にあります。 確かに、多くのリンクがありますが、それらはすべて、「Nodes」エンティティ クラスの主キーである XNUMX つのノード コードを参照しています。 最後に、エンティティ クラスによるネットワーク再帰などのタイプの接続の操作を示す例を考えてみましょう。 あるエンティティ クラスの表形式の表現と、リンクに関する情報を含む名前付けエンティティ クラスが与えられたとします。 これらの表を見てみましょう。 結び目:
リンク:
実際、上記の表現は網羅的です。ここでエンコードされたグラフ構造を簡単に再現するために必要なすべての情報を提供します。 たとえば、コードが「XNUMX」のノードには、コードが「XNUMX」、「XNUMX」、「XNUMX」の XNUMX つの子があることが障害なくわかります。 また、コード「XNUMX」と「XNUMX」のノードには子孫がまったくなく、コード「XNUMX」のノードには (ノード「XNUMX」と同様に) コード「XNUMX」、「XNUMX」、「XNUMX」の XNUMX つの子孫があることもわかります。三つ"。 上で与えられたエンティティクラスによって与えられたグラフを描きましょう:
したがって、作成したグラフは、エンティティ クラスがネットワーク再帰型接続を使用してリンクされたデータです。 3. 協会 特定の講義コースの考察に含まれるすべての種類の接続のうち、再帰的な接続は XNUMX つだけです。 これらは、それぞれ階層リンクとネットワーク再帰リンクです。 考慮しなければならない他のすべてのタイプの関係は再帰的ではありませんが、原則として、複数の親エンティティ クラスと複数の子エンティティ クラスの関係を表します。 さらに、ご想像のとおり、親エンティティ クラスと子エンティティ クラスが一致することはありません (実際、再帰について話しているわけではありません)。 講義のこのセクションで説明する接続はアソシエーションと呼ばれ、非再帰型の接続を正確に指します。 したがって、接続は呼び出されました 協会、複数の親エンティティ クラスと XNUMX つの子エンティティ クラスの間の関係として実装されます。 同時に、興味深いことに、この関係はさまざまなタイプの関係によって記述されます。 また、ネットワーク再帰のように、関連付け中に存在できる親エンティティ クラスは XNUMX つだけですが、そのような状況でも、子エンティティ クラスからの関係の数は少なくとも XNUMX つでなければならないことに注意してください。 興味深いことに、関連付けにもネットワーク再帰にも、特別な種類のエンティティ クラスがあります。 このようなクラスの例は、子エンティティ クラスです。 実際、一般的なケースでは、アソシエーションでは、子エンティティ クラスが呼び出されます。 連想エンティティ クラス. 連想エンティティ クラスが独自の追加属性を持たず、親エンティティ クラスから主キーと共に移行される属性のみを含む特殊なケースでは、そのようなクラスが呼び出されます。 命名エンティティのクラス. ご覧のとおり、ネットワークの再帰接続における連想エンティティと名前付けエンティティの概念には、ほぼ絶対的な類推があります。 ほとんどの場合、関連付けは多対多の関係を調整 (解決) するために使用されます。 このステートメントを説明しましょう。 たとえば、特定の病院で特定の医師を受け入れる計画を説明する次のプレゼンテーション図が与えられたとします。
この図は文字通り、病院には多くの医師と多くの患者がいて、医師と患者の間には他の関係や対応がないことを意味します。 したがって、もちろん、このようなデータベースでは、病院管理者にとって、さまざまな患者に対してさまざまな医師との予約をどのように手配するかが明確になることはありません。 ここで使用される多対多の関係は、さまざまな医師と患者の間の関係を具体化するために、つまり、すべての医師とその患者の予定のスケジュールを合理的に編成するために、単純に詳細化する必要があることは明らかです。病院。 それでは、より詳細なキー ダイアグラムを作成しましょう。このダイアグラムには、既存の多対多の関係がすべて詳細に示されています。 これを行うために、それに応じて新しいエンティティ クラスを導入します。これを「Receive」と呼びます。これは、連想エンティティ クラスとして機能します (後で、これが単なる命名クラスではなく、連想エンティティ クラスになる理由を説明します)。前に説明したエンティティ)。 したがって、キーダイアグラムは次のようになります。
これで、新しいクラス「受信」が命名エンティティのクラスではない理由が明確にわかりました。 結局のところ、このクラスには独自の追加属性「Date - Time」があるため、定義によれば、新しく導入されたクラス「受付」は連想エンティティのクラスです。 このクラスは、「Doctors」エンティティ クラスと「Patient」エンティティ クラスを、この予約またはその予約が実行される時間によって相互に「関連付け」ます。これにより、このようなデータベースでの作業がより便利になります。 このように、「日付 - 時間」属性を導入することで、さまざまな医師が必要とする勤務スケジュールを文字通り整理しました。 また、"受付" エンティティ クラスの外部主キー "Doctor's Code" が、"Doctors" エンティティ クラスの同じ名前の主キーを参照していることもわかります。 同様に、「受付」エンティティクラスの外部主キー「患者コード」は、「患者」エンティティクラスの同名の主キーを参照します。 この場合、当然のことながら、実体クラス「医師」と「患者」が親であり、関連実体クラス「受付」が唯一の子となります。 前のプレゼンテーション図の多対多の関係が完全に詳細になっていることがわかります。 上記のプレゼンテーション図に見られる XNUMX つの多対多の関係の代わりに、XNUMX つの多対 XNUMX の関係があります。 最初のリレーションシップの子側には多重度 "many" があります。これは文字通り、"Reception" エンティティ クラスに多くの医師がいる (全員が病院にいる) ことを意味します。 そして、この関係の親の端にあるのは「XNUMX」の多重度ですが、これはどういう意味ですか? これは、「受付」エンティティ クラスでは、特定の各医師の使用可能なコードのそれぞれが無期限に何度も発生する可能性があることを意味します。 実際、病院のスケジュールでは、同じ医師のコードが、異なる日と時間に何度も発生します。 そして、これは同じコードですが、すでに "Doctors" エンティティ クラスにあり、一度しか発生しません。 実際、すべての病院の医師のリスト (および "Doctors" エンティティ クラスはそのようなリストに他なりません) では、各特定の医師のコードは XNUMX 回しか存在できません。 親クラス「Patient」と子クラス「Patient」の関係でも同様のことが起こります。 すべての入院患者のリスト ("Patients" エンティティ クラス内) では、特定の各患者のコードは XNUMX 回だけ出現します。 しかし一方で、予約のスケジュール (エンティティ クラス「受付」) では、特定の患者の各コードが任意に何度も発生する可能性があります。 そのため、結合の両端の多重度はこのように配置されています。 リレーショナル データ モデルでのアソシエーションの実装の例として、顧客と請負業者の間の会議のスケジュールを記述するモデルを構築してみましょう。コンサルタントの参加は任意です。 ダイアグラムの構成をすべて詳細に検討する必要があり、プレゼンテーション ダイアグラムではそのような機会を提供できないため、プレゼンテーション ダイアグラムについて詳しくは説明しません。 では、顧客、請負業者、コンサルタントの関係の本質を反映したキー ダイアグラムを作成しましょう。
それでは、上記のキー ダイアグラムの詳細な分析を始めましょう。 まず、「Graph」クラスは連想エンティティのクラスですが、前の例のように名前付きエンティティのクラスではありません。自分の属性。 これは「日付 - 時間」属性です。 次に、子エンティティ クラス「Chart」「Customer code」、「Executor code」、および「Date - Time」の属性が、このエンティティ クラスの複合主キーを形成していることがわかります。 「Advisor Code」属性は、単に「Chart」エンティティ クラスの外部キーです。 条件によっては会議でのコンサルタントの存在は必要ないため、この属性はその値の中で Null 値を許可することに注意してください。 さらに、XNUMX 番目に、(利用可能な XNUMX つのリンクのうち) 最初の XNUMX つのリンクが完全に識別されていないことに注意してください。 つまり、どちらの場合も移行キー (主キー「顧客コード」と「実行者コード」) が「Graph」エンティティ クラスの主キーを完全には形成しないため、完全には識別されません。 実際、複合主キーの一部でもある「Date - Time」属性は残ります。 これらの不完全な識別結合の両方の端に、多重度「XNUMX」と「多数」がマークされています。 これは、(医師と患者に関する例のように) 異なるエンティティークラスでの顧客または実行者のコードへの言及の違いを示すために行われます。 実際、「Graph」エンティティ クラスでは、任意の顧客または請負業者のコードを必要な回数だけ使用できます。 したがって、この、子、接続の端には、「多数」の多重度があります。 また、エンティティ クラス「Customers」または「Contractors」では、顧客または請負業者の各コードがそれぞれ XNUMX 回だけ発生します。これらのエンティティ クラスはそれぞれ、すべての顧客と実行者の完全なリストに過ぎないからです。 したがって、接続の親側であるこの時点で、多重度は「XNUMX」になります。 そして最後に、XNUMX 番目の関係、つまり「Graph」エンティティ クラスと「Consultants」エンティティ クラスの関係は、必ずしも非識別的ではないことに注意してください。 実際、この場合、「コンサルタント」エンティティ クラスのキー属性「コンサルタント コード」を、同じ名前の「グラフ」エンティティ クラスの非キー属性、つまり主キーに転送することについて話しています。 「Graph」エンティティ クラスの「Consultants」エンティティ クラスは、このクラスの主キーをすでに識別していません。 さらに、前述のように、「Advisor Code」属性は Null 値を許可するため、ここでは正確に非識別関係が使用されます。 したがって、「Advisor Code」属性は、外部キーのステータスのみを取得します。 この不完全な非識別リンクの親と子の端に配置されたリンクの多様性にも注意を払いましょう。 その親 end の多重度は「XNUMX 以下」です。 実際、完全に非識別ではない関係の定義を思い出すと、「グラフ」エンティティ クラスの「コンサルタント コード」属性は、すべてのコンサルタントのリストの複数のコンサルタント コードに対応できないことがわかります。 (これは「コンサルタント」エンティティ クラスです)。 そして一般的に、どのコンサルタントコードにも対応しないことが判明する場合があります (Null 値の許容性に関するチェックボックスを思い出してください。コンサルタントコード: Null)。一般的に言えば、顧客と請負業者の間の会議は必要ありません。 4. 一般化 検討するエンティティ クラス間の別のタイプの関係は、次の形式の関係です。 一般化. また、非再帰的な関係でもあります。 だから、次のような関係 一般化 XNUMX つの親エンティティ クラスと複数の子エンティティ クラスの関係として実装されます (複数の親エンティティ クラスと XNUMX つの子エンティティ クラスを扱う以前の Association 関係とは対照的です)。 汎化関係を使用してデータ表現ルールを定式化する場合、XNUMX つの親エンティティ クラスと複数の子エンティティ クラスのこの関係は、完全に識別された関係 (つまり、カテゴリ関係) によって記述されるとすぐに言わなければなりません。 完全に識別される関係の定義を思い出すと、一般化を使用すると、親エンティティ クラスの主キーの各属性が子エンティティ クラスの主キー、つまり、親の主移行キーの属性に転送されると結論付けます。エンティティ クラスは、すべての子エンティティ クラスの主キーを完全に形成し、それらを識別します。 一般化がいわゆる カテゴリ階層 または継承階層。 この場合、親エンティティ クラスは、 ジェネリック エンティティ クラス、すべての子クラスまたはいわゆるエンティティに共通の属性によって特徴付けられる カテゴリ エンティティ つまり、親エンティティ クラスは、そのすべての子エンティティ クラスを文字通り一般化したものです。 リレーショナル データ モデルでの汎化の実装の例として、次のモデルを構築します。 このモデルは、「学生」の一般化された概念に基づいており、「学童」、「学生」、および「大学院生」という次のカテゴリ概念を記述します (つまり、次の子エンティティ クラスを一般化します)。 そこで、一般化型の接続によって記述された、親エンティティ クラスと子エンティティ クラスの間の関係の本質を反映するキー ダイアグラムを作成しましょう。
それで、私たちは何を見ますか? まず、基本的な関係 (または同じエンティティ クラスから) の「学童」、「学生」、および「大学院生」のそれぞれが、「クラス」、「コース」、「学年」などの独自の属性に対応します。 " . これらの各属性は、独自のエンティティ クラスのメンバーを特徴付けます。 また、親エンティティ クラス「Students」の主キーが各子エンティティ クラスに移行し、そこで主外部キーを形成することもわかります。 これらの接続の助けを借りて、対応する子エンティティ クラス自体では見つからない情報について、学生の名前、姓、および父称のコードによって判断できます。 次に、エンティティ クラスの完全な識別 (またはカテゴリ) 関係について話しているため、親エンティティ クラスとその子クラスの間の関係の多様性に注意を払います。 これらの各リンクの親側の多重度は「XNUMX」であり、リンクの各子側の多重度は「最大 XNUMX」です。 エンティティ クラスの完全な識別関係の定義を思い出すと、"Students" エンティティ クラスの主キーである本当に一意の学生コードは、各子エンティティでそのようなコードを持つ最大 XNUMX つの属性を指定することが明らかになります。クラス「学生」、「学生」、および大学院生。 したがって、すべての結合にはそのような多重度があります。 カスケード型の参照整合性を維持するためのルールの定義を使用して、基本的な関係「学童」と「学生」を作成するための演算子の断片を書きましょう。 したがって、次のようになります。 テーブルの生徒を作成する ... 主キー(学生コード) 外部キー (学生 ID) は学生 (学生 ID) を参照します 更新カスケードで カスケード削除時 テーブルの学生を作成する ... 主キー(学生コード) 外部キー (学生 ID) は学生 (学生 ID) を参照します 更新カスケードで カスケード削除時。 したがって、子エンティティ クラス (または関係) "Student" では、親エンティティ クラス (または関係) "Students" を参照する主外部キーが指定されていることがわかります。 参照整合性を維持するためのカスケード ルールは、親エンティティ クラス「Students」の属性が削除または更新されると、対応する子関係「Student」の属性が自動的に (カスケード) 更新または削除されることを決定します。 同様に、親エンティティクラス「Students」の属性が削除または更新されると、対応する子関係「Students」の属性も自動的に更新または削除されます。 ここで使用されているのはこの参照整合性ルールであることに注意してください。このコンテキスト (学生のリスト) では、情報の削除と更新を禁止し、実際の情報の代わりに未定義の値を割り当てることは合理的ではないためです。 . 次に、前の図で説明したエンティティ クラスの例を、表形式でのみ示します。 したがって、次の関係テーブルがあります。 生徒 - 他のすべての関係の属性に関する情報を結合する親関係:
小学生 - 子関係:
学生 - XNUMX 番目の子関係:
博士課程の学生 - XNUMX 番目の子関係:
実際、エンティティの子クラスには、学生、つまり学童、学生、大学院生の姓、名、父称に関する情報が含まれていないことがわかります。 この情報は、親エンティティ クラスへの参照を通じてのみ取得できます。 また、「Students」エンティティ クラスのさまざまな学生コードが、さまざまな子エンティティ クラスに対応していることがわかります。 したがって、コード「1」Nikolai Zabotin を持つ学生については、彼の名前を除いて、両親関係については何も知られておらず、他のすべての情報 (彼が男子生徒、学生、または大学院生) を参照することによってのみ見つけることができます。対応する子エンティティ クラス (コードによって決定) に。 同様に、コードが親エンティティ クラス "Students" で指定されている残りの生徒と連携する必要があります。 5.構成 合成タイプのエンティティ クラスの関係は、前の XNUMX つのタイプと同様に、再帰的な関係のタイプには属しません。 構成 (または、時々呼ばれるように、 複合集計) は、前述の関係と同様に、XNUMX つの親エンティティ クラスと複数の子エンティティ クラスの関係です。 一般化。 しかし、一般化が完全に識別された関係によって記述されたエンティティ クラスの関係として定義された場合、合成は、不完全に識別された関係によって記述されます。つまり、合成中に、親エンティティ クラスの主キーの各属性がキー属性に移行します。子エンティティ クラスの。 同時に、移行するキー属性は、子エンティティ クラスの主キーを部分的にしか形成しません。 したがって、複合集約 (構成を使用) では、親エンティティ クラス (または 集約する) は、複数の子エンティティ クラス (または コンポーネント)。 この場合、集約のコンポーネント (つまり、親エンティティ クラスのコンポーネント) は、主キーの一部である外部キーを介して集約を参照するため、集約の外部には存在できません。 一般に、複合集計は単純集計の拡張形式です (これについては後で説明します)。 構成 (または複合集約) は、次の事実によって特徴付けられます。 1) アセンブリへの参照は、コンポーネントの識別に含まれます。 2) これらのコンポーネントは集合体の外には存在できません。 必然的に非識別関係を持つ集約 (さらに検討する関係) も、構成要素が集約の外部に存在することを許可しないため、上記の複合集約の実装に近い意味を持ちます。 XNUMX つの親エンティティ クラスと複数の子エンティティ クラスの間の関係を説明するキー ダイアグラムを作成してみましょう。つまり、複合集約型のエンティティ クラスの関係を説明します。 これを、あるキャンパスの建物とその教室、エレベーターを含む建物の構成を表すキー ダイアグラムとします。 したがって、この図は次のようになります。
それでは、先ほど作成した図を見てみましょう。 その中に何が見えますか? まず、この複合集計で使用されている関係が実際に識別されており、実際には完全には識別されていないことがわかります。 結局、親エンティティ クラス「Buildings」の主キーは、子エンティティ クラス「Audiences」と「Elevators」の主キーの形成に関与しますが、完全には定義しません。 親エンティティ クラスの主キー「ケース番号」は、両方の子クラスの外部主キー「ケース番号」に移行されますが、この移行されたキーに加えて、両方の子エンティティ クラスにもそれぞれ独自の主キーがあります。 No" および "Elevator No. "、つまり、子エンティティ クラスの複合主キーは、親エンティティ クラスの主キーの部分的に形成された属性にすぎません。 ここで、親クラスと両方の子クラスを接続するリンクの多様性を見てみましょう。 不完全な識別リンクを扱っているため、「XNUMX つ」と「多数」という多重度が存在します。 多重度「XNUMX」は両方の関係の親の端にあり、利用可能なすべてのコーパスのリスト (エンティティ クラス「コーパス」はまさにそのようなリストです) の中で、各数が XNUMX 回だけ出現することを象徴しています (それ以上は存在しません)。それより)倍。 また、「聴衆」クラスと「エレベーター」クラスの属性の中で、建物よりも聴衆 (またはエレベーター) の方が多く、各建物にはいくつかの講堂とエレベーターがあるため、各建物番号は何度も出現する可能性があります。 したがって、すべての教室とエレベーターをリストする場合、必然的に建物番号が繰り返されます。 そして最後に、前のタイプの接続の場合と同様に、基本的な関係 (または、同じことであるエンティティークラス) を作成するためのオペレーターの断片を書き留めましょう。「オーディエンス」と「エレベーター」です。これは、カスケード型の参照整合性を維持するためのルールの定義で行います。 したがって、このステートメントは次のようになります。 テーブル オーディエンスの作成 ... 主キー(コーパス番号、オーディエンス番号) 外部キー (ケース番号) 参照 パターン (ケース番号) 更新カスケードで カスケード削除時 テーブル リフトの作成 ... 主キー(ケース番号、エレベータ番号) 外部キー (ケース番号) 参照 パターン (ケース番号) 更新カスケードで カスケード削除時。 したがって、子エンティティ クラスの必要な主キーと外部キーをすべて設定しました。 参照整合性をカスケードとして維持するルールを再び採用しました。これは、最も合理的であると既に説明したためです。 ここで、検討したすべてのエンティティ クラスの例を表形式で示します。 表の形式の図を使用して反映した基本的な関係を説明しましょう。明確にするために、そこに一定量の指標データを紹介します。 エンクロージャー 親関係は次のようになります。
オーディエンス - 子エンティティ クラス:
エレベーター - 親クラス「Enclosures」の XNUMX 番目の子エンティティ クラス:
したがって、このデータベースでは、すべての建物、教室、およびエレベーターの情報がどのように編成されているかを確認できます。これは、実際の教育機関で使用できます。 6.集計 集約は、コースの一部と見なされるエンティティ クラス間の最後のタイプの関係です。 また、再帰的ではなく、その XNUMX つのタイプのうちの XNUMX つは、以前に考えられていた複合集約と意味が非常に似ています。 このように、 集計 XNUMX つの親エンティティ クラスと複数の子エンティティ クラスとの関係です。 この場合、関係は次の XNUMX 種類の関係によって記述できます。 1) 必然的に非識別リンク。 2) オプションの非識別リンク。 必然的に非識別関係がある場合、親エンティティ クラスの主キーの一部の属性が子クラスの非キー属性に転送され、移行キーのすべての属性の Null 値が禁止されることを思い出してください。 また、必ずしも非識別関係があるとは限りませんが、主キーの移行はまったく同じ原則に従って行われますが、移行するキーの一部の属性に対して Null 値が許可されます。 集約する場合、親エンティティ クラス (または 集約する) は、複数の子エンティティ クラス (または コンポーネント)。 集約のコンポーネント (つまり、親エンティティ クラス) は、主キーの一部ではない外部キーを介して集約を参照します。 必ずしも個人を特定しないリンクではない、集約コンポーネントは集約の外部に存在できます。 必然的に非識別関係を持つ集約の場合、集約の構成要素が集約の外に存在することは許されず、この意味で、必然的に非識別関係を持つ集約は複合集約に近い。 集計タイプの関係が何であるかが明確になったので、この関係の操作を説明するキー ダイアグラムを作成しましょう。 未来の図で、自動車のマークされたコンポーネント (つまり、エンジンとシャシー) を説明してみましょう。 同時に、車の廃止はシャーシの廃止を意味するが、エンジンの同時廃止を意味するものではないと仮定します。 したがって、キーダイアグラムは次のようになります。
では、このキー ダイアグラムで何がわかるでしょうか。 まず、親エンティティ クラス「Cars」と子エンティティ クラス「Engines」との関係は、属性「car #」がその値に null 値を許可するため、必ずしも非識別的であるとは限りません。 同様に、この属性は、条件によるエンジンの廃止が車両全体の廃止に依存しないため、Null 値を許可します。したがって、自動車を廃止するときに必ずしも発生するとは限りません。 また、「Cars」エンティティ クラスの「Engine #」主キーが、「Engines」エンティティ クラスの非キー属性「Engine #」に移行していることもわかります。 同時に、この属性は外部キーのステータスを取得します。 そして、この Engines エンティティ クラスの主キーは Engine Marker 属性であり、親関係のどの属性も参照しません。 次に、親エンティティ クラス「Motors」と子エンティティ クラス「Chassis」の間の関係は、必然的に非識別関係になります。これは、外部キー属性「Car #」がその値に Null 値を許可しないためです。 これは、自動車の廃止が強制的なシャーシの同時廃止を意味するという条件によって知られているために発生します。 ここでは、前の関係の場合と同様に、親エンティティ クラス「Motors」の主キーが、子エンティティ クラス「Chassis」の非キー属性「Car number」に移行されます。 同時に、このエンティティ クラスの主キーは「Chassis Marker」属性であり、「Motors」親関係のどの属性も参照しません。 進む。 トピックを最もよく理解するために、参照整合性を維持するためのルールの定義を使用して、基本的な関係「モーター」と「シャーシ」を作成するための演算子の断片をもう一度書き留めましょう。 テーブル エンジンの作成 ... 主キー (モーターマーカー) 外部キー (車両番号) 参照 Cars (車両番号) 更新カスケードで 削除セット Null の場合 テーブル シャーシの作成 ... 主キー (シャーシ マーカー) 外部キー (車両番号) 参照 Cars (車両番号) 更新カスケードで カスケード削除時。 どこでも参照整合性を維持するために同じルールを使用したことがわかります - カスケード。 ただし、今回は (カスケード ルールに加えて) set Null 参照整合性ルールを使用しました。 また、親エンティティクラス「車」の主キー「車番」の値を削除すると、子リレーション「エンジン」の外部キー「車番」の値が削除される、という条件で使用しました。それを参照すると Null-value が割り当てられます。 7. 属性の統一 特定の親エンティティークラスの主キーの移行中に、意味が一致する異なる親クラスからの属性が同じ子クラスに入る場合、これらの属性を「マージ」する必要があります。つまり、そうする必要があります。 -と呼ばれる 属性の統一. たとえば、従業員が組織で働くことができ、複数の部門にリストされていない場合、「組織コード」属性を統一すると、次のキー ダイアグラムが得られます。
親エンティティクラス「組織」と「部署」から子クラス「従業員」に主キーを移行すると、エンティティクラス「従業員」に属性「組織ID」が入ります。 そしてXNUMX回: 1) マーカーで初めて PF不完全な識別関係を確立する場合は、エンティティ クラス「組織」の K。 2) XNUMX 回目は、必ずしも非識別関係を確立するときに、「Departments」エンティティ クラスから Null 値を受け入れるという条件付きの FK マーカーを使用します。 統合すると、「組織ID」属性は主/外部キー属性のステータスになり、外部キー属性のステータスを吸収します。 統合プロセス自体を示す新しいキー ダイアグラムを作成しましょう。
したがって、属性の統一が行われました。 第13回 エキスパートシステムと知識生産モデル 1. エキスパートシステムの任命 私たちにとってそのような新しい概念に精通するために エキスパートシステム まず、「エキスパート システム」方向の作成と開発の歴史をたどり、次に、エキスパート システムの概念そのものを定義します。 80年代初頭。 XNUMX世紀人工知能の作成に関する研究では、新しい独立した方向性が形成されました。 エキスパートシステム. エキスパート システムに関するこの新しい研究の目的は、特定の種類の問題を解決するために設計された特別なプログラムを開発することです。 まったく新しい知識工学の作成を必要とした、この特別な種類の問題は何ですか? この特殊なタイプのタスクには、あらゆる分野のタスクを含めることができます。 それらを通常の問題と区別する主な点は、人間の専門家がそれらを解決するのは非常に困難な作業のように見えることです。 それから最初のいわゆる エキスパートシステム (専門家の役割はもはや人ではなく機械でした)、そして専門家システムは、普通の人 - 専門家によって得られる解決策に劣らない品質と効率の結果を受け取ります。 エキスパートシステムの作業の結果は、非常に高いレベルでユーザーに説明できます。 エキスパート システムのこの品質は、自身の知識と結論について推論する能力によって保証されます。 エキスパート システムは、エキスパートとのやり取りの過程で、独自の知識を十分に補充することができます。 したがって、完全に形成された人工知能と同等の自信を持って置くことができます。 エキスパート システムの分野の研究者は、専門分野の名前として、ドイツの科学者 E. ファイゲンバウムによって導入された、前述の「知識工学」という用語もよく使用します。専門知識を必要とする難しい応用問題。」 しかし、開発会社の商業的成功はすぐには実現しませんでした。 1960年から1985年までの四半世紀。 人工知能の成功は、主に研究開発に関連しています。 しかし、1985年頃から始まり、1987年から1990年にかけて大規模に. エキスパート システムは、商用アプリケーションで積極的に使用されています。 エキスパートシステムのメリットは非常に大きく、以下のとおりです。 1) エキスパート システム技術は、パーソナル コンピュータで解決される実際に重要なタスクの範囲を大幅に拡大します。そのソリューションは、大きな経済的利益をもたらし、関連するすべてのプロセスを大幅に簡素化します。 2) エキスパート システム テクノロジは、従来のプログラミングのグローバルな問題を解決する上で最も重要なツールの XNUMX つです。たとえば、期間、品質、およびその結果、複雑なアプリケーションを開発するための高コストであり、その結果、経済効果が大幅に削減されました。 ; 3)複雑なシステムの運用と保守には高いコストがかかり、開発自体のコストを数倍超えることが多く、プログラムの再利用性などのレベルが低い。 4) エキスパート システム技術と従来のプログラミング技術との組み合わせは、最初に、プログラマーではなく、通常のユーザーによるアプリケーションの動的変更を提供することによって、ソフトウェア製品に新しい品質を追加します。 第二に、アプリケーションの「透明性」が向上し、グラフィックス、インターフェイス、およびエキスパート システムの相互作用が向上します。 通常のユーザーと主要な専門家によると、近い将来、エキスパート システムは次のアプリケーションを見つけるでしょう。 1) エキスパート システムは、設計、開発、生産、配布、デバッグ、制御、およびサービス提供のすべての段階で主導的な役割を果たします。 2) 広く商業的に流通しているエキスパートシステム技術は、既製のインテリジェントな相互作用モジュールからのアプリケーションの統合において革命的なブレークスルーを提供します。 一般に、エキスパート システムは、いわゆる 非公式のタスクつまり、エキスパートシステムは、形式化された問題の解決に焦点を当てたプログラム開発への従来のアプローチを拒否したり、置き換えたりすることはありませんが、それらを補完することにより、可能性を大幅に拡大します。 これはまさに、単なる人間の専門家にはできないことです。 このような複雑で形式化されていないタスクは、次のような特徴があります。 1) 誤謬、不正確さ、あいまいさ、およびソース データの不完全性と矛盾。 2) 問題領域と解決しようとしている問題に関する知識の誤謬、あいまいさ、不正確さ、不完全さ、および不一致。 3)特定の問題の解決策の空間の大きな次元。 4) そのような非公式な問題を解決する過程における直接的なデータと知識の動的変動。 エキスパート システムは、既知のアルゴリズムの実行ではなく、主に解決策のヒューリスティック検索に基づいています。 これは、ソフトウェア開発に対する従来のアプローチに対するエキスパート システム テクノロジの主な利点の XNUMX つです。 これが、割り当てられたタスクにうまく対処できる理由です。 エキスパートシステムの技術を駆使して、さまざまな問題を解決します。 これらのタスクの主なものをリストします。 1. 解釈. 通訳を行う専門家システムは、状況を説明するためにさまざまな機器の読み取り値を使用することが最も多い。 解釈エキスパート システムは、さまざまな種類の情報を処理することができます。 例として、スペクトル分析データと物質の特性の変化を使用して、その組成と特性を決定します。 また、ボイラー室の測定器の読み取り値を解釈して、ボイラーとその中の水の状態を説明することも一例です。 解釈システムは、ほとんどの場合、読み取り値を直接処理します。 この点で、他のタイプのシステムにはない問題が生じます。 これらの困難は何ですか? これらの問題は、エキスパート システムが、詰まった余分な、不完全な、信頼できない、または不正確な情報を解釈しなければならないという事実により発生します。 したがって、エラーまたはデータ処理の大幅な増加は避けられません。 2. 予測. 何かの予測を実行するエキスパート システムは、特定の状況の確率的条件を決定します。 例としては、悪天候による穀物収穫への被害の予測、世界市場でのガス需要の評価、気象観測所による天気予報などがあります。 予測システムは、モデリング、つまり、プログラミング環境でそれらを再作成するために現実世界でいくつかの関係を表示するプログラムを使用してから、特定の初期データで発生する可能性のある状況を設計することがあります。 3. 各種機器の診断. エキスパート システムは、診断可能なシステムの誤動作の考えられる原因を特定するために、さまざまなコンポーネントの構造に関する状況、動作、またはデータの記述を使用して、このような診断を実行します。 例としては、患者に(医学で)観察される症状による病気の状況の確立があります。 電子回路の故障の識別と、さまざまなデバイスのメカニズムの故障したコンポーネントの識別。 診断システムは、診断を行うだけでなく、トラブルシューティングにも役立つアシスタントであることがよくあります。 このような場合、これらのシステムはユーザーと対話してトラブルシューティングを支援し、問題を解決するために必要なアクションのリストを提供することがあります。 現在、工学や計算機システムへの応用として、多くの診断システムが開発されています。 4. 各種イベントの企画. さまざまな操作の設計を計画するために設計されたエキスパート システム。 システムは、実装を開始する前に、ほぼ完全な一連のアクションを事前に決定します。 このようなイベントの計画の例としては、敵軍に対する優位性を得るために、一定期間、防御と攻撃の両方の軍事作戦の計画を作成することが挙げられます。 5. デザイン. 設計を実行するエキスパート システムは、一般的な状況と関連するすべての要因を考慮して、さまざまな形式のオブジェクトを開発します。 その一例が遺伝子工学です。 6. コントロール. 制御を実行するエキスパート システムは、システムの現在の動作を予想される動作と比較します。 エキスパート システムを観察すると、制御された動作が検出され、期待値と通常の動作または潜在的な逸脱の想定が確認されます。 エキスパート システムの制御は、その性質上、リアルタイムで動作し、制御対象の動作の時間依存およびコンテキスト依存の解釈を実装する必要があります。 例としては、緊急事態を検出するために原子炉内の測定機器の読み取り値を監視したり、集中治療室の患者からの診断データを評価したりすることが含まれます。 7. Управление. 結局のところ、制御を実行するエキスパート システムがシステム全体の動作を非常に効果的に管理することは広く知られています。 例としては、さまざまな業界の管理、およびコンピューター システムの配布があります。 コントロール エキスパート システムには、長期間にわたってオブジェクトの動作を制御するための監視コンポーネントが含まれている必要がありますが、既に分析されたタスク タイプの他のコンポーネントも必要になる場合があります。 エキスパート システムは、金融取引、石油およびガス産業など、さまざまな分野で使用されています。 エキスパート システム技術は、エネルギー、輸送、製薬業界、宇宙開発、冶金および鉱業、化学、その他多くの分野にも適用できます。 2. エキスパートシステムの構造 エキスパート システムの開発には、従来のソフトウェア製品の開発とは大きく異なる点がいくつかあります。 エキスパート システムを作成した経験から、従来のプログラミングで採用されている方法論を開発に使用すると、エキスパート システムの作成にかかる時間が大幅に増加するか、マイナスの結果につながることさえあります。 エキスパートシステムは、一般的に次のように分類されます。 静的 и 動的. まず、静的エキスパート システムを考えます。 標準 静的エキスパート システム 次の主要コンポーネントで構成されています。 1) データベースとも呼ばれる作業記憶。 2) 知識ベース。 3) インタープリターとも呼ばれるソルバー。 4) 知識獲得の構成要素。 5) 説明要素 6) ダイアログ コンポーネント。 それでは、各コンポーネントをより詳細に検討してみましょう。 ワーキングメモリ (作業、つまりコンピューターの RAM との絶対的な類推によって) は、現時点で解決されているタスクの初期データと中間データを受け取り、保存するように設計されています。 Базазнаний 特定のサブジェクト領域を記述する長期データと、解決される問題のこの領域におけるデータの合理的な変換を記述するルールを格納するように設計されています。 ソルバーとも呼ばれている 通訳者、次のように機能します。作業記憶からの初期データと知識ベースからの長期データを使用して、ルールを形成し、その初期データへの適用が問題の解決につながります。 一言で言えば、彼は目の前にある問題を本当に「解決」します。 知識獲得コンポーネント エキスパート システムに専門家の知識を入力するプロセスを自動化します。つまり、この特定の分野から必要なすべての情報を知識ベースに提供するのは、このコンポーネントです。 コンポーネントの説明 システムがこの問題の解決策をどのように取得したか、またはこの解決策を取得しなかった理由、およびその際に使用した知識について説明します。 つまり、Explain コンポーネントは進捗レポートを生成します。 このコンポーネントは、エキスパートによるシステムのテストを大幅に容易にし、得られた結果に対するユーザーの信頼を高め、開発プロセスをスピードアップするため、エキスパートシステム全体で非常に重要です。 ダイアログ コンポーネント 問題を解決する過程と、知識を獲得して作業の結果を宣言する過程の両方で、使いやすいユーザー インターフェイスを提供するのに役立ちます。 統計エキスパート システムが一般的に構成されているコンポーネントがわかったので、そのようなエキスパート システムの構造を反映する図を作成しましょう。 次のようになります。
静的エキスパート システムは、問題の解決中に発生する環境の変化を考慮しない可能性がある技術アプリケーションで最もよく使用されます。 実用化された最初のエキスパート システムが正確に静的であったことは興味深いことです。 というわけで、これで統計エキスパートシステムの考察はひとまず終了し、動的エキスパートシステムの分析に移りましょう。 残念ながら、私たちのコースのプログラムには、このエキスパート システムの詳細な考察が含まれていないため、動的エキスパート システムと静的エキスパート システムの最も基本的な違いのみを分析することに限定します。 静的なエキスパート システムとは異なり、構造は ダイナミックエキスパートシステム さらに、次の XNUMX つのコンポーネントが導入されています。 1) 外界をモデル化するためのサブシステム。 2) 外部環境との関係のサブシステム。 外部環境との関係のサブシステム それは外の世界とのつながりを作るだけです。 彼女は、特別なセンサーとコントローラーのシステムを通じてこれを行います。 さらに、静的エキスパート システムの一部の従来のコンポーネントは、環境内で現在発生しているイベントの時間的論理を反映するために大幅な変更を受けます。 これが、静的エキスパート システムと動的エキスパート システムの主な違いです。 ダイナミック エキスパート システムの例として、製薬業界におけるさまざまな医薬品の製造管理があります。 3. エキスパートシステムの開発参加者 さまざまな専門分野の代表者がエキスパート システムの開発に携わっています。 ほとんどの場合、特定のエキスパート システムは XNUMX 人の専門家によって開発されます。 これは通常、次のとおりです。 1) 専門家; 2) ナレッジエンジニア; 3) ツール開発のためのプログラマー。 ここに記載されている各専門家の責任について説明しましょう。 専門家 この分野の専門家であり、そのタスクは、開発中のこの特定のエキスパート システムの助けを借りて解決されます。 知識エンジニア 直接エキスパートシステムの開発のスペシャリストです。 彼が使用する技術と方法は、知識工学技術と方法と呼ばれます。 ナレッジ エンジニアは、専門家がサブジェクト領域のすべての情報から、開発中の特定のエキスパート システムを操作するために必要な情報を特定し、それを構造化するのに役立ちます。 開発の参加者にナレッジ エンジニアがいない、つまりプログラマーに置き換えられていると、特定のエキスパート システムを作成するプロジェクト全体が失敗するか、開発時間が大幅に増加することは興味深いことです。 そして最後に、 プログラマ エキスパート システムの開発を加速するように設計されたツールを開発します (ツールが新しく開発された場合)。 これらのツールには、エキスパート システムの主要なコンポーネントがすべて含まれています。 プログラマーはまた、自分のツールを、それが使用される環境とインターフェースします。 4. エキスパート システムの動作モード エキスパート システムは、次の XNUMX つの主なモードで動作します。 1) 知識を獲得するモードで。 2) 問題を解決するモード (相談モード、またはエキスパート システムを使用するモードとも呼ばれます)。 これは論理的で理解できます。なぜなら、最初に、いわば、エキスパート システムが動作しなければならないサブジェクト エリアからの情報をエキスパート システムにロードする必要があるからです。これは、エキスパート システムの「トレーニング」モードです。知識を受けます。 そして、作業に必要なすべての情報をロードした後、作業自体が続きます。 エキスパートシステムの運用準備が整い、相談や問題解決に利用できるようになりました。 詳しく考えてみましょう 知識獲得モード. 知識獲得モードでは、エキスパートシステムでの作業は、知識技術者を介して専門家によって行われる。 このモードでは、エキスパートがナレッジ取得コンポーネントを使用してシステムにナレッジ (データ) を入力します。これにより、システムは、エキスパートの参加なしにソリューション モードでこのサブジェクト領域の問題を解決できます。 プログラム開発への従来のアプローチにおける知識獲得モードは、プログラマーによって直接実行されるアルゴリズム化、プログラミング、およびデバッグの段階に対応することに注意してください。 従来のアプローチとは対照的に、エキスパートシステムの場合、プログラムの開発はプログラマーではなく、もちろんエキスパートシステムの助けを借りてエキスパートによって実行されます。 、プログラミングを知らない人。 それでは、エキスパート システムの機能の XNUMX 番目のモードを考えてみましょう。 問題解決モード. 問題解決モード (またはいわゆる相談モード) では、エキスパート システムとの通信は、作業の最終結果と、場合によってはそれを取得する方法に関心のあるエンド ユーザーによって直接行われます。 エキスパート システムの目的によっては、ユーザーがこの問題領域の専門家である必要はないことに注意してください。 この場合、彼は結果を得るための十分な知識を持っていないため、結果を得るためにエキスパート システムに頼ります。 または、ユーザーは、自分で目的の結果を達成するのに十分なレベルの知識をまだ持っている場合があります。 この場合、ユーザーは自分で結果を取得できますが、結果を取得するプロセスを高速化するか、単調な作業をエキスパート システムに割り当てるために、エキスパート システムを使用します。 相談モードでは、ユーザーのタスクに関するデータは、ダイアログ コンポーネントによって処理された後、ワーキング メモリに入ります。 ソルバーは、作業メモリからの入力データ、問題領域に関する一般的なデータ、およびデータベースからのルールに基づいて、問題の解を生成します。 問題を解決するとき、エキスパート システムは特定の操作の所定のシーケンスを実行するだけでなく、事前にそれを形成します。 これは、システムの反応がユーザーにとって完全に明確でない場合に行われます。 この状況では、ユーザーは、このまたはそのエキスパート システムがこのまたはその質問をする理由、またはこのエキスパート システムがこの操作を実行できない理由、このエキスパート システムによって提供されるこのまたはその結果がどのように取得されるかについての説明を必要とする場合があります。 5. 知識の生産モデル その中核に、 知識の生産モデル 論理モデルに近いため、論理データ推論のための非常に効果的な手順を編成できます。 これは一方でです。 しかし一方で、論理モデルと比較して知識の生産モデルを考えると、前者の方が知識をより明確に示していることは議論の余地のない利点です。 したがって、間違いなく、知識の生産モデルは、人工知能システムで知識を表現する主要な手段の XNUMX つです。 それでは、知識の生産モデルの概念の詳細な検討を始めましょう。 従来の知識の生産モデルには、次の基本コンポーネントが含まれます。 1) 生産システムの知識ベースを表す一連の規則 (または生産物)。 2) 元の事実、および推論メカニズムを使用して元の事実から導き出された事実を格納するワーキング メモリ。 3) 利用可能な事実から、既存の推論規則に従って、新しい事実を導き出すことを可能にする論理的推論メカニズム自体。 そして、興味深いことに、そのような操作の数は無限になる可能性があります。 生産システムのナレッジ ベースを表す各ルールには、条件部分と最終部分が含まれます。 ルールの条件部分には、単一の事実、または接続詞で接続された複数の事実が含まれます。 ルールの最後の部分には、ルールの条件部分が true の場合に作業メモリを補充する必要があるファクトが含まれています。 知識の生産モデルを模式的に描写しようとすると、生産は次の形式の表現として理解されます。 (i) Q; P; A→B; N; ここで、i はナレッジ生産モデルの名前またはそのシリアル番号であり、この生産を生産モデルのセット全体から区別して、ある種の識別を受け取ります。 この製品の本質を反映する語彙単位は、名前として機能できます。 実際、リストから目的の製品を簡単に検索できるように、意識的に認識しやすいように製品に名前を付けています。 簡単な例を見てみましょう: ノートを購入する」または「色鉛筆のセットを購入する. 明らかに、各製品は通常、その瞬間に適した言葉で言及されています。 つまり、スペードをスペードと呼びます。 進む。 Q 要素は、この特定の知識生産モデルの範囲を特徴付けます。 そのような領域は人間の心の中で簡単に区別できるため、原則として、この要素の定義に問題はありません。 例を見てみましょう。 次の状況を考えてみましょう:私たちの意識のある領域では、食べ物を調理する方法の知識が保存され、別の領域では仕事に就く方法、XNUMX番目の領域では洗濯機を適切に操作する方法が保存されているとしましょう。 同様の分割は、知識の生産モデルの記憶にも存在します。 このように知識を別々の領域に分割することで、現時点で必要な知識の特定の生産モデルの検索に費やす時間を大幅に節約でき、それによってそれらを扱うプロセスが大幅に簡素化されます。 もちろん、生産の主な要素はいわゆるコアであり、上記の式では A → B と示されています。この式は、「条件 A が満たされている場合、アクション B を実行する必要がある」と解釈できます。 より複雑なカーネル構造を扱っている場合は、右側で次の代替選択が許可されます。「条件 A が満たされている場合、アクション B を実行する必要があります。1、それ以外の場合はアクション B を実行する必要があります2". ただし、知識の生産モデルのコアの解釈は異なる可能性があり、一連の記号「→」の左右に何があるかによって異なります。 知識の生産モデルのコアの解釈の XNUMX つを使用すると、シークエントは通常の論理的な意味で解釈できます。つまり、真の条件 A からのアクション B の論理的結果の兆候として解釈できます。 とはいえ、知識生産モデルの核心については別の解釈も可能です。 したがって、たとえば、A は、アクション B を実行するために必要な条件を記述することができます。 次に、知識 R の生産モデルの要素を考えます。 要素 Р 製品コアの適用条件として定義されています。 条件 P が真の場合、製品コアがアクティブ化されます。 そうではなく、条件 P が満たされない場合、つまり false の場合、コアはアクティブ化できません。 わかりやすい例として、次の知識生産モデルを考えてみましょう。 「お金の利用可能性」; 「物Aを買いたいのなら、その代金をレジ係に支払い、売り手に小切手を提示する必要があります。」 条件 P が真の場合、つまり、購入が支払われ、小切手が提示された場合、コアがアクティブ化されます。 購入完了。 この知識の生産モデルにおいてコアの適用条件が偽である場合、つまりお金がなければ、知識生産モデルのコアを適用することは不可能であり、活性化されません。 そして最後に要素に行きます N. 要素 N は、本番データ モデルの事後条件と呼ばれます。 事後条件は、製品コアの実装後に実行する必要があるアクションと手順を定義します。 より良い認識のために、簡単な例を挙げましょう。店舗で物を購入した後、この店舗の商品の在庫でこのタイプの物の数をXNUMXつ減らす必要があります。つまり、購入が行われた場合(したがって、コアが販売されている場合)、ストアにはこの特定の製品のユニットが XNUMX つ少なくなります。 したがって、事後条件「購入したアイテムの単位を取り消します」。 要約すると、一連のルールとしての知識の表現、つまり知識の生産モデルを使用することには、次の利点があると言えます。 1) 個々のルールの作成と理解が容易であること。 2) 論理的選択メカニズムの単純さです。 しかし、一連のルールの形で知識を表現することには、生産知識モデルの適用範囲と頻度を依然として制限する欠点もあります。 このような主な欠点は、特定の知識生産モデルを構成する規則と論理的選択の規則との間の相互関係のあいまいさです。 注釈 1. 本の印刷版の下線付きフォントは、 ボールドイタリック 本のこの(電子)バージョンで。 (約 e. ed.)
タッチエミュレーション用人工皮革
15.04.2024 Petgugu グローバル猫砂
15.04.2024 思いやりのある男性の魅力
14.04.2024
▪ 記事 なぜ猫や他の動物は赤ちゃんを歯に歯を当てて運ぶのでしょうか? 詳細な回答 ▪ 記事 ポンプの自動停止。 無線エレクトロニクスと電気工学の百科事典 ▪ 記事 XNUMX レベルのネオン信号装置。 無線エレクトロニクスと電気工学の百科事典
ホームページ | 図書館 | 物品 | サイトマップ | サイトレビュー
www.diagram.com.ua |



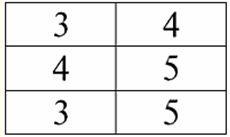

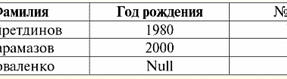

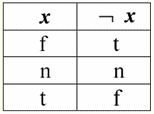

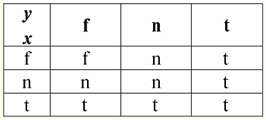
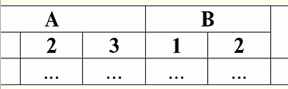


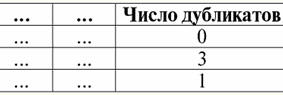
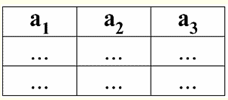






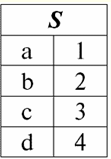
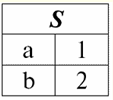

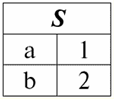

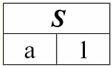
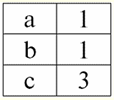
















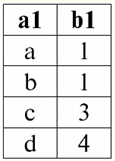



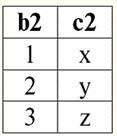

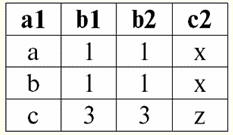
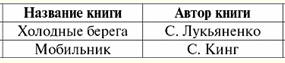




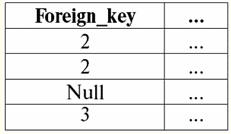
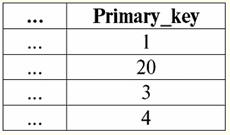

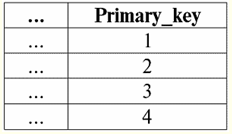

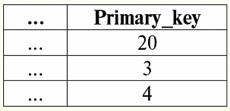
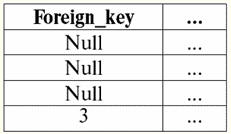

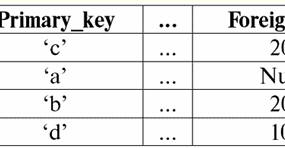











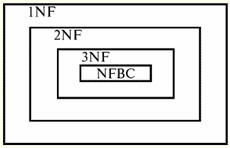

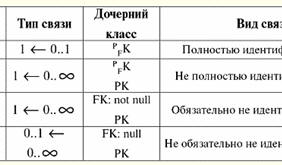










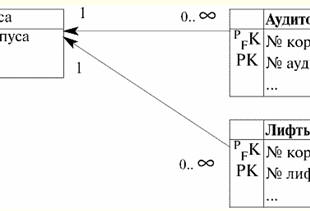




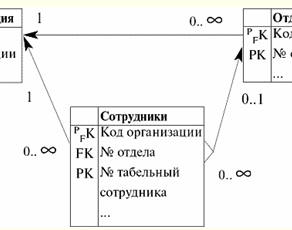
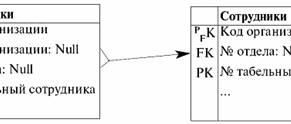
 他の記事も見る セクション
他の記事も見る セクション 