|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
統計の一般理論。 講義の要約:簡単に、最も重要なこと
目次
LECTURE No. 1. 科学としての統計 1. 社会科学としての統計学の主題と方法 統計 -社会生活のニーズから生まれた独自の主題と研究方法を持つ独立した社会科学。 統計 すべての社会経済現象の量的側面を研究する科学です。 「統計」という用語は、「位置、秩序」を意味するラテン語の「ステータス」に由来します。 ドイツの科学者 G. Achenwal (1719-1772) によって初めて使用されました。 統計の主なタスクは、収集された情報を数学的に正しく説明することです。 統計は、人間の生活の側面を説明する数学の特別なセクションと呼ぶことができます。 統計では、特定の問題を分析できるように、さまざまな数学的方法と技法が使用されます。 統計は、それを正しく使用する方法を知っていれば、あらゆる企業のあらゆるリーダーに貴重な支援を提供できます。 今日まで、「統計」という用語は次の XNUMX つの意味で使用されています。 1)国、その地域、経済または企業の個々のセクターの社会経済的発展を特徴付けるデータを収集、処理、および分析することを目的とした人々の実際的な活動の特別な部門。 2) 統計の実践で使用される理論的規定と方法を開発する科学。 3)統計-企業、経済部門のレポートに表示される統計データ、およびコレクション、さまざまなディレクトリ、掲示板などに公開されているデータ。 統計オブジェクト - 人々の社会経済的関係が表示され、その表現を見つける、社会の社会経済生活の現象とプロセス。 統計の一般理論は方法論の基礎であり、すべての部門別統計の中核です。 社会現象の統計的研究のための一般的な原則と方法を開発し、統計の最も一般的なカテゴリです。 経済統計のタスクは、国民経済の状態、産業の関係、生産力の分布の特殊性、材料、労働力、および財源の利用可能性を反映する総合指標の開発と分析です。 社会統計は、人口の生活様式と社会関係のさまざまな側面を特徴付ける指標のシステムを開発します。 統計 - 異なる性質の情報の収集、その順序付け、比較、分析、および解釈(説明)に従事する社会科学。 次の特徴があります。 1)社会現象の量的側面を研究する。 現象のこちら側は、その大きさ、サイズ、体積を表し、数値的な次元を持っています。 2) 質量現象の質的側面を探求します。 現象の提供された側面は、その特異性、つまり他の現象と区別する内部の特徴を表現します。 現象の質的側面と量的側面は常に一緒に存在し、XNUMX つの全体を形成します。 すべての社会現象と出来事は時間と空間で起こり、それらのいずれかに関連して、それがいつ発生し、どこで発生したかを常に判断することができます。 したがって、統計は場所と時間の特定の条件で現象を研究します。 統計によって理解される社会生活の現象とプロセスは、絶えず変化し発展しています。 研究された現象とプロセスの変化に関する質量データの収集、処理、分析に基づいて、統計的規則性が明らかになります。 統計的規則性は、社会における社会経済関係の存在と発展を決定する社会法の行動を明らかにします。 統計学の主題 社会現象、その発展のダイナミクスと方向性の研究です。 統計指標の助けを借りて、統計は社会現象の定量的側面を確立し、特定の社会現象の例を使用して量から質への移行のパターンを観察します。 提供された観察に基づいて、統計は場所と時間の特定の条件で取得されたデータを分析します。 統計は、大規模な性質の社会経済現象とプロセスの研究に従事しており、それらを決定する多くの要因も研究しています。 彼らの理論的法則を導き出し、確認するために、ほとんどの社会科学は統計を使用しています。 統計研究で形成された結論は、経済学、歴史、社会学、政治学、および他の多くの人文科学によって使用されます。 社会科学が理論的根拠を確認するためにも統計が必要であり、その実践的役割は非常に大きい。 大企業も真面目な産業も、オブジェクトの経済的および社会的発展のための戦略を開発するとき、統計データの分析なしでは実行できません。 この目的のために、特別な分析部門とサービスが企業と業界で組織され、この分野の専門的なトレーニングを完了した専門家を引き付けます。 統計は、他の科学と同様に、その主題を研究するための特定の方法があります。 統計の方法は、調査対象の現象と特定の調査対象 (関係、パターン、または発展) に応じて選択されます。 統計学の方法は、社会現象を研究するために開発され適用された特定の方法と技術から集合的に形成されます。 これらには、観察、データの要約とグループ化、特別な方法 (平均法、指数など) に基づく一般化指標の計算が含まれます。 これに関して、統計データの操作には XNUMX つの段階があります。 1) コレクションとは、研究対象の現象の個々の事実 (単位) に関する主要な情報が得られる、科学的に組織化された大量の観察です。 研究中の現象を構成するユニットの多数またはすべてのこの統計的説明は、研究中の現象またはプロセスに関する結論を導き出すための統計的一般化のための情報ベースです。 2) グループ化と要約。 これらのデータは、一連の事実 (単位) を同種のグループおよびサブグループに分散したもの、各グループおよびサブグループの最終カウント、および統計表の形式での結果の表示として理解されます。 3) 処理と分析。 統計分析は、統計研究の段階を終了します。 これには、要約中に得られた統計データの処理、調査中の現象の状態とその発生パターンに関する客観的な結論を得るために得られた結果の解釈が含まれます。 統計分析のプロセスでは、社会現象とプロセスの構造、ダイナミクス、および相互接続が研究されます。 統計分析の主な段階は次のとおりです。 1) 事実の主張とその評価の確立; 2) 現象の特徴と原因の特定。 3) 現象と、比較の基礎となる規範的、計画的、およびその他の現象との比較。 4) 結論、予測、仮定、および仮説の策定。 5) 提案された仮定 (仮説) の統計的検証。 2. 統計学の理論的基礎と基本概念 統計的方法論の場合、理論的基礎は、社会の発展の過程の法則の弁証法的唯物論的理解です。 その結果、統計では、量と質、必要性とチャンス、規則性、因果関係などのカテゴリが使用されることがよくあります。 統計の主な規定は、社会現象の発達のパターンを考慮し、社会の生活に対するそれらの重要性、原因、および結果を決定するため、社会経済理論の法則に基づいています。 一方、多くの社会科学の法則は、統計と統計分析によって特定されたパターンに基づいて作成されているため、統計と他の社会科学との関係は無限で継続的であると言えます。 統計は社会科学の法則を確立し、次にそれらは統計の規定を修正します。 定量的特性を測定、比較、分析するには、数学的指標、法則、および方法を使用する必要があるため、統計の理論的基礎は数学とも密接に関連しています。 現象のダイナミクス、時間の変化、および他の現象との関係を深く研究することは、高等数学と数学的分析を使用せずには不可能です。 多くの場合、統計的研究は、現象の開発された数学的モデルに基づいています。 このようなモデルは、理論的には研究中の現象の量的比率を反映しています。 利用可能な場合、統計のタスクは、モデルに含まれるパラメーターを数値的に決定することです。 企業の財政状態を評価する場合、A。Altmanのスコアリングモデルがよく使用されます。このモデルでは、破産レベルZは次の式を使用して計算されます。 Z=1,2x1 + 1,4x2 + 3,3x3 + 0,6x4 + 10,0x5, ここでx1 - 会社の資産額に対する逆資本の比率; x2 -資産額に対する未分配所得の比率。 x3 - 資産額に対する営業利益の比率; x4 - 負債総額に対する会社株式の市場価値の比率。 x5 - 資産額に対する売上額の比率。 A. アルトマンによれば、Z < 2,675 の場合、会社は倒産の危機に瀕しており、Z > 2,675 の場合、会社の財政状態は恐れを超えています。 この推定値を得るには、未知の x を式に代入する必要があります。1、X2、X3、X4 およびx5、バランス ラインの特定の指標です。 統計科学で特に広く普及しているのは、確率論や数理統計などの数学の分野です。 統計では、確率論の規則を使用して直接計算される演算が使用されます。 これは選択的な観察方法です。 これらの規則の主なものは、大数の法則を表す一連の定理です。 この法則の本質は、個人の特性が組み合わされるにつれて、その特性に関連するランダム性の要素が要約指標から消失することです。 数理統計学も確率論と密接に関係しています。 ここで考慮されるタスクは、分布 (セット構造)、接続 (機能間の)、ダイナミクス (時間の経過に伴う変化) の XNUMX つのカテゴリに分類できます。 変分系列の分析は広く使用されており、現象の発生の予測は外挿を使用して実行されます。 現象とプロセスの因果関係を、相関分析と回帰分析を使用して紹介します。 最後に、統計科学は、全体性、変動、符号、規則性などの最も重要なカテゴリと概念について、数学的統計の恩恵を受けています。 統計集計は統計の主要カテゴリに属し、統計研究の対象となります。これは、公共生活の社会経済現象に関する体系的な科学に基づいた情報の収集と、得られたデータの分析を意味します。 統計調査を行うためには、科学的に根拠のある情報基盤が必要です。 このような情報ベースは統計的な集合体であり、社会経済的対象または社会生活の現象の集合であり、共通のつながり、定性的基盤によって結合されていますが、特定の特性(たとえば、世帯、家族の集合など)において互いに異なります。 、企業など)。 統計的方法論の観点から、統計母集団は、均一性、質量特性、特定の完全性、変動の存在、および個々のユニットの状態の相互依存性などの特性を持つユニットのセットです。 したがって、統計母集団は個々の単位で構成されます。 物、人、事実、プロセスは全体の単位になり得る。 人口の単位は、主要な要素であり、その主な機能のキャリアです。 統計調査に必要なデータが収集される母集団の要素は、観測単位と呼ばれます。 人口のユニットの数は、人口のサイズと呼ばれます。 統計集計は、国勢調査中の人口、企業、都市、会社の従業員である可能性があります。 統計母集団とその単位の選択は、研究対象の社会経済現象またはプロセスの特定の条件と性質に依存します。 人口の単位の質量の性質は、その完全性と密接に関連しています。 完全性は、調査中の統計母集団の単位をカバーすることによって保証されます。 たとえば、研究者は銀行の発展について結論を出さなければなりません。 したがって、彼はその地域で営業しているすべての銀行に関する情報を収集する必要があります。 どのセットもかなり複雑な性質を持っているため、完全性とは、研究対象の現象を確実かつ本質的に説明する、セットの最も多様な機能のセットのカバレッジとして理解する必要があります。 たとえば、銀行を監視するプロセスで財務結果が考慮されない場合、銀行システムの発展について最終的な結論を出すことは不可能です。 さらに、完全性は、可能な限り長い期間の人口単位の特性の研究を示唆しています。 かなり完全なデータは、原則として、膨大で網羅的です。 実際に研究されている社会経済現象は非常に多様であるため、すべての現象を網羅することは困難であり、時には不可能ですらあります。 研究者は、統計母集団の一部のみを調査し、母集団全体について結論を導き出すことを余儀なくされています。 このような状況では、最も重要な要件は、特性を調査する母集団のその部分を合理的に選択することです。 この部分は、主な特性、現象を表示し、典型的なものでなければなりません。 実際には、調査中の現象やプロセスでは、複数の集合体が同時に相互作用する可能性があります。 このような状況では、研究対象は、研究対象集団を明確に区別するような方法で見つけられます。 集合体の単位の記号は、その特徴的な機能、特定のプロパティ、機能、観察および測定できる品質です。 時間または空間で調査された人口は、比較可能でなければなりません。 その結果、それらの比較可能性と均一性の要件が人口単位の特性に課せられます。 このためには、たとえば、均一なコスト見積もりを使用する必要があります。 全体を定性的に調査するために、最も重要な、または相互に関連する機能が調査されます。 人口単位を特徴付けるフィーチャの数が過剰であってはなりません。 これにより、データの収集と結果の処理が複雑になります。 統計母集団の単位の特性は、相互に補完し、相互依存性を持つように組み合わせる必要があります。 統計母集団の均一性の要件は、調査中の母集団に属する単位がどれかに従って基準を選択することを意味します。 たとえば、若い有権者の主導権を検討する場合、そのような有権者に年齢制限を設けて、古い世代の人々を除外する必要があります。 このような人口を、農村地域の代表者や学生などに限定することができます。 母集団の単位にばらつきがあるということは、それらの属性が母集団の一部の単位であらゆる種類の値または変更を受け取ることができることを意味します。 この点で、そのような兆候は変動と呼ばれ、個々の値または変更はバリアントと呼ばれます。 記号は、属性と量に分けられます。 記号は、たとえば人の性別や特定の社会集団への所属などの意味概念によって表現される場合、属性的または質的と呼ばれます。 内部的には、それらは名義と序数に分けられます。 属性が数値で表される場合、属性は量的と呼ばれます。 変動の性質に応じて、量的兆候は離散的および連続的に分けられます。 個別の特徴の例は、家族の人数です。 整数の形式では、原則として、個別の機能のバリアントが表現されます。 継続的特徴には、年齢、給与、勤続年数などがあります。 測定方法によると、兆候は一次(計算)と二次(計算)に分けられます。 一次 (説明) は、母集団全体の単位、つまり絶対値を表します。 二次 (計算) は直接測定されるのではなく、計算 (コスト、生産性) されます。 一次特徴は統計母集団の観察の基礎となるものであり、二次特徴はデータの処理と分析の過程で決定され、一次特徴の比率を表します。 特徴付けられた対象に関連して、記号は直接的なものと間接的なものに分けられます。 直接属性は、特徴付けられるオブジェクトに直接固有のプロパティ (生産量、人の年齢) です。 間接属性は、オブジェクト自体の特徴ではなく、オブジェクトに関連する、またはオブジェクトに含まれる他の集合体の特徴であるプロパティです。 時間に関しては、瞬時符号と間隔符号が区別されます。 瞬間的な兆候は、統計調査の計画によって確立された、ある時点で調査中のオブジェクトを特徴付けます。 インターバル記号は、プロセスの結果を特徴付けます。 それらの値は、時間間隔でのみ発生します。 兆候に加えて、調査中のオブジェクトまたは統計母集団の状態は、指標によって特徴付けられます。 指標 - 社会経済的プロセスと現象の一般化された定量的評価である、統計の主要な概念の XNUMX つ。 統計指標は、対象とする機能に応じて、会計と評価と分析に分けられます。 会計と推定指標 -これは、確立された場所と時間の条件における社会経済現象の大きさの統計的特徴です。つまり、それらは空間内の分布の量または特定の時間に到達したレベルを反映しています。 分析指標は、調査された統計母集団のデータを分析し、調査された現象の発展の詳細を特徴付けるために使用されます。 統計の分析指標として、相対値、平均値、変動とダイナミクスの指標、コミュニケーションの指標が使用されます。 現象間に存在する関係を反映する統計指標の全体が、統計指標のシステムを形成します。 一般に、指標と記号は統計母集団を完全に特徴付け、包括的に説明し、研究者が人間社会の現象と生活のプロセスを完全に研究することを可能にします。これは統計科学の目標の XNUMX つです。 統計の中心的なカテゴリは、統計的規則性です。 規則性は一般に、現象間の検出可能な因果関係、現象を特徴付ける個々の特徴の順序と繰り返しとして理解されています。 統計では、規則性は、客観的な法則の作用の結果としての質量現象と社会生活のプロセスの空間と時間の変化の定量的な規則性として理解されています。 したがって、統計的規則性は、母集団の個々の単位ではなく、母集団全体の特徴であり、十分に多数の観測値でのみ表現されます。 したがって、統計的規則性は、ある方向または別の方向の標識の値の個々の偏差を相互に相殺する平均的、社会的、大規模な規則性として現れます。 したがって、統計的規則性の現れは、現象の全体像を提示し、ランダムな個々の偏差を除いて、その発展の傾向を研究する機会を与えてくれます。 3。 ロシア連邦における現代の統計組織 統計は、国の経済的および社会的発展を管理する上で重要な役割を果たします。これは、管理上の結論の正確性が、その根拠となる情報に大きく依存するためです。 高レベルの管理では、正確で信頼性が高く、正しく分析されたデータのみを考慮に入れる必要があります。 国、個々の地域、産業、企業、企業の経済的および社会的発展の研究は、統計サービスを構成する特別に形成された組織によって実施されます。 ロシア連邦では、統計サービスの機能は、部門統計機関と州統計機関によって実行されます。 統計の最高統治機関は、ロシア連邦の国家統計委員会です。 ロシアの統計が現在直面している主なタスクを解決し、会計の全体的な方法論的基礎を提供し、受け取った情報を統合および分析し、データを要約し、その活動の結果を公開します。 ロシア連邦統計国家委員会 (ロシアの Goskomstat) は、6 年 1999 月 1600 日のロシア連邦大統領令第 XNUMX 号「ロシア統計局の国家委員会への移行について」に従って設立されました。統計に関するロシア連邦」。 ロシア連邦の国家統計委員会は、国家統計の分野における部門間の調整と機能的規制を担当する連邦執行機関です。 ロシア連邦統計委員会は、次の機能を果たします。 1)統計情報の収集、処理、保護、保管、国家および企業秘密の遵守、データの必要な機密性を実行します。 2)全ロシアの分類子に基づいて、ロシア連邦の領土内のすべての経済主体を識別コードの割り当てとともに会計処理することに基づいて、企業および組織の統一国家登録簿(EGRPO)の機能を保証します。技術的、経済的、社会的情報; 3) 現段階の社会のニーズと国際基準を満たす、科学に基づく統計手法を開発する。 4) すべての法人およびその他の経済主体が、ロシア連邦の法律、ロシア連邦大統領の決定、統計に関するロシア連邦政府の決定を遵守していることを確認する。 5)ロシア連邦の領土にあるすべての法的およびその他の経済主体を拘束する統計的問題に関する解決策および指示を発行します。 ロシアの国家統計委員会によって採用された統計指標の一連の方法、統計データの収集および処理の方法と形式は、ロシア連邦の公式統計基準です。 ロシアのゴスコムスタットは、その主な活動において、連邦行政機関および立法機関、ロシア連邦の構成機関の州当局、科学およびその他の組織の提案を考慮して形成され、承認された連邦統計プログラムによって導かれています。ロシア連邦政府と合意したロシアのゴスコムスタット。 国の統計機関の主な任務は、一般的な(個人ではなく)情報の公開とアクセシビリティを確保すること、および考慮されたデータの信頼性、真実性、正確性を保証することです。 さらに、ロシア国家統計委員会の任務は次のとおりです。 1) ロシア連邦大統領、ロシア連邦連邦議会、ロシア連邦政府、連邦行政当局、公衆、および国際機関への公式統計情報の提出。 2) 現段階の社会のニーズと国際基準を満たす、科学的に証明された統計手法の開発。 3) 連邦行政当局とロシア連邦の構成組織の行政当局の統計活動の調整、これらの当局が部門別 (部門別) の統計観測を行う際の公的統計基準の適用条件の提供。 4)経済および統計情報の開発と分析、必要なバランス計算と国民経済計算の準備。 5) 完全で科学に基づく統計情報を保証する。 6) ロシア連邦の社会経済状況、ロシア連邦の構成団体、経済の産業およびセクターに関する公式報告書を配布し、統計コレクションおよびその他の統計資料を公開することにより、公開統計情報への平等なアクセスをすべてのユーザーに提供する。 ロシア連邦の経済改革の結果、統計機関の構造も変化した。 地方の地区統計登録簿は廃止され、領土統計機関の代表事務所である地区間統計部門が設立されました。 ロシアの統計機関の組織は現在、改革の段階にある。 前述のように、現在、ロシアの統計科学はいくつかの変化を遂げています。 改革が必要な主な分野は次のとおりです。 1)個々の指標(企業秘密)の機密性を維持しながら、統計会計の基本法、つまり情報の公開と入手可能性を遵守する必要があります。 2)統計の方法論的および組織的基盤を改革する必要があります。経済管理の一般的なタスクと原則の変更は、科学の理論的規定の変更につながります。 3) 市場統計への移行により、資格、登録簿(登録簿)、国勢調査などの形態の観察を導入することにより、情報を収集および処理するためのシステムを改善する必要性が生じます。 4)ロシア連邦の経済状態を特徴付けるいくつかの統計指標を計算するための方法論を変更(改善)する必要があり、国際基準、統計会計における外国の経験を考慮に入れて、すべての指標を体系化する必要があります。国民経済計算体系(SNA)を考慮に入れて、当時の問題と要件に対応する順序でそれらを配置します。 5) 国の公共生活の発展レベルを特徴付ける統計指標の関係を確保する必要がある。 6) 情報化の傾向を考慮に入れる必要がある。 統計科学を改革する過程で、統一された情報ベース(システム)を作成する必要があります。これには、国家統計組織の階層的なはしごの下位レベルにあるすべての統計機関の情報ベースが含まれます。 このように、ロシアでは、国の公共生活のあらゆる分野に影響を与える構造的な変化がまだ起こっています。 統計はこれらの分野のほぼすべてに直接関係しているため、改革プロセスでも統計が省略されていません。 現在、統計機関の作業を整理するために多くの作業が行われていますが、まだ完了しておらず、州にとって非常に重要なこの情報機関の改善に多くの注意を払う必要があります。 州の統計サービスに加えて、経済のさまざまな部門の省庁、部門、企業、協会、および企業で維持されている部門別統計があります。 部門統計は、統計情報の収集、処理、および分析に従事しています。 この情報は、組織または当局の活動を計画するために、経営上の意思決定を行うために必要です。 中小企業では、この作業は通常、主任会計士によって、またはマネージャー自身によって直接行われます。 独自の地域構造を持ち、多数の従業員を抱える大企業では、部門全体または部門が統計情報の処理と分析に関与しています。 このような作業には、統計、数学、会計および経済分析、管理者、技術者の分野の専門家が関与します。 このようなチームは、統計理論によって提案された方法論に基づいて最新のコンピューター技術で武装し、最新の分析方法を使用して、効果的なビジネス開発戦略を構築し、公的機関の活動を効果的に形成するのに役立ちます。 完全で信頼できるタイムリーな統計情報がなければ、複雑な社会経済システムを管理することは不可能です。 このように、国家および部門の統計は、会計および統計システムの合理化に貢献し、実行コストを最小限に抑えるために、現代の経済発展の状況に対応する統計情報の量と構成を理論的に実証するという非常に重要な課題に直面しています。この機能。 講義2。統計的観察 1。 統計的観察の概念、その実施の段階 経済的または社会的プロセスの深い包括的な研究には、その量的な側面を測定し、社会関係の一般的なシステムにおける質的な本質、場所、役割、および関係を特徴付けることが含まれます。 社会生活の現象とプロセスを研究するために統計的手法を使い始める前に、研究の対象を完全かつ確実に説明する網羅的な情報ベースを自由に使えるようにする必要があります。 統計調査のプロセスには、次の手順が含まれます。 1) 統計に関する情報の収集(統計観測)とその一次処理 2) 統計的観察の結果として得られたデータの要約とグループ化に基づくグループ化とその後の処理。 3) 統計資料の処理結果の一般化と分析、統計研究全体の結果に基づく結論と推奨事項の策定。 したがって、統計的な観察が最初です。 そして統計調査の初期段階。 統計観測 - 社会的および経済的生活のさまざまな現象に関する一次データを収集するプロセス。 これは、統計的観測が計画的かつ大規模かつ体系的に組織化されるべきであることを意味します。 統計的観察の規則性は、統計情報を収集し、その信頼性と品質を監視し、最終的な資料を提示する組織と技術に関連する問題を含む特別に開発された計画に従って実行されるという事実にあります。 統計的観察の質量の性質は、調査中の現象またはプロセスの発現のすべてのケースの最も完全な範囲によって保証されます。つまり、量的および質的特性は、調査中の母集団の個々の単位ではなく、全体によって測定および記録されます。統計観測の過程における個体群の単位の質量。 統計的観察の体系的な性質は、自発的であってはなりません。 このような監視に関連する作業は、継続的または定期的に定期的に実行する必要があります。 統計的観測を準備するプロセスには、観測の目標と対象の設定、観測単位の選択、記録される特徴の構成が含まれます。 データを収集するには、文書のフォームを開発し、それらを取得するための手段と方法を選択する必要があります。 その結果、統計的観察は、資格のある担当者、その包括的な組織、計画、準備、および実装の関与を必要とする、骨の折れる骨の折れる作業です。 2。 統計的観察の種類と方法 統計的観察は、その組織の観点から、さまざまな方法、形態、および行動の種類を持つことができるプロセスです。 統計の一般理論のタスクは、観察の方法、形式、および種類の本質を決定して、いつ、どこで、どのような観察方法を適用するかを決定することです。 統計的観測には、XNUMXつの主要なグループがあります。 1) 人口単位の範囲; 2) 事実の登録時期。 調査対象集団のカバー率のレベルに応じて、統計的観測は連続型と非連続型の XNUMX つのタイプに分けられます。 継続的な (完全な) 観察とは、調査対象集団のすべての単位をカバーすることを指します。 継続的な観察は、研究された現象とプロセスに関する完全な情報を提供します。 この種の観測は、高い人件費と物的資源に関連しています。 必要な情報を全て収集・処理するには相当の時間を要し、運用情報のニーズが満たされない。 多くの場合、継続的な観察はまったく不可能です (たとえば、調査中の人口が大きすぎる場合、または人口のすべてのユニットに関する情報を取得する可能性がない場合)。 その結果、一貫性のない観察が行われます。 非連続的な観察の下では、調査された集団の特定の部分のカバレッジのみが理解されます。 非連続的な観察を行う場合、調査中の母集団のどの部分を観察するか、どの基準をサンプルの基礎として使用するかを事前に決定する必要があります。 非連続的な観測を組織化する利点は、短時間で実行され、人件費と材料費が最も低く、得られた情報が運用上の性質のものであることです。 不連続な観察にはいくつかのタイプがあります。 メインアレイの観察; モノグラフィック。 選択的観察は、無作為選択法によって選択された、調査対象の母集団の単位の一部として理解されます。 適切な構成により、サンプルの観察により、条件付き確率で母集団全体に拡張できるかなり正確な結果が得られます。 瞬間的な観察の方法は、選択的観察と呼ばれます。これには、調査中の人口の単位の選択(空間でのサンプリング)だけでなく、兆候の登録が実行される時点(時間でのサンプリング)も含まれます。 メインアレイの観察は、人口の単位の特定の最も重要な特徴の調査の範囲です。 このような観察により、人口の最大単位が考慮され、この研究の最も重要な特徴が記録されます。 たとえば、大規模な信用機関の15〜20%が調査され、投資ポートフォリオの内容が記録されます。 モノグラフ観察は、いくつかの特別な特徴を持っているか、いくつかの新しい現象を表す集団の一部の単位のみの包括的かつ完全な研究によって特徴付けられます。 このような観察の目的は、特定のプロセスまたは現象の開発における既存の傾向または新たな傾向のみを特定することです。 モノグラフ調査では、人口の個々の単位が詳細な調査の対象となります。これにより、他のあまり詳細でない観察では見つけることができない非常に重要な依存関係と比率に注意することができます。 統計モノグラフ調査は、医学、家計調査などでよく使用されます。モノグラフ調査は、継続的かつ選択的な調査と密接に関連していることに注意することが重要です。 第 XNUMX に、大量調査からのデータは、非連続的かつモノグラフ的な観察のための人口単位を選択するための基準を選択するために必要です。 第二に、モノグラフの観察により、研究対象の特徴と本質的な特徴を特定し、研究対象集団の構造を明らかにすることができます。 調査結果は、新しい大衆調査を組織するための基礎として使用できます。 事実の登録時期によって、観察は連続的または非連続的になり得る。 一方、不連続モニタリングには、定期的モニタリングと XNUMX 回限りモニタリングが含まれます。 継続的な(現在の)観測は、事実が入手可能になった時点で継続的に登録することによって実現されます。 このような観察により、研究中のプロセスと現象のすべての変化が追跡され、そのダイナミクスを監視することが可能になります。 たとえば、登記所は死亡、出生、婚姻を継続的に登録します。 企業は、倉庫、生産などからの材料のリリースの現在の記録を維持しています。 不連続観測は、一定間隔で計画的に行う(定期観測)か、必要に応じて不定期にXNUMX回行う(XNUMX回観測)かのいずれかです。 定期的な観測は通常、同様のプログラムとツールに基づいているため、そのような研究の結果を比較することができます。 定期的な観測の例としては、かなり長い間隔で実施される人口調査や、毎年、半年ごと、四半期ごと、毎月のあらゆる形式の統計観測があります。 2000回限りの観察の特異性は、事実がその発生に関連して記録されるのではなく、特定の瞬間または期間にわたる状態または存在に応じて記録されることです。 現象またはプロセスの兆候の定量的測定は調査時に発生し、兆候の再登録がまったく行われないか、その実施のタイミングが事前に決定されない場合があります。 XNUMX回限りの観測の例としては、XNUMX年に実施された住宅建設状況のXNUMX回限りの調査があります。 統計的観察の種類に加えて、統計の一般理論では、統計情報を取得する方法を検討します。その中で最も重要なのは、記録的な観察方法です。 直接観察の方法; インタビュー。 記録観察は、情報源として、会計帳簿などのさまざまな文書からのデータの使用に基づいています。 原則として、そのような文書への記入には高い要件が課せられることを考慮すると、それらに反映されたデータは最も信頼できる性質のものであり、分析のための高品質のソース資料として役立ちます。 直接観察は、調査中の現象の兆候を検査、測定、およびカウントした結果として、レジストラによって個人的に確立された事実を登録することによって実行されます。 このようにして、商品やサービスの価格が記録され、労働時間の測定が行われ、在庫残高の在庫などが作成されます。 調査は、回答者(調査参加者)からのデータ取得に基づいています。 他の方法で観測できない場合に使用します。 この種の観察は、さまざまな社会学的調査や世論調査を実施する場合に一般的です。 統計情報は、さまざまな種類の調査によって取得できます。 特派員; アンケート; プライベート。 遠征 (口頭) 調査は、特別な訓練を受けた作業員 (登録者) によって実施され、調査票に回答者の回答が記録されます。 フォームは、回答用のフィールドに入力する必要があるドキュメントのフォームです。 コレスポンデント法は、回答者のスタッフが自発的に監視機関に直接情報を報告することを前提としています。 この方法の欠点は、受信した情報の正確性を検証するのが難しいことです。 アンケート方式では、回答者はほとんど匿名で任意にアンケート(アンケート)に記入します。 この情報取得方法は信頼できないため、結果の高精度が必要とされない研究で使用されます。 場合によっては、傾向のみを捉え、新しい事実や現象の出現を記録するおおよその結果で十分です。 個人的な方法には、監視を行っている当局に直接情報を提出することが含まれます。 このようにして、結婚、離婚、死亡、出生などの民事上の行為が登録されます。 統計的観察の種類と方法に加えて、統計理論では統計的観察の形式も考慮されます。 特別に組織された統計観察; 登録します。 統計レポート - 統計当局が調査中の現象に関する情報を、特定の期間内に所定の形式で企業や組織によって提出された特別な文書の形式で受け取るという事実によって特徴付けられる、統計的観測の主な形式。 統計報告自体の形式、統計データの収集と処理の方法、ロシアの国家統計委員会によって確立された統計指標の方法論は、ロシア連邦の公式統計基準であり、広報のすべての主題に義務付けられています。 統計レポートは、特殊レポートと標準レポートに分けられます。 標準的な報告指標の構成は、すべての企業および組織で同じですが、専門的な報告指標の構成は、経済の個々のセクターおよび活動分野の詳細によって異なります。 提出のタイミングに応じて、統計レポートは、毎日、毎週、XNUMX日間、XNUMX週間、毎月、四半期ごと、半年ごと、および毎年です。 統計レポートは、電話、通信チャネル、電子メディアで送信でき、その後、責任者の署名によって証明された紙に提出することが義務付けられています。 特別に編成された統計観測は、統計当局によって編成された情報の集まりであり、報告でカバーされていない現象を研究するか、報告データをより深く研究し、それらを検証および改良します。 各種国勢調査、XNUMX回限りの調査は、特別に組織化された観測です。 レジスタ -これは、人口の個々の単位の状態の事実が継続的に記録される観察の一形態です。 人口の単位を観察すると、そこで行われているプロセスには始まり、長期的な継続、そして終わりがあると想定されます。 レジスタでは、観察の各単位は一連の指標によって特徴付けられます。 すべてのインジケータは、観測ユニットがレジスタに格納され、その存在が終了するまで保存されます。 いくつかの指標は、観測単位が登録されている限り同じままですが、他の指標は時々変化する可能性があります. そのような登録簿の例は、企業および組織の統一国家登録簿 (USRE) です。 その維持に関するすべての作業は、ロシアの国家統計委員会によって行われます。 したがって、統計的観察の種類、方法、形式の選択は、観察の目的と目的、観察対象の詳細、結果の提示の緊急性、訓練を受けた要員の利用可能性など、多くの要因に依存します。 、データを収集および処理する技術的手段を使用する可能性。 3。 統計的観察のプログラムと方法論の問題 統計観測を準備する際に解決しなければならない最も重要なタスクの XNUMX つは、観測の目的、目的、および単位の定義です。 ほとんどすべての統計的観察の目標は、要因の相互関係を特定し、現象の規模とその発展のパターンを評価するために、社会生活の現象とプロセスに関する信頼できる情報を取得することです。 観察のタスクから進んで、そのプログラムと組織の形態が決定されます。 目標に加えて、観察対象を確立する必要があります。つまり、正確に何を観察するかを決定する必要があります。 観察対象は、研究対象の社会現象またはプロセスの全体です。 観察対象は、一連の機関(信用、教育など)、人口、建物の物理的対象、輸送、設備などです。 観察対象を設定する際には、調査中の母集団の境界を厳密かつ正確に決定することが重要です。 そのためには、対象を集合体に含めるかどうかを決定する本質的な特徴を明確にする必要があります。 たとえば、最新の機器を提供するために医療機関の調査を行う前に、調査対象の診療所のカテゴリ、部門、および地域の所属を決定する必要があります。 観測対象を定義する際には、観測単位と個体群の単位を指定する必要があります。 観測単位は、情報源である観測対象の構成要素です。 統計的観察の特定のタスクに応じて、観察の単位は、家庭または学生、農業企業、工場などの個人になります。 人口単位 -これは、観察対象のいわゆる構成要素であり、そこから観察単位に関する情報が受信されます。つまり、カウントの基礎として機能し、観察の過程で登録の対象となる機能を備えています。 たとえば、植林地の国勢調査では、登録の対象となる特性(年齢、種の組成など)があるため、人口の単位は樹木になりますが、調査が行われる林業自体は、観測単位として機能します。 観測単位は、統計当局に統計レポートを提出する場合、報告単位と呼ばれます。 社会生活の各現象またはプロセスには、それらを特徴付ける多くの特徴があります。 すべての機能に関する情報を取得することは不可能であり、それらすべてが研究者にとって興味深いものであるとは限りません。 観測を準備する際には、観測の目的と目的に応じて、登録対象となる標識を決定する必要があります。 登録された特徴の構成を決定するために、観測プログラムが開発されます。 統計観察プログラムは一連の質問であり、観察プロセス中にその回答が統計情報を構成する必要があります。 観測プログラムの開発は非常に重要かつ責任ある作業であり、観測の成功はそれがいかに正確に実行されるかにかかっています。 観測プログラムを開発するときは、そのためのいくつかの要件を考慮に入れる必要があります。 主なものをリストアップしましょう。 1.プログラムには、可能であれば、必要な機能のみを含め、その値をさらなる分析または制御目的に使用する必要があります。 無害な資料の受領を保証する情報の完全性に努める一方で、分析のための少量ではあるが信頼できる資料を取得するために収集される情報の量を制限する必要があります。 2. プログラムの質問は、誤った解釈を排除し、収集される情報の意味の歪みを防ぐために、十分に明確に、非常に明確に定式化する必要があります。 3. 観察プログラムを開発するときは、質問の論理的な順序を構築することが望ましい。 現象のいずれかの側面を特徴付ける同じタイプまたは兆候の質問は、XNUMX つのセクションにまとめる必要があります。 4. 監視プログラムには、記録された情報を確認および修正するための管理質問が含まれていることが重要です。 観察を行うには、フォームと指示などの独自のツールが必要です。 統計フォーム ●番組の出題に対する回答を収録した、XNUMXサンプルの特製ドキュメントです。 実施される観察の具体的な内容に応じて、フォームは、統計報告のフォーム、国勢調査またはアンケート、マップ、カード、アンケートまたはフォームと呼ばれることがあります。 フォームには、カードとリストの XNUMX 種類があります。 カード形式 (または個別形式) は、統計母集団の XNUMX 単位に関する情報を反映することを目的としており、リスト形式には、母集団のいくつかの単位に関する情報が含まれています。 統計フォームの不可欠かつ必須の要素は、タイトル、アドレス、およびコンテンツの部分です。 タイトル部分には、統計観測の名前とこのフォームを承認した機関、フォームの送信条件、およびその他の情報が表示されます。 住所部分には、監視の報告単位の詳細が含まれます。 フォームのメインのコンテンツ部分は、通常、テーブルの形式で作成され、便利な形式でインジケーターの名前、コード、および値が含まれています。 統計フォームは、指示に従って記入されます。 説明書には、観察を実施するための手順に関する指示と、フォームに記入するための方法論的指示と説明が含まれています。 監視プログラムの複雑さに応じて、指示はパンフレットとして発行されるか、フォームの裏に掲載されます。 さらに、必要な説明のために、観察の実施を担当する専門家、それを実施する機関に連絡することができます。 統計観測を行う際には、観測の時期と実施場所の問題を解決する必要があります。 観測場所の選択は、観測の目的によって異なります。 観測時間の選択は、重要な瞬間(日付)または時間間隔の決定、および観測期間(期間)の決定に関連付けられています。 統計的観測の重要な瞬間は、観測の過程で記録された情報が計時される時点です。 観察期間は、調査中の現象に関する情報の登録を実行する期間、つまり、フォームに記入する時間間隔を決定します。 通常、観測期間は、その時点でのオブジェクトの状態を再現するために、観測の重要な瞬間から離れすぎないようにする必要があります。 4. 組織的支援、統計観測の作成と実施の問題 統計観測の準備と実施を成功させるためには、その組織的支援の問題も解決しなければなりません。 これは、組織の監視計画を作成するときに行われます。 計画には、観測の目標と目的、観測対象、観測の場所、時間、タイミング、観測を実施する責任者の輪が反映されます。 組織計画の必須要素は、監督当局の指示です。 また、監視を支援するために呼び出される組織のサークルも定義します。 これらには、総務機関、税務調査官、省庁、公的機関、個人、ボランティアなどが含まれる場合があります。 準備活動には以下が含まれます。 1) 統計観察の形式の開発、調査自体の文書の複製; 2)観察結果を分析および提示するための方法論的装置の開発。 3) データ処理用ソフトウェアの開発、コンピュータおよび事務機器の購入。 4) 文房具を含む必要な材料の購入。 5)有資格者の育成、人材育成、各種説明会の実施等 6) 住民と観測参加者の間で大規模な説明作業を実施する (講義、会話、マスコミでのスピーチ、ラジオやテレビでのスピーチ)。 7) 共同行動に関与するすべてのサービスおよび組織の活動の調整。 8) データの収集と処理の場所の設備。 9) 情報伝達チャネルと通信手段の準備。 10) 統計観測の資金調達に関連する問題の解決。 このように、観測計画には、必要な情報を登録する作業を成功裏に完了することを目的とした、いくつかの対策と、それらを特徴付ける場所と時間の状況が含まれています。 5。 観測精度とデータ検証方法 観察の過程で実行されるデータの大きさの特定の測定は、原則として、現象の大きさの近似値を示します。これは、この大きさの真の値とはある程度異なります。 統計観測の精度 観察資料に基づいて計算された指標または特徴の実際の値への適合度と呼ばれます。 観測結果と観測された現象の大きさの真の値との間の不一致は呼ばれます 観察ミス。 発生の性質、段階、および原因に応じて、いくつかのタイプの観測エラーが区別されます。 その性質上、エラーはランダムとシステマティックに分けられます。 ランダムなバグ -これらはエラーであり、その発生はランダムな要因の作用によるものです。 これには、面接対象者による予約や誤植が含まれます。 それらは、機能の値を増減するように指示できます。 原則として、観測結果の要約処理中に互いに打ち消し合うため、最終結果には反映されません。 体系的なエラー 属性インジケータの値を減少または増加させる同じ傾向があります。 これは、たとえば、測定が欠陥のある測定装置によって行われたか、エラーが観測プログラムの問題の不明確な定式化などの結果であるという事実によるものです。体系的なエラーは非常に危険です。観察結果。 発生の段階に応じて、次のようなものがあります。登録エラー。 機械処理用のデータの準備中に発生するエラー。 コンピューター技術での処理中に表示されるエラー。 К 登録エラー データを統計フォーム (一次文書、フォーム、レポート、国勢調査フォーム) に記録する際、またはコンピューターにデータを入力する際に発生する不正確さ、通信回線 (電話、電子メール) を介して送信される際のデータの歪みが含まれます。 多くの場合、フォームのフォームに準拠していないために登録エラーが発生します。つまり、ドキュメントの確立された行または列にエントリが作成されていません。 個々の指標の値の意図的な歪みもあります。 機械処理のためのデータの準備または処理自体のプロセスでのエラーは、コンピューター センターまたはデータ準備センターで発生します。 このようなエラーの発生は、フォームへのデータの不注意、不正確、あいまいな入力、データキャリアの物理的な欠陥、情報ベースのストレージ技術への準拠の欠如によるデータの一部の損失に関連しています。 ハードウェアの誤動作によってエラーが発生する場合があります。 観測エラーの種類と原因を知ることで、そのような情報の歪みの割合を大幅に減らすことができます。 エラーにはいくつかの種類があります。 1) 社会生活の現象およびプロセスの単一の統計的観察中に生じる特定のエラーに関連する測定エラー。 2) 非連続的な観察の過程で生じる代表性エラーであり、サンプル自体が代表的ではなく、それに基づいて得られた結果を母集団全体に拡張できないという事実に関連しています。 3) 観測対象の実際の状態を装飾したり、逆に対象の不十分な状態を示したりするなど、さまざまな目的でデータを故意に歪曲することから生じる意図的な誤り。情報の歪曲は法律違反です。 4)原則として、偶発的な性質の意図しないエラーであり、従業員の資格の低さ、不注意または過失に関連しています。 多くの場合、このようなエラーは主観的な要因に関連しています。つまり、人々が自分の年齢、婚姻状況、教育、社会集団のメンバーシップなどについて誤った情報を提供したり、単に事実を忘れたりして、記憶に浮かんだばかりの情報をレジストラに伝える場合です。 観測エラーを防止、特定、および修正するのに役立ついくつかの活動を実行することが望ましいです。 これらの活動には以下が含まれます。 1) サーベイランスの実施に関連する資格のある要員の選択および要員の質の高い訓練; 2) 継続的または選択的な方法による文書への記入の正確さの管理チェックの組織。 3) 観測資料収集終了後の受信データの演算・論理管理。 データ信頼性制御の主なタイプは、構文、論理、算術です。 1. 構文管理とは、ドキュメントの構造の正確さ、必要かつ必須の詳細の存在、確立された規則に従ってフォーム行への記入の完全性をチェックすることを意味します。 構文制御の重要性と必要性は、コンピューター技術、データ処理用スキャナーの使用によって説明されます。これは、フォームに記入するための規則への準拠に厳しい要件を課します。 2.論理制御は、コードの正確性、インジケーターの名前と値への対応をチェックします。 指標間の必要な関係がチェックされ、さまざまな質問への回答が比較され、互換性のない組み合わせが識別されます。 論理制御中に特定されたエラーを修正するために、元のドキュメントに戻って修正します。 3. 算術制御中、得られた合計は、事前に計算された行と列のチェックサムと比較されます。 多くの場合、算術制御は、XNUMX つの指標の XNUMX つ以上の他の指標への依存に基づいています (たとえば、他の指標の積です)。 最終指標の算術制御により、この依存性が観察されないことが明らかになった場合、これはデータの不正確さを示します。 このように、統計情報の信頼性の管理は、一次情報の収集から結果を得るまでの統計観察のあらゆる段階で行われます。 LECTURE No. 3. 統計の要約とグループ化 1. サマリー タスクとコンテンツ 統計観察資料をあらかじめ作成したプログラムに従って科学的に整理処理することにより、データ管理に加え、体系化、データのグループ化、表の作成、結果や導出指標(平均値、相対値)の取得などが行われます。統計的観察のプロセスでは、研究対象の現象の個々の単位に関する一次情報が分散されます。 この形式では、資料は現象全体をまだ特徴付けていません。現象のサイズ (数)、その構成、特徴のサイズ、または現象のサイズ (数) についてのアイデアは得られません。この現象と他の現象との関連性など。観察資料の要約である統計データには特別な処理が必要です。 まとめ 全体として研究中の現象に固有の典型的な特徴とパターンを検出するために、セットを形成する特定の単一データを一般化する一連の一連のアクションです。 統計概要 狭義の言葉で (簡単なまとめ) 一連の観測単位の総要約 (要約) データを計算する操作です。 統計概要 広い意味で (複雑な要約) また、観測データのグループ化、一般およびグループの合計の計算、相互に関連する指標のシステムの取得、グループ化の結果と要約の統計表の形式での提示も含まれます。 予備的な深い理論的分析に基づいた科学的に整理された正確な要約により、研究対象の最も重要で特徴的な特徴を反映するすべての統計結果を取得し、結果に対するさまざまな要因の影響を測定し、これらすべてを取得することができます現在および長期的な計画を作成する際に、実際の作業で考慮に入れます。 したがって、要約のタスクは、統計指標のシステムを使用して研究対象を特徴付け、このようにしてその本質的な特徴と特性を特定および測定することです。 このタスクは、次の XNUMX つの段階で解決されます。 1) グループとサブグループの定義; 2) 指標システムの定義; 3) テーブルのタイプの定義。 最初の段階では、観察中に収集された資料の体系化、グループ化が行われます。 第XNUMX段階では、計画によって提供される指標のシステムが指定され、それを使用して、研究中の主題の特性と特徴が定量的に特徴付けられます。 第 XNUMX 段階では、指標自体が計算され、一般化されたデータが表、統計系列、グラフ、および図に示され、わかりやすく便利になります。 要約のリストされた段階は、実装の開始前であっても、特別にコンパイルされたプログラムに反映されます。 統計要約プログラムには、母集団を分割することが推奨されるグループのリストと、グループ化の特性に応じた境界が含まれています。 全体性を特徴付ける指標のシステムとその計算方法。 計算結果が表示される開発テーブルのレイアウトのシステム。 プログラムに加えて、その組織を提供する要約計画があります。 要約を実施するための計画には、個々の部分の実装の順序とタイミング、実装の責任者、結果を提示する手順、および関係するすべての組織の作業の調整に関する指示を含める必要があります。その実装で。 2. 主な業務とグループの種類 統計研究の対象である社会生活の大量現象とプロセスには、数多くの特徴と特性があります。 データ処理の特定の科学原理がなければ、統計データを要約し、集団現象全体とその個々の構成要素の最も重要な特徴や発展形態を明らかにすることは不可能です。 統計的観測対象の個々の多様性を克服することなく、現象またはプロセス全体の発展の一般的なパターンは、各対象を互いに区別する細部や些細なことで失われ、究極の一般化は、現実。 ユニットのセットを同じタイプのグループに分けるために、統計はグループ化方法を使用します。 統計グループ - 統計的要約の第 XNUMX 段階。これにより、大量の初期統計資料から、定性的および定量的な点で一般的な類似性を持つ同種のユニットのグループを特定することができます。 グループ化は、母集団を部分に分割する主観的な技術的方法ではなく、特定の基準に従って母集団の多くの単位を分割する科学に基づいたプロセスであることを理解することが重要です。 グループ化手法を適用する基本原則は、調査中の現象の本質と性質を包括的かつ詳細に分析することです。これにより、その典型的な特性と内部の違いを判断できます。 一般的なセットは、特定のセットの複合体であり、それぞれが特定の点で同じ品質の特殊なタイプの現象を組み合わせています。 各タイプ(グループ)には、対応するレベルの定量値を持つ特定の機能システムがあります。 おそらくグループ化を実行する必要のある重要な機能の正確で明確な定義に基づいて、一般集団のグループ化された単位をどのタイプ、どの特定の集団に帰属させるべきかを決定すること。 これは、科学に基づいたグループ化のXNUMX番目の重要な要件です。 XNUMX番目のグループ化要件は、形成されたグループが母集団の同種の要素を統合する必要があり、グループ自体(一方が他方に対して)が大幅に異なる必要がある場合、グループの境界の客観的で合理的な確立に基づいています。 そうでなければ、グループ化は無意味です。 このように、グループ化方法の適用に基づいて、グループは母集団単位の類似性と相違性の原則に従って決定されます。 類似性とは、特定の制限内の単位 (グループ) の均一性です。 違いは、グループ内での大幅な相違です。 このように、 グルーピング - XNUMXつまたは複数の本質的な特徴に従って、ユニットの全人口を質的および量的に異なる均一なグループに分割し、社会経済的タイプを選び出し、人口の構造を研究し、または個々の特徴間の関係を分析することを可能にします。 さまざまな社会現象とその研究の目的により、多数の現象の統計的グループを使用し、これに基づいて、さまざまな特定の問題を解決することができます。 統計のグループ化の助けを借りて解決される主なタスクは次のとおりです。 1) 社会経済的タイプの研究された現象全体への配分。 2)社会現象の構造の研究。 3) 社会現象間のリンクと依存関係の識別。 社会経済的タイプの研究された現象の全体における割り当てに関連するすべてのグループは、統計の中心的な場所を占めています。 このタスクは、公的生活の最も重要で決定的な側面に関連しています。たとえば、社会的地位、性別、年齢、教育レベルに従って人口をグループ化し、所有形態、業界の所属に従って企業や組織をグループ化します。 このようなグループ分けを長期にわたって構築することで、社会経済関係の発展過程をたどることが可能になります。 社会経済的タイプに従って社会現象の全体を分割する作業は、類型学的グループを構築することによって解決されます。 このように、 類型的グループ化 - これは、質的に異質な研究集団を、社会経済的タイプに従って同質の単位グループに分割することです。 社会現象の構造の研究、すなわち、特定のタイプの現象の構成の違いの研究 (現象の構成部分間の相関関係、一定期間にわたるこれらの相関関係の変化) の研究は、非常に重要です。時間)。 この上、 構造的グループ 均質な個体群が、いくつかのさまざまな特徴に従ってその構造を特徴付けるグループに分割されるグループ化と呼ばれます。 構造的グループ化には、性別、年齢、教育レベルによる人口のグループ化、従業員数、賃金レベル、仕事量などによる企業のグループ化が含まれます。社会現象の構造の変化は、最も重要な現象を反映しています。それらの開発パターン。 たとえば、1959 年から 1994 年の間1994 年から 2002 年にかけて、都市部の人口は増加し続け、農村部の人口は減少しています。 これらの人口グループの比率は変わっていません。 構造グループを使用すると、集団の構造を明らかにするだけでなく、調査中のプロセス、その強度、空間の変化、および多くの期間にわたって取得された構造グループを分析することもでき、構成の変化のパターンが明らかになります。時間の経過に伴う人口。 構造グループは、XNUMX つ以上の属性的または定量的特徴に基づくことができます。 それらの選択は、特定の研究の目的と研究中の母集団の性質によって決定されます。 上記のグループ化は、属性ベースで構築されています。 定量的属性による構造的グループ化の場合、グループの数とその境界を決定する必要があります。 この問題は、調査の目的に従って解決されます。 調査の目標と目的に応じて、同じ統計資料をさまざまな方法でグループに分けることができます。 主なことは、調査中の現象の特徴をグループ化する過程で明確に反映され、特定の結論と推奨事項の前提条件が作成されるように努めることです。 等間隔を扱う方が技術的にはより便利ですが、研究された現象と機能の特性のために、これが常に可能であるとは限りません。 経済では、経済現象の性質上、不均等で徐々に増加する間隔を適用することがより頻繁に必要になります。 不等間隔の使用は、主に、同じ値によるグループ化特性の絶対的な変化が、特性の値が大きいグループと小さいグループの同じ値からはほど遠いという事実によるものです。 たとえば、最大300人の従業員を抱える100つの企業間では、10人を超える従業員を抱える企業よりも000人の従業員の差が大きくなります。 グループ間隔は、下限と上限が指定されている場合は閉じ、グループ境界のXNUMXつだけが指定されている場合は開くことができます。 オープンインターバルは、極端なグループにのみ適用されます。 不等間隔でグループ化する場合、閉じた間隔でグループを形成することが望ましいです。 これは、統計計算の精度に貢献します。 統計的観察の目標の XNUMX つは、社会現象間のリンクと依存関係を特定することです。 類型学的グループ化に基づいて実行される統計分析の重要なタスクは、つまり、同じ定性的な集団内で、個々の機能間の関係を調査および測定するタスクです。 分析グループ化により、そのような接続の存在を確立できます。 分析グループ化 - グループごとの特徴の一般化された値の並行比較によって発見される関係の統計的研究の一般的な方法。 従属的な兆候があり、その値は他の兆候の影響下で変化します(通常、統計では効果的と呼ばれます)、および他の兆候に影響を与える因子兆候があります。 通常、分析グループ化の基礎は符号係数であり、有効な符号に従ってグループ平均が計算され、その値の変化によって符号間の関係の存在が決定されます。 したがって、このようなグループ化は分析的と呼ぶことができ、同じタイプの母集団のユニットの生産特性と要素特性の間の関係を確立して研究することができます。 分析グループ化の重要な問題は、グループ数の正しい選択とそれらの境界の決定です。これにより、接続の特性の客観性が保証されます。 分析は同じ品質のセットで実行されるため、特定のタイプを分割するための理論的根拠はありません。 したがって、特定の分析の特定の要件と条件を満たす任意の数のグループへの母集団の内訳は許容されます。 分析グループ化のプロセスでは、一般的なグループ化規則に従う必要があります。つまり、形成されたグループ内のユニットは大きく異なり、グループ内のユニット数は信頼できる統計的特性を計算するのに十分でなければなりません。 さらに、グループ平均は特定のパターンに従う必要があります: 一貫して増加または減少します。 統計的観測データを直接グループ化することが主なグループ化です。 二次グループ化は、以前にグループ化されたデータを再グループ化することです。 二次グループ化が必要になるのは、次の XNUMX つの場合です。 1) 以前に作成されたグループ化が、グループ数に関して研究の目的を満たしていない場合。 2) 一次グループ化が異なるグループ化特性に従って、または異なる間隔で実行された場合、異なる期間または異なる地域に関するデータを比較する。 二次グループ化には XNUMX つの方法があります。 1) 小さなグループから大きなグループへの関連付け。 2)人口単位の特定の割合の割り当て。 科学に基づいた社会現象のグループ化では、現象の相互依存性と、現象の段階的な量的変化から根本的な質的変化への移行の可能性を考慮する必要があります。 グループ化が科学的であることができるのは、グループ化の認知目標が決定されるだけでなく、グループ化の基礎、つまりグループ化の特性が正しく選択された場合のみです。 グループ化が、ある特性に従って均質なグループへの分布、つまり、ある特性に従って均質なグループへの集団の個々の単位の組み合わせである場合、グループ化特性は、集団の個々の単位が別々のグループに結合される特性です。 。 グループ化属性を選択する場合、重要なのは属性の表現方法ではなく、研究中の現象に対するその重要性です。 この観点から、グループ化のためには、研究対象の現象の最も特徴的な特徴を表す本質的な特徴を取り上げるべきです。 最も単純なグループ化は分布シリーズです。 分布行 現象に関する統計データをグループ化し、その現象の構成や構造を特徴付ける一連の数字(数字)を「数字」といいます。 分布系列とは、グループのサイズを特徴付けるために XNUMX つの指標を使用するグループ化です。つまり、調査対象の特性に従って母集団の単位がどのように分布しているかを示す一連の数値です。 属性ベースで作成された行は、 属性行。 上記の分布系列には XNUMX つの要素が含まれます。属性の種類 (男性、女性)。 分布系列の度数と呼ばれる、各グループ内のユニットの数。 ユニットの総数のシェア (パーセンテージ) として表されるグループの数。 周波数。 度数の合計は、分数で表すと 1 になり、百分率で表すと 100% になります。 定量ベースで構築された分布系列は、変動系列と呼ばれます。 変分分布系列の量的属性の数値はバリアントと呼ばれ、特定の順序で配置されます。 バリアントは、正数と負数、絶対値と相対値で表すことができます。 変分級数は、離散型と間隔型に分けられます。 離散変分系列は、離散 (不連続) 属性、つまり整数値を取る属性に従って、母集団単位の分布を特徴付けます。 特徴の離散的なバリエーションを含む分布シリーズを構築する場合、すべてのオプションは値の昇順で書き出され、オプションの同じ値が繰り返される回数、つまり頻度がカウントされ、次のように XNUMX 行に書き込まれます。オプションの対応する値 (たとえば、子供の数による家族の分布)。 離散変動系列および属性系列の周波数は、周波数で置き換えることができます。 継続的な変動の場合、属性の値は、特定の間隔内で任意の値を取ることができます。たとえば、収入レベルごとの会社の従業員の分布などです。 区間変動系列を作成する場合、最適なグループ数(特徴の区間)を選択し、区間の長さを設定する必要があります。 最適なグループ数は、母集団の特性値の多様性を反映するように選択されます。 ほとんどの場合、グループの数は次の式で決定されます。 k = 1 + 3,32lgN = 1,441lgN + 1 ここで、k はグループの数です。 N - 人口サイズ。 たとえば、穀物の収穫量に応じて変分系列の農業企業を構築する必要があるとします。 農業企業の数 143. グループの数を決定する方法は? k = 1 + 3,321lgN = 1 + 3,321lg143 = 8,16 グループの数は整数のみで、この場合は 8 または 9 です。 結果のグループ化が分析の要件を満たさない場合は、再グループ化できます。 このようなグループ化では、グループ間の違いがしばしば消えるため、非常に多数のグループを目指して努力するべきではありません。 また、人口のいくつかの単位を含む、小さすぎるグループの形成を避ける必要があります。そのようなグループでは、大数の法則が機能しなくなり、ランダム性が可能になるためです。 可能なグループをすぐに特定できない場合は、収集した資料を最初にかなりの数のグループに分割し、次にそれらを拡大してグループの数を減らし、質的に均質なグループを作成します。 したがって、すべての場合において、グループ化は、それらの中で形成されたグループが可能な限り完全に現実に対応し、グループ間の違いが目に見え、互いに大きく異なる現象がXNUMXつに結合されないように構築する必要がありますグループ。 3. 統計表 統計的観測データが収集され、グループ化された後でも、特定の視覚的な体系化がなければ、それらを認識して分析することは困難です。 統計の要約とグループ化の結果は、統計表の形式で表示されます。 統計表 - 統計母集団の定量的説明を提供し、得られた統計要約と数値 (数値) データのグループ化の視覚的表現の形式である表。 縦と横のラインを組み合わせた外観です。 共通の横見出しと上見出しが必要です。 統計表のもう XNUMX つの特徴は、主語 (統計母集団の特徴) と述語 (母集団を特徴付ける指標) の存在です。 統計表は、要約またはグループ化の結果を最も合理的に表示する形式です。 表の件名 表で参照されている統計母集団、つまり、母集団またはそのグループの個々またはすべての単位のリストを表します。 ほとんどの場合、件名は表の左側に配置され、文字列のリストが含まれます。 テーブル述語 - これらは、表に表示される現象を特徴付ける指標です。 表の主語と述語は、異なる方法で配置できます。 これは技術的な問題です。主なことは、表が読みやすく、コンパクトで、理解しやすいことです。 統計の実践および研究作業では、さまざまな複雑さのテーブルが使用されます。 それは、調査対象集団の性質、利用可能な情報の量、および分析のタスクによって異なります。 表の主題にオブジェクトまたは領土単位の単純なリストが含まれている場合、その表は単純と呼ばれます。 単純なテーブルの主題には、統計データのグループは含まれません。 単純な表は、統計の実践において最も幅広い用途があります。 ロシア連邦の各都市の人口、平均給与などの特徴を簡単な表にまとめました。 単純なテーブルのサブジェクトに領土のリスト (たとえば、地域、領土、自治区、共和国など) が含まれている場合、そのようなテーブルは領土と呼ばれます。 単純なテーブルには説明的な情報のみが含まれており、分析機能は限られています。 研究対象の母集団と特性間の関係を詳細に分析するには、グループ表と組み合わせ表のより複雑な表の構築が必要です。 グループテーブルは、単純なものとは異なり、対象に観察対象の単位の単純なリストではなく、XNUMX つの必須属性によるグループ化を含みます。 グループ テーブルの最も単純なタイプは、分布系列を表すテーブルです。 述語に各グループのユニット数だけでなく、サブジェクト グループを量的および質的に特徴付けるその他の重要な指標が多数含まれている場合、グループ テーブルはより複雑になる可能性があります。 このような表は、グループ間で要約指標を比較するためによく使用され、特定の実用的な結論を導き出すことができます。 組み合わせ表には、より広い分析の可能性があります。 組み合わせ表は統計表と呼ばれ、XNUMX つの属性に従って形成されたユニットのグループが、XNUMX つまたは複数の属性に従ってサブグループに分割されます。 単純表やグループ表とは異なり、組み合わせ表を使用すると、主題の組み合わせグループ化の基礎を形成したいくつかの機能に対する述語インジケーターの依存関係を追跡できます。 上記の表に加えて、分割表(または頻度表)が統計の実践で使用されます。 このようなテーブルの作成の基礎は、レベルと呼ばれるXNUMXつ以上の特性に従って人口単位をグループ化することです。 たとえば、母集団は性別(男性、女性)などで分割されます。したがって、特徴Aにはn個のグラデーション(またはレベル)Aがあります。1 A2、n (例では n = 2)。 次に、特徴 A と別の特徴 B の相互作用を調べます。これは k 個の階調 (因子) B に分割されます。1、B2、Bк。 この例では、属性 B は職業に属しており、B1、B2,.,Bk 特定の価値観(医師、運転手、教師、ビルダーなど)を引き受けます。 XNUMX つ以上の特徴によるグループ化は、特徴 A と B の間の関係を評価するために使用されます。 「折り畳まれた」形式では、観測結果は n 行 k 列で構成される分割表で表すことができます。そのセルには、イベント頻度 nij が示されています。つまり、レベルの組み合わせを持つサンプル オブジェクトの数です。あi とBj。 変数AとBの間にXNUMX対XNUMXの直接またはフィードバック関数の関係がある場合、すべての周波数nijはテーブルの対角線のXNUMXつに沿って集中します。 接続がそれほど強くない場合、特定の数の観測値も非対角要素に分類されます。 このような状況下で、研究者は、ある特徴の価値を別の特徴の価値からどれだけ正確に予測できるかを見つけるという課題に直面しています。 頻度テーブルは、変数がXNUMXつだけ表になっている場合、XNUMX次元であると言われます。 XNUMXつの特徴(因子)によって表にされたXNUMXつの特徴(レベル)によるグループ化に基づくテーブルは、XNUMXつの入力を持つテーブルと呼ばれます。 XNUMXつ以上の特徴の値が表にされている頻度の表は分割表と呼ばれます。 すべての種類の統計表の中で、単純な表が最も広く使用され、グループおよび特に組み合わせ統計表はあまり使用されず、分割表は特別な種類の分析用に作成されます。 統計表は、大量の社会現象を表現および研究するための重要な方法の XNUMX つとして機能しますが、それらが正しく構築されている場合に限られます。 統計表の形式は、それが表現する現象の本質とその研究の目的に最も適したものでなければなりません。 これは、テーブルの主語と述語を適切に展開することによって実現されます。 外部的には、テーブルは小さくてコンパクトで、タイトル、測定単位の表示、および情報が関連する時間と場所が必要です。 表の行と列の見出しは簡潔に、しかし正確かつ明確に示されています。 テーブルがデジタル データで乱雑になりすぎて、ずさんなデザインになっていると、読み取りや分析が難しくなります。 統計表を作成するための基本的な規則をリストします。 1.統計表はコンパクトで、静力学と動力学で研究された社会経済現象を直接反映する初期データのみを反映する必要があります。 2. 統計表のタイトルと列と行のタイトルは、明確、簡潔、簡潔にする必要があります。 タイトルは、イベントの目的、記号、時間、場所を反映する必要があります。 3. 列と行には番号を付ける必要があります。 4. 列と行には、一般に受け入れられている略語がある測定単位を含める必要があります。 5. 分析中に比較する情報を隣接する列 (または上下に並べる) に配置することをお勧めします。 これにより、比較プロセスが容易になります。 6. 読みやすく作業しやすいように、統計表の数値は列の中央に配置する必要があります。厳密には上下に並べます。単位の下に単位、コンマの下にカンマを配置します。 7. 同じ程度の精度で数値を丸めることをお勧めします (正符号まで、最大 XNUMX 分の XNUMX まで)。 8. データがないことは乗算記号「h」で示され、この位置が埋められない場合は、情報がないことは省略記号 (...) または n で示されます。 d. または n. セント、現象がない場合は、ダッシュ(-)が付けられます。 9. 非常に小さい数値を表示するには、0.0 または 0.00 という表記を使用します。 10. 条件付き計算に基づいて得られた数値の場合は括弧で囲み、疑わしい数値には疑問符を付け、暫定的な数値には「!」を付けます。 追加情報が必要な場合は、統計表に脚注と注記を付けて、たとえば、特定の指標の性質、適用した方法論などを説明します。脚注は、表を読むときに考慮しなければならない限定的な状況を示すために使用されます。 これらのルールが守られている場合、統計表は、研究された社会経済現象の状態と発展に関する統計情報を提示、処理、および要約する主要な手段になります。 4。 統計情報のグラフィック表現 全体としての要約または統計分析の結果として得られた数値指標は、表形式だけでなくグラフ形式でも表示できます。 グラフを使用して統計情報を表示すると、統計データに視覚化と表現力を与え、それらの認識、および多くの場合、分析を容易にすることができます。 統計指標のさまざまなグラフィック表現は、現象またはプロセスの最も表現力豊かなデモンストレーションのための絶好の機会を提供します。 グラフ 統計学では、点、線、平面図形など、さまざまな幾何学的イメージの形式で表現された数値量とその関係の従来のイメージを、「点」、「線」、「平面図」などと呼びます。 統計グラフを使用すると、調査中の現象の性質、固有のパターンと特徴、開発傾向、およびそれを特徴付ける指標の関係を即座に評価できます。 各グラフは、グラフィック画像と補助要素で構成されています。 グラフィックイメージ 統計データを表す点、線、および形状のコレクションです。 グラフの補助要素には、グラフの一般名、座標軸、スケール、数値グリッド、および表示されたインジケーターを補完および改良する数値データが含まれます。 補助要素は、グラフの読み取りとその解釈を容易にします。 チャートのタイトルは、その内容を簡潔かつ正確に説明する必要があります。 説明テキストは、グラフィック イメージ内またはその横に配置することも、グラフィック イメージの外に配置することもできます。 プロットして使用するには、目盛りが印刷された座標軸と数値グリッドが必要です。 スケールは、直線または曲線(円形)、均一(線形)、および不均一にすることができます。 多くの場合、XNUMX つまたは XNUMX つの平行線に基づいて構築された、いわゆる共役スケールを使用することをお勧めします。 ほとんどの場合、共役スケールの XNUMX つは絶対値の測定に使用され、XNUMX つ目は対応する相対値の測定に使用されます。 スケール上の数値は均等に配置され、最後の数値はインジケーターの最大レベルを超える必要があり、その値はこのスケールで計算されます。 原則として、数値グリッドにはベースラインが必要であり、その役割は通常 X 軸によって行われます。 統計グラフは、目的 (内容)、作成方法、グラフィック イメージの性質など、さまざまな基準に従って分類できます。 内容または目的に応じて、次のように区別できます。 1) 空間比較のグラフ; 2)さまざまな相対値のグラフ(構造、ダイナミクスなど); 3) 変動シリーズのグラフ。 4) 地域別配置スケジュール。 5) 相互に関連する指標のグラフなど グラフィックスはその構築方法に応じて図表と統計地図に分けられます。 ダイアグラムは、グラフィック表現の最も一般的な方法です。 これらは定量的な関係を示すグラフです。 その施工方法や種類も様々です。 図は、領土、人口など、互いに独立した値のさまざまな側面(空間的、時間的など)で視覚的に比較するために使用されます。この場合、研究対象の集団の比較は、いくつかの重要な変化する特性に従って行われます。 。 統計マップ - 表面上の定量的分布のグラフ。 その主な目的において、それらはダイアグラムと密接に関連しており、等高線地理地図上の統計データの従来のイメージを表す、つまり統計データの空間分布または空間分布を示すという意味でのみ特殊です。 グラフィック イメージの性質に基づいて、ドット、線形、平面 (棒、ストリップ、正方形、円形、扇形、波状) および体積グラフに分類されます。 散布図を作成する場合は点の集合がグラフィック イメージとして使用され、線形図を作成する場合は線が使用されます。 すべての平面図を作成する基本原理は、統計量が幾何学的図形の形式で表現されることです。 統計地図は、グラフィカルにカートグラムとカルトダイアグラムに分類されます。 解決するタスクの範囲に応じて、比較図、構造図、ダイナミクス図が区別されます。 最も一般的な比較グラフは棒グラフであり、その作成原理は統計指標を垂直の長方形、つまり棒の形で表すことです。 各列は、調査対象の統計系列の別のレベルの値を表します。 したがって、比較されるすべての指標が XNUMX つの測定単位で表現されるため、統計指標の比較が可能です。 棒グラフを作成するときは、棒が配置される直交座標系を描く必要があります。 横軸は柱の底面であり、底面の大きさは任意に決められますが、誰でも同じに設定されます。 柱の高さのスケールを決定するスケールは、垂直軸に沿って配置されます。 各バーの垂直サイズは、グラフに表示される統計指標のサイズに対応します。 したがって、グラフを構成するすべての棒において、変数となるのは XNUMX つの軸だけです。 グラフ フィールド内のバーの配置は異なる場合があります。 1) 互いに同じ距離にある。 2)互いに近い。 3) お互いに個人的に押し付け合う。 棒グラフを作成するためのルールにより、複数の指標の画像を同じ横軸に同時に配置できます。 この場合、列はグループに配置され、それぞれの列に対してさまざまな特徴の異なる次元を取得できます。 棒グラフの一種は、いわゆるストリップ (またはストリップ) グラフです。 それらの違いは、スケールが上部に水平に配置されており、ストライプの長さが決定されることです。 棒グラフと帯グラフの作成ルールは同じであるため、適用範囲は同じです。 描かれた統計指標の一次元性と、さまざまな列およびストライプに対するそれらの XNUMX スケールの性質には、比例性 (列の高さ、ストライプの長さ) と描かれた値への比例性の遵守という XNUMX つの規定を満たす必要があります。 この要件を満たすには、次のことが必要です。まず、柱 (バー) のサイズを設定するスケールがゼロから始まること。 第 XNUMX に、このスケールは連続的である必要があります。つまり、特定の統計系列のすべての数値をカバーする必要があります。 スケールを壊すこと、それに応じて柱 (ストリップ) を壊すことは許可されません。 これらのルールに従わないと、分析された統計資料のグラフィック表現が歪んでしまいます。 統計データをグラフィカルに表現する方法としての棒グラフと帯グラフは、本質的に互換性があります。つまり、検討中の統計指標は、棒グラフと横棒グラフの両方で同等に表示できます。 どちらの場合も、現象の大きさを表すために、各長方形の XNUMX つの測定値 (柱の高さまたはストリップの長さ) が使用されます。 したがって、これら XNUMX つの図の適用範囲は基本的に同じです。 棒グラフのバリエーションとして、方向性グラフがあります。 通常のものと異なるのは、柱またはストライプの両面配置であり、中央にスケール基準点があります。 通常、このような図は、反対の定性的値の量を表すために使用されます。 異なる方向に向けられたカラム (ストリップ) を相互に比較することは、同じ方向に隣接して配置されたカラム (ストリップ) を比較する場合よりも効果が低くなります。 それにもかかわらず、特別な位置がグラフに明るいイメージを与えるため、方向図の分析により、非常に意味のある結論を引き出すことができます。 両面グループには、純粋な偏差の図が含まれています。 それらでは、ストライプは垂直のゼロ線から両方向に向けられています。右に向かうと増加し、左に向かうと減少します。 このような図を使用すると、比較の基準となる計画または特定のレベルからの逸脱を示すのに便利です。 検討中の図の重要な利点は、調査対象の統計的特性の変動範囲を確認できることであり、それ自体が分析にとって非常に重要です。 互いに独立した指標を簡単に比較するには、図を使用することもできます。その構築原理は、比較される量が規則的な幾何学的図形の形で描かれ、それらの面積が次のように相互に関連するように構築されることです。これらの図によって示される量。 つまり、これらの図は、描かれている現象の大きさを面積の大きさで表現しているのです。 検討中のタイプの図を取得するには、正方形、円、そしてまれに長方形など、さまざまな幾何学的形状が使用されます。 正方形の面積はその辺の二乗に等しく、円の面積は半径の二乗に比例して決まることが知られています。 したがって、図を作成するには、まず比較される値から平方根を抽出し、次に得られた結果に基づいて、許容されるスケールに従って正方形の辺または円の半径を決定する必要があります。 最も表現力があり、簡単に理解できるのは、図記号の形で比較図を作成する方法です。 この場合、統計的集計は幾何学的な数字ではなく、記号または記号で表されます。 グラフィック表現のこの方法の利点は、比較された母集団の内容を反映する同様の表示を取得することで、高度な明瞭さにあります。 図の最も重要な機能は縮尺です。 したがって、カーリー チャートを正しく作成するには、勘定単位を決定する必要があります。 後者として、条件付きで特定の数値が割り当てられた別の数字(記号)が取られます。 また、調査中の統計値は、同じサイズの別の数の図で表され、図に順番に配置されます。 ただし、ほとんどの場合、整数の数字で統計を表すことはできません。 スケールの観点からすると、XNUMX文字は測定単位が大きすぎるため、最後の部分はパーツに分割する必要があります。 通常、この部分は目で判断します。 それを正確に判断することの難しさは、カーリー ダイアグラムの欠点です。 ただし、統計データの表示の正確さは追求されておらず、結果は非常に満足のいくものです。 原則として、図表は統計や広告を広めるために広く使用されています。 構造図の主な構造は、各集計のさまざまな部分の比率として特徴付けられる、統計集計の構成のグラフィカルな表現です。 統計母集団の構成は、絶対指標と相対指標の両方を使用してグラフで表すことができます。 前者の場合、部分の大きさだけでなく、グラフ全体の大きさも統計値によって決まり、後者の変化に応じて変化します。 100 番目では、グラフ全体のサイズは変化せず (セットのすべての部分の合計が XNUMX% であるため)、個々の部分のサイズのみが変化します。 人口構成を絶対指標と相対指標でグラフ表示することで、より詳細な分析が容易になり、社会経済現象の国際比較や比較が可能になります。 母集団の構造をグラフィカルに表現する最も一般的な方法は円グラフであり、この目的のための主要な形式のグラフと見なされます。 これは、全体の考え方が、全体を表す円によって非常によく明確に表現されているためです。 円グラフの母集団の各部分の比重は、中心角 (円の半径間の角度) の値によって特徴付けられます。 360° に等しい円のすべての角度の合計は 100% に等しいため、1% は 3,6° に等しいと見なされます。 円グラフを使用すると、人口の構造とその変化をグラフィカルに表すだけでなく、この人口の規模のダイナミクスを示すこともできます。 これを行うために、調査中の特性の量に比例する円が構築され、その個々の部分がセクターによって区別されます。 人口構造のグラフィック表現の考慮された方法には、長所と短所の両方があります。 したがって、円グラフは母集団の少数の部分でのみ可視性と表現力を保持します。それ以外の場合、その使用は効果的ではありません。 さらに、円グラフの視認性は、描かれている集団の構造にわずかな変化があると減少します。比較された構造の違いがより重要である場合、それは高くなります。 円グラフと比較した棒(リボン)構造図の利点は、容量が大きく、より多くの有用な情報を反映できることです。 ただし、これらのグラフは、調査対象の母集団の構造のわずかな違いに対してより効果的です。 動的な図は、時間内の現象の進展を描写し、判断するために作成されます。 一連のダイナミクスの現象を視覚的に表現するために、棒、帯、正方形、円形、線形、放射状などの図が使用されます。図の種類の選択は、主に初期データの特性、目的に依存します。研究。 たとえば、時間的に不等間隔のレベルがいくつかある一連のダイナミクスがある場合(1914、1049、1980、1985、1996、2003)、わかりやすくするために棒グラフ、正方形グラフ、または円グラフがよく使用されます。 それらは視覚的に印象的で、よく覚えられていますが、面倒なので、多数のレベルを描くのには適していません。 一連のダイナミクスのレベル数が多い場合は、連続した破線の形で開発プロセスの連続性を再現する線図を使用することをお勧めします。 さらに、折れ線グラフは便利に使用できます。 1) 調査の目的が、現象の発展の一般的な傾向と性質を描写することである場合。 2) 複数の時系列を比較するために XNUMX つのグラフに表示する必要がある場合。 3)最も重要なのがレベルではなく成長率の比較である場合。 線形グラフを作成するには、直交座標系が使用されます。 通常、時間 (年、月など) が横軸に沿ってプロットされ、描かれた現象またはプロセスの次元が縦軸に沿ってプロットされます。 スケールは縦軸にマークされています。 グラフの全体的な外観はこれに依存するため、その選択には特に注意を払う必要があります。 グラフィックスでは、座標軸間のバランスと比例性を確保することが必要です。座標軸間の不均衡は、現象の展開の誤ったイメージを与えるためです。 横軸の目盛りが縦軸の目盛りに比べて大きく伸びていると、現象のダイナミクスの揺らぎが目立ちにくくなり、逆に縦軸の目盛りが縦軸の目盛りに比べて大きくなります。横軸は急激な変動を与えます。 等しい期間とレベル サイズは、スケールの等しいセグメントに対応する必要があります。 統計の実践では、均一なスケールを持つグラフィック イメージが最もよく使用されます。 横軸に沿って、それらは期間の数に比例して取得され、縦軸に沿って、レベル自体に比例して取得されます。 均一スケールのスケールは、セグメントを1本とした長さになります。 多くの場合、3 つの線形グラフには、異なる指標または同じ指標のダイナミクスの比較説明を提供する複数の曲線が表示されます。 ただし、4 つのグラフに XNUMX ~ XNUMX 個を超える曲線を配置しないでください。曲線の数が多いと必然的に描画が複雑になり、線形図の明瞭さが失われます。 場合によっては、XNUMX つのグラフに XNUMX つの曲線をプロットすると、最初の XNUMX つの指標の差である場合、XNUMX 番目の指標のダイナミクスを同時に描写することが可能になります。 たとえば、出生率と死亡率の動態を表す場合、XNUMX つの曲線の間の領域は、人口の自然増加または自然減少の量を示します。 場合によっては、測定単位が異なる XNUMX つのインジケーターのダイナミクスをグラフ上で比較する必要があります。 このような場合、スケールは XNUMX つではなく XNUMX つ必要になります。 そのうちの XNUMX つは右側に、もう XNUMX つは左側に配置されます。 ただし、スケールが任意であるため、このような曲線の比較は、これらの指標のダイナミクスの十分に完全な全体像を提供しません。 したがって、XNUMXつの異なる指標のレベルのダイナミクスの比較は、絶対値を相対値に変換した後、XNUMXつのスケールの使用に基づいて実行する必要があります。 線形スケールの線形チャートには、認知的価値を低下させるXNUMXつの欠点があります。均一なスケールでは、調査期間中に図に反映された指標の絶対的な増加または減少のみを測定および比較できます。 ただし、ダイナミクスを研究するときは、達成されたレベルまたはそれらの変化率と比較した、研究された指標の相対的な変化を知ることが重要です。 均一な垂直スケールの座標図に描かれたときに歪むのは、ダイナミクスの経済指標の相対的な変化です。 さらに、従来の座標では、すべての明瞭さが失われ、レベルが急激に変化する時系列で表示することさえ不可能になります。これは通常、長期間にわたって時系列で発生します。 このような場合、均一なスケールは破棄し、グラフは片対数システムに基づく必要があります。 半対数システムの主な考え方は、その中で等しい線形セグメントが数値の対数の等しい値に対応するということです。 このアプローチには、対数換算により大きな数値のサイズを縮小できるという利点があります。 ただし、目盛りが対数になっているため、グラフがわかりにくくなります。 スケールスケール上に示された対数の隣に、示された対数の数に対応する、描かれた一連のダイナミクスのレベルを特徴付ける数値自体を書き留める必要があります。 このようなタイプのグラフは、片対数グリッド上のグラフと呼ばれます。 片対数グリッドは、一方の軸に線形スケールがプロットされ、もう一方の軸に対数スケールがプロットされたグリッドです。 ダイナミクスは、極座標で構築された放射状図によっても表されます。 放射状ダイアグラムには、時間内の特定のリズミカルな動きを視覚的に描写するという目的があります。 これらのグラフの最も一般的な用途は、季節変動を示すことです。 放射状図は閉じた図と螺旋状のものに分けられます。 作図技法の観点から見ると、放射状図は、円の中心と円周のどちらを基準点とするかによって異なります。 閉じたダイアグラムは、任意の 12 年のダイナミクスの年内サイクルを反映します。 スパイラル チャートは、数年にわたるダイナミクスの年内サイクルを示します。 閉じたダイアグラムの構築は、次のようになります。円が描かれ、月平均はこの円の半径に等しくなります。 次に、円全体が 1 個の半径に分割され、グラフ上に細い線で表示されます。 各半径は月を表し、月の位置は時計の文字盤に似ています。2 月 - 時計が XNUMX を示す場所、XNUMX 月 - XNUMX を示す場所、などです。各半径で、特定の場所にマークが付けられます。対応する月のデータに基づいてスケールに従って配置されます。 データが年平均を超えている場合は、円の外側の半径の延長線上にマークが付けられます。 次に、異なる月のマークがセグメントによって接続されます。 ただし、レポートの基礎として、円の中心ではなく円を使用する場合、そのような図はらせん図と呼ばれます。 スパイラル チャートの構成は、ある年の XNUMX 月が同じ年の XNUMX 月ではなく、翌年の XNUMX 月に接続されているという点で、クローズド チャートとは異なります。 これにより、一連のダイナミクス全体をらせん状に描くことができます。 このような図は、季節の変化に伴い、年々着実に増加している場合に特に役立ちます。 統計地図は、特定の地域における特定の現象の分布のレベルまたは程度を特徴付ける、概略的な地理的地図上の統計データのグラフィック表現の一種です。 領土分布を表す手段は、ハッチング、背景の色付け、または幾何学的形状です。 カートグラムとカートグラムがあります。 カートグラム - これは図式的な地理的地図であり、さまざまな密度、ドット、またはある程度の彩度の色のハッチングは、地図上にプロットされた領土分割の各単位内の指標の比較強度を示しています (たとえば、地域ごとの人口密度)または共和国、収穫量による地域の分布など)。 カートグラムは、背景と点に分かれています。 カートグラムの背景 -カルトグラムの一種で、さまざまな密度の陰影またはある程度の彩度の色が、地域単位内のインジケーターの強度を示します。 ドット カートグラム - 選択された現象のレベルが点で表される一種のカートグラム。 ドットは、集合体の XNUMX つのユニットまたは特定の数のユニットを表し、地理的な地図上で特定の機能の出現の密度または頻度を示します。 バックグラウンド カートグラムは、原則として、体積 (定量) 指標 (人口、家畜など) の平均または相対指標、ポイント マップを描写するために使用されます。 統計マップの XNUMX 番目の大きなグループはチャート ダイアグラムです。これは、ダイアグラムと地理マップを組み合わせたものです。 チャート図 (バー、四角形、円、数字、ストライプ) は、地図の等高線上に配置されるカートグラムの比喩的な記号として使用されます。 カートグラムは、カートグラムよりも地理的に複雑な統計的および地理的構造を反映することを可能にします。 カルトダイアグラムの中で、単純な比較のカルトダイアック、空間変位のグラフ、等値線を区別する必要があります。 単純な比較のカートグラムでは、通常のチャートとは異なり、調査中の指標の値を表すチャート図は、通常のチャートのように一列に配置されていませんが、地域に従ってマップ全体に広がっています、彼らが代表する地域または国。 最も単純な地図作成図の要素は、住民の数に応じてさまざまな幾何学的形状によって都市が区別される政治地図で見つけることができます。 輪郭 - これらは、特に地理的な地図やグラフ上で、表面上の分布における量の等しい値の線です。 等値線は、他の XNUMX つの変数に応じて調査された量の連続的な変化を反映し、自然および社会経済現象のマッピングに使用されます。 等値線は、調査した量の定量的特性を取得し、それらの間の相関を分析するために使用されます。 LECTURE No.4.統計値と指標 1. 統計指標および値の目的と種類 統計指標の性質と内容は、それらを反映する経済的および社会的現象とプロセスに対応しています。 すべての経済的および社会的カテゴリーまたは概念は抽象的な性質のものであり、最も重要な特徴である現象の一般的な相互接続を反映しています。 そして、現象やプロセスのサイズと相関関係を測定するために、つまり、それらに適切な定量的特性を与えるために、彼らは各カテゴリー(概念)に対応する経済的および社会的指標を開発します。 経済的および社会的現象とプロセスの量的および質的特性の統一を保証するのは、経済的カテゴリーの本質の指標の対応です。 社会の経済的および社会的発展の指標には、計画 (予測) と報告 (統計) の XNUMX 種類があります。 計画された指標は、指標の特定の特定の値であり、その達成は将来の期間で予測されます。 報告指標は、経済的および社会的発展の実際の状況、つまり一定期間に実際に達成されたレベルを特徴付けます。 統計(レポート)指標 -これは、特定の場所と時間の条件における定性的な確実性における社会現象またはプロセスの客観的な定量的特性(尺度)です。 各統計指標には、定性的な社会経済的内容と関連する測定方法があります。 統計指標には、XNUMXつまたは別の統計形式(構造)もあります。 指標は、人口単位の総数、これらの単位の量的属性の値の合計、属性の平均値、別の値に対するこの属性の値などを表すことができます。 統計指標にも一定の数値や数値表現があります。 この統計指標の数値は、特定の測定単位で表され、マグニチュードと呼ばれます。 インジケーターの値は通常、空間によって異なり、時間とともに変動します。 したがって、統計指標の必須属性は、地域および瞬間または期間の指標でもあります。 統計指標は、条件付きで一次 (量的、定量的、広範) と二次的 (微分、質的、集中的) に分けることができます。 一次人口単位の総数、またはそれらの属性の値の合計のいずれかを特徴付けます。 時間の経過に伴う変化のダイナミクスを考慮すると、それらは、経済全体または特定のケースの特定の企業の広範な発展経路を特徴付けます。 統計形式によると、これらの指標は統計値の合計です。 二次的 (微分) 指標は、通常、平均値および相対値として表され、ダイナミクスを考慮して、通常、集中的な開発の経路を特徴付けます。 社会経済現象とプロセスの複雑なセットのサイズを特徴付ける指標は、しばしば合成と呼ばれます (GDP、国民所得、社会労働生産性、消費者バスケットなど)。 使用される測定単位に応じて、自然、コスト、および労働の指標があります (工数、標準時間)。 適用範囲に応じて、地域レベル、部門レベルなどで計算された指標があります。反映された現象の精度に応じて、指標の期待値、暫定値、最終値が区別されます。 統計研究の対象の量と内容に応じて、個々の(母集団の個々の単位を特徴付ける)指標と要約(一般化する)指標が区別されます。 したがって、質量または単位のセットを特徴付ける統計値は、一般化統計指標(値)と呼ばれます。 サマリー指標は、次の特徴により、統計調査において非常に重要な役割を果たします。 1)研究された社会現象の単位の集合体の要約(集中)説明を与える。 2) 現象間に存在する接続と依存関係を表現し、現象の相互接続された研究を提供します。 3) 現象で起こっている変化、それらの発展の新たなパターン、およびその他のものを特徴付けます。つまり、一般化された量自体をそれらの構成部分、それらの決定要因など。 複雑な経済的および社会的カテゴリーの客観的で信頼できる研究は、統一と相互接続において、これらのカテゴリーの発展の状態とダイナミクスのさまざまな側面と側面を特徴付ける統計的指標のシステムに基づいてのみ可能です。 統計指標は、経済的および社会的現象とプロセスの統一性と相互関係を客観的に反映するものであり、突飛で恣意的に構築されたドグマではなく、一度だけ確立されたものです。 それどころか、社会、科学、コンピューター技術の動的な発展、統計手法の改善により、価値を失った時代遅れの指標が変化または消滅し、現在の状況を客観的かつ確実に反映する新しいより高度な指標が出現するという事実につながります。社会開発の。 したがって、統計指標の構築と改善は、次の XNUMX つの基本原則の遵守に基づく必要があります。 1) 客観性と現実性 (指標は、関連する経済的および社会的カテゴリー (概念) の本質を誠実かつ適切に反映する必要があります); 2) 包括的な理論的および方法論的妥当性 (指標の値の決定、その測定可能性、およびダイナミクスにおける比較可能性は、科学的に推論され、明確かつ容易に定式化され、統一された解釈で明確に適用可能でなければなりません)。 さらに、指標の値は、対応する経済的または社会的現象の状態または発展のレベル、規模、および質的兆候(産業および地域レベル、個々の企業または従業員など)を考慮して、正しく定量化する必要があります。 . 同時に、指標の構築は、関連する指標を要約するだけでなく、グループと集計における質的な均一性を確保し、ある指標から別の指標への移行を完全に行うことができるように、分野横断的な性質のものでなければなりません。より複雑なカテゴリまたは現象のボリュームと構造を特徴付けます。 最後に、統計指標の構築、その構造および本質は、調査中の現象またはプロセスを包括的に分析し、その開発の特徴を特徴付け、それに影響を与える要因を決定する可能性を提供する必要があります。 統計量の計算と調査対象の現象に関するデータの分析は、統計調査の第 XNUMX 段階であり最終段階です。 統計では、絶対値、相対値、平均値など、いくつかのタイプの統計量が考慮されます。 統計指標の一般化には、時系列、指標などの分析指標も含まれます。 2. 絶対統計 統計的観察は、その範囲と目標に関係なく、常に特定の社会経済現象とプロセスに関する情報を絶対指標の形で提供します。つまり、定性的確実性の条件における社会経済現象とプロセスの定量的特性である指標です。 絶対指標の定性的な確実性は、それらが研究対象の現象またはプロセスの特定の内容、その本質に直接関連しているという事実にあります。 この点で、絶対指標と絶対値には、その本質(内容)を最も完全かつ正確に反映する特定の測定単位が必要です。 絶対指標は、統計現象の兆候を定量的に表現したものです。 たとえば、高さは特徴であり、その値は成長の尺度です。 絶対的な指標は、特定の場所および特定の時点で研究されている現象またはプロセスのサイズを特徴付ける必要があり、それは何らかのオブジェクトまたは領域に「結び付けられ」ている必要があり、人口の別個の単位(個々のオブジェクト)を特徴付けることができます。統計上の母集団の一部、または統計上の母集団全体 (たとえば、国の人口) などを表す、企業、労働者、または単位のグループ。最初のケースでは、個人の絶対的なものについて話しています。指標について、XNUMX 番目では集計絶対指標について説明します。 個々の価値 -人口の個々のユニットのサイズを特徴付ける絶対値(たとえば、シフトごとにXNUMX人の労働者が製造する部品の数、別の家族の子供の数)。 それらは統計的観察の過程で直接取得され、主要な会計伝票に記録されます。 個々の指標は、特定の現象やプロセスの統計的観察の過程で、関心のある固定された量的特性の評価、計算、測定の結果として得られます。 要約値 -絶対値は、原則として、個々の個々の値を合計することによって取得されます。 要約絶対指標は、個々の絶対指標の値を要約およびグループ化した結果として取得されます。 したがって、たとえば、人口調査の過程で、州の統計機関は、国の人口、地域別、性別、年齢などによるその分布に関する最終的な絶対データを受け取ります。 絶対指標には、統計的観察の結果としてではなく、何らかの計算の結果として得られる指標も含まれます。 原則として、これらの指標は異なる性質のものであり、XNUMX つの絶対指標の差として検出されます。 たとえば、人口の自然増加(減少)は、一定期間の出生数と死亡数の差として求められます。 その年の生産量の増加は、年末の生産量と年初の生産量の差として求められます。 国の経済の発展のための長期予測を編集するとき、材料、労働、および財源に関する推定データが計算されます。 例からわかるように、これらのインジケーターには絶対的な測定単位があるため、絶対的なものになります。 絶対値は、現象の自然な根拠を反映しています。 それらは、調査中の母集団、その個々の構成要素、またはそれらの物理的特性 (重量、長さなど) から生じる自然単位、またはそれらの経済的特性から生じる測定単位の絶対サイズの単位数のいずれかを表します。 . (これはコスト、人件費です)。 したがって、絶対値には常に一定の次元があります。 さらに、絶対統計指標は常に数値と呼ばれます。つまり、それらが記述するプロセスと現象の性質に応じて、物理的、コスト、および労働の測定単位で表されます。 自然メートルは、自然な形で現象を特徴付け、長さ、重量、体積など、または単位数、イベント数で表されます。 自然単位には、トン、キログラム、メートルなどの測定単位が含まれます。 場合によっては、異なる次元で表現された XNUMX つの量の積である、結合された測定単位が使用されます。 たとえば、発電量はキロワット時、貨物売上高はトンキロなどで測定されます。 自然測定単位のグループには、いわゆる条件付き自然測定単位も含まれます。 それらは、個々の値が、消費者特性が類似しているが、脂肪含有量、アルコール、カロリー含有量などで異なる個々のタイプの製品を特徴付ける場合に、合計絶対値を取得するために使用されます。この場合、製品のタイプの XNUMX つが条件付き自然メーターと見なされ、個々の品種の消費者特性 (場合によっては労働強度、コストなど) の比率を表す変換係数の助けを借りて、この製品のすべての品種が与えられます。 労働測定単位は、人件費の評価を可能にし、労働資源の利用可能性、分布、および使用を反映する指標を特徴付けるために使用されます (たとえば、工数で実行される作業の労働強度)。 自然な手段や場合によっては労働手段では、異種製品の状態で統合された絶対的な指標を取得することはできません。 この点において、コストの測定単位は普遍的であり、社会経済現象の金銭的(金銭的)評価を与え、特定の製品または実行される作業量のコストを特徴づけます。 たとえば、国民所得、国内総生産などの国の経済にとって重要な指標は、通貨の形で表され、企業レベルでは利益、自己資金、借入資金などで表されます。 原価計算は普遍的なものであるため、統計では原価単位が最も優先されますが、常に受け入れられるとは限りません。 絶対指標は時間と空間で計算できます。 たとえば、1991年から2004年までのロシア連邦の人口のダイナミクスは時間的要因に反映されており、2004年のロシア連邦地域のベーカリー製品の価格水準は空間比較によって特徴付けられます。 時間の経過に伴う絶対指標(ダイナミクス)を考慮する場合、その登録は特定の日付、つまり任意の時点(年初の企業の固定資産のコスト)および任意の期間に実行できます。時間(年間の出生数)。 最初のケースでは、インジケーターは瞬間的であり、XNUMX番目の場合はインターバルです。 空間的確実性の観点から、絶対的指標は次のように分類されます:一般領域、地域、および地方。 たとえば、GDP (国内総生産) の量は一般的な地域指標であり、GRP (地域総生産) の量は地域指標であり、都市の従業員数は地域指標です。 したがって、指標の最初のグループは、国全体、地域 - 特定の地域、地方 - 別の都市、地域などを特徴付けます。 絶対的な指標は、これまたはその部分が全人口に占める割合の問題に答えません; 計画されたタスクのレベル、計画の達成度、これまたはその現象の強度を特徴付けることができません。常に比較に適しているため、相対値の計算にのみ使用されることがよくあります。 3. 相対統計 絶対値とともに、統計における一般化指標の最も重要な形式の XNUMX つは相対値です。 現代の生活では、事実を比較対照する必要性に直面することがよくあります。 「比較してすべてが知られている」ということわざがあるからだけではありません。 比較の結果は、相対値を使用して表されます。 相対値は、特定の現象または統計オブジェクトに固有の量的比率の尺度を表す一般化指標です。 相対値を計算する場合、相互に関連する XNUMX つの値の比率 (ほとんどが絶対値) が取得されます。つまり、それらの比率が測定されます。これは、統計分析において非常に重要です。 相対値は、さまざまな指標の比較を可能にし、そのような比較を明確にするため、統計研究で広く使用されています。 相対量は XNUMX つの数値の比として計算されます。 この場合の分子を比較対象の値、分母を相対比較の基準といいます。 研究対象の現象の性質や研究の目的に応じて、基本量はさまざまな値をとることがあり、それが相対量のさまざまな表現形式につながります。 相対量は次のように測定できます。 1) 係数; 比較の基数が 1 の場合、相対値は整数または分数として表され、一方の値が他方の値よりも何倍大きいか、またはその一部が示されます。 2) 比較基準を 100 とした場合のパーセンテージ。 3) 比較基準を 1000 とした場合の ppm 単位。 4) 比較の基準が 10 の場合、デシミル単位。 5) 名前付き数字 (km、kg、ha) など それぞれの特定のケースでは、相対値のいずれかの形式の選択は、研究の目的と社会経済的本質によって決定され、その尺度は望ましい相対指標です。 その内容に応じて、相対値は次のタイプに分類されます。契約上の義務の履行。 ダイナミクス; 構造; 調整; 強度; 比較。 契約義務の相対価値は、契約で規定されたレベルに対する契約の実際の履行の比率です。 この値は、企業が契約上の義務をどの程度履行したかを反映しており、数値 (全体または分数) またはパーセンテージで表すことができます。 同時に、当初比率の分子と分母が同じ契約上の義務に対応している必要があります。 ダイナミクスの相対値 - 成長率 - は、時間の経過に伴う社会現象の大きさの変化を特徴付ける指標です。 ダイナミクスの相対的な大きさは、一定期間にわたる同様の現象の変化を示します。 この値は、後続の各期間を最初または前の期間と比較することによって計算されます。 最初のケースでは基本的なダイナミクス値を取得し、XNUMX 番目のケースではチェーン ダイナミクス値を取得します。 どちらの量も係数またはパーセンテージとして表されます。 得られる結果の実際の値はこれに大きく依存するため、ダイナミクスの相対値や他の相対指標を計算するときの比較基準の選択には特別な注意を払う必要があります。 構造の相対値は、調査対象の母集団の構成部分を特徴付けます。 母集団の相対値は、次の式で計算されます。  構造の相対値は通常比重と呼ばれ、全体の特定の部分を全体で割って100%として計算されます。 この値には 100 つの特徴があります。調査対象の母集団の相対値の合計は、常に 1% または XNUMX (表現方法に応じて) に等しくなります。 構造の相対値は、いくつかのグループまたは部分に分類される複雑な現象の研究で、全体における各グループの比重 (シェア) を特徴付けるために使用されます。 調整の相対値は、人口の個々の部分とそれらの100つとの比率を特徴付け、比較の基礎とします。 この値を決定するときは、全体の一部を比較の基準とします。 この値を使用すると、母集団の構成要素間の比率を観察できます。 調整の指標は、たとえば、農村部 100 人あたりの都市部住民の数です。 男性 XNUMX 人あたりの女性の数。 配位の相対値の分子と分母は同じ測定単位を持っているため、これらの値は名前付きの数値ではなく、パーセンテージ、ppm、または複数の比率で表されます。 相対強度値は、任意の環境における特定の現象の蔓延を決定する指標です。 それらは、特定の現象の絶対値とそれが発生する環境のサイズの比率として計算されます。 相対強度値は、統計の実践で広く使用されています。 この値の例としては、人口と居住面積の比率、資本生産性、人口に対する医療の提供 (人口 10 人あたりの医師数)、労働生産性のレベル (労働者あたりの生産量または単位労働時間あたり)など。 したがって、強度の相対的な値は、さまざまな種類のリソース(材料、財政、労働)の使用の効率、国の人口の生活の社会的および文化的基準、および公共生活の他の多くの側面を特徴づけます。 相対強度値は、互いに特定の関係にある反対の名前の絶対値を比較することによって計算され、他のタイプの相対値とは異なり、通常は数値と呼ばれ、比率がその絶対値の次元を持ちます。彼らは表現します。 ただし、得られた計算結果が小さすぎる場合は、わかりやすくするために 1000 倍または 10 倍して、ppm およびデシミリ単位の特性を取得する場合があります。 特に興味深いのは、さまざまな相対強度値、つまり一人当たりの国内総生産です。 この指標を産業または特定の種類の製品のコンテキストで拡張すると、次の相対強度値を取得できます: 一人当たりの電力、燃料、機械、設備、サービス、商品およびその他の生産。 相対比較値は、同じ期間またはある時点で取得された、異なるオブジェクトまたは領域に関連する同名レベルの比較から生じる相対的な指標です。 また、係数またはパーセンテージで計算され、比較可能な値が別の値よりも何倍大きいか小さいかを示します。 相対比較値は、個々の企業、都市、地域、国のさまざまなパフォーマンス指標の比較評価に広く使用されています。 この場合、たとえば、特定の企業の仕事の結果は比較の基礎として採用され、他の業界、地域、国などの同様の企業の結果と一貫して相関しています。 社会現象の統計的研究では、絶対値と相対値が互いに補完し合います。 いわば絶対値が現象の統計を特徴付ける場合、相対値は現象の発展の程度、ダイナミクス、および強度を研究することを可能にします。 経済分析および統計分析における絶対値および相対値の正しい適用と使用には、次のことが必要です。 1)XNUMXつまたは別のタイプの絶対値および相対値を選択して計算するときに、現象の詳細を考慮します(これらの値によって特徴付けられる現象の量的側面は、それらの質的側面と密接に関連しているため)。 2)それらが表す現象の量と構成、絶対値自体を取得する方法の正確さに関して、比較された絶対値と基本的な絶対値の比較可能性を確保する。 3)分析プロセスでの相対値と絶対値の複雑な使用、およびそれらを互いに分離しない(絶対値から分離して相対値を単独で使用すると、不正確で誤った結論につながる可能性があるため)。 講義№5。 平均値と変動の指標 1.平均値とその計算の一般原則 平均値は、さまざまな属性の多数の個々の値に基づいて構築されるため、大衆社会現象の要約(最終)特性を与える一般化統計指標を指します。 平均値の本質を明確にするために、それらの現象の兆候の値の形成の特徴を考慮する必要があり、それに従って平均値が計算されます。 各質量現象の単位には多くの特徴があることが知られています。 これらの兆候のどちらが取られても、個々のユニットの値は異なります、それらは変化します、または統計で言うように、ユニットごとに異なります。 したがって、たとえば、従業員の給与は、その資格、仕事の性質、勤続年数、およびその他の多くの要因によって決定されるため、非常に広範囲にわたって変動します。 すべての要因の累積的な影響により、各従業員の収益額が決まります。 それにもかかわらず、経済のさまざまなセクターの労働者の平均月収について話すことができます。 ここでは、大規模な母集団の単位を参照する、変数属性の典型的な特性値を使用して操作します。 平均値は、調査された母集団のすべての単位に特徴的な一般を反映しています。 同時に、人口の個々のユニットの属性の大きさに作用するすべての要因の影響を、相互にキャンセルするかのようにバランスさせます。 社会現象のレベル (またはサイズ) は、XNUMX つのグループの要因の作用によって決まります。 それらのいくつかは、一般的で主要なものであり、常に機能しており、調査中の現象またはプロセスの性質に密接に関連しており、調査対象の母集団のすべてのユニットに典型的な形をしており、平均値に反映されています。 他の人は個人的で、その行動はそれほど目立たず、エピソード的でランダムです. それらは反対方向に作用し、集団の個々のユニットの量的特性の間に違いを引き起こし、研究されている特性の一定値を変更しようとします。 個々の兆候のアクションは、平均値で消滅します。 特徴を一般化する際にバランスがとれ相互に相殺される典型的要因と個別要因の累積的な影響の中で、数学的統計学から知られている大数の基本法則が一般的な形で表されます。 全体として、記号の個々の値は共通の塊にマージされ、いわば溶解します。 したがって、平均は「非個人的な」値として機能し、特徴の個々の値から逸脱する可能性があり、それらのいずれとも定量的に一致しません。 したがって、平均は、その値が、いわば、すべての原因。 ただし、平均がフィーチャの最も典型的な値を反映するためには、母集団に対して決定するのではなく、定性的に均一な単位で構成される母集団に対してのみ決定する必要があります。 この要件は、科学に基づく平均の適用の主な条件であり、社会経済現象の分析における平均の方法とグループ化の方法との密接な関係を意味します。 その結果、 平均値 -これは、場所と時間の特定の条件における均一な集団の単位あたりの可変形質の典型的なレベルを特徴付ける一般的な指標です。 このように平均の本質を定義すると、平均を正しく計算することは、次の要件を満たすことを意味することを強調する必要があります。 1)平均が計算される母集団の質的均一性。 さまざまな品質の現象(さまざまなタイプ)の平均の計算は、そのような現象の発生が一般的ではなく異なる法律や原因の影響を受けるため、平均の本質と矛盾します。 これは、平均値の計算がグループ化方法に基づいている必要があることを意味します。これにより、均質で同じタイプの現象を確実に選択できます。 2)ランダムで純粋に個人的な原因と要因の平均値の計算への影響の除外。 これは、平均の計算が、大数の法則の作用が明らかになる十分に大規模な材料に基づいている場合に達成され、すべての事故が互いに相殺されます。 3) 平均値を計算するときは、その計算の目的と、それが方向付けられるべきいわゆる定義指標 (プロパティ) を確立することが重要です。 決定指標は、平均化された機能の値の合計、その逆数の合計、その値の積などとして機能できます。定義指標と平均の関係は次のように表されます。平均化された機能の は、それらの平均値に置き換えられます。この場合、合計または積であり、定義指標は変更されません。 この決定指標と平均値との関係に基づいて、平均値を直接計算するための初期量的比率が構築されます。 統計母集団の特性を維持する平均の能力は、定義特性と呼ばれます。 母集団全体について計算された平均は一般平均と呼ばれ、グループごとに計算された平均はグループ平均と呼ばれます。 一般的な平均は、調査中の現象の一般的な特徴を反映し、グループの平均は、このグループの特定の条件下で発生する現象のサイズの特徴を示します。 計算方法は異なる場合があり、これに関連して、統計ではいくつかのタイプの平均が区別されます。その主なものは、算術平均、調和平均、および幾何平均です。 経済分析では、平均値の使用は、科学的および技術的進歩、社会的措置の結果を評価し、経済発展のための隠れた未使用の埋蔵量を見つけるための効果的なツールです。 同時に、経済分析や統計分析を行う際に平均に過度に注目すると、偏った結論につながる可能性があることを忘れてはなりません。 これは、一般化指標である平均値が、実際に存在し、独立した関心事である可能性がある母集団の個々のユニットの量的特性の違いを相殺して無視するという事実によるものです。 2. 平均の種類 統計では、さまざまなタイプの平均が使用され、XNUMX つの大きなクラスに分けられます。 1) 電力平均 (調和平均、幾何平均、算術平均、平均二乗、平均三次); 2) 構造平均 (最頻値、中央値)。 累乗平均を計算するには、機能のすべての使用可能な値を使用する必要があります。 最頻値と中央値は、分布の構造によってのみ決定されます。 したがって、それらは構造的位置平均と呼ばれます。 中央値と最頻値は、平均指数の計算が不可能または非現実的な母集団の平均特性としてよく使用されます。 最も一般的なタイプの平均は算術平均です。 算術平均は、特性のすべての値の合計が母集団のすべての単位に均等に分布した場合に、母集団の各単位が持つであろう特性の値です。 一般的な場合、その計算は、変化する特性のすべての値を合計し、その結果の量を母集団内のユニットの総数で割ることになります。 たとえば、5 人の作業者が部品生産の注文を実行し、最初の作業者は 7 つの部品を生産し、4 人目は 10、12 人目は XNUMX、XNUMX 人目は XNUMX、XNUMX 人目は XNUMX 個を生産しました。ソース データでは、それぞれの値がこのオプションは XNUMX 人のワーカーの平均出力を決定するために XNUMX 回だけ使用されるため、単純な算術平均の式を適用する必要があります。  つまり、この例では、XNUMX 人の労働者の平均出力  単純な算術平均とともに、加重算術平均が検討されます。 たとえば、20 歳から 18 歳までの 22 人の学生グループの学生の平均年齢を計算してみましょう。ここで、x はi - 平均化された機能のバリアント f - 母集団で i 番目の値が何回発生するかを示す頻度。 加重算術平均式を適用すると、次のようになります。 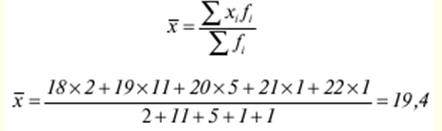 加重算術平均を選択するための特定のルールがあります。相互に関連するXNUMXつの指標に一連のデータがあり、そのうちのXNUMXつについて平均値を計算する必要があり、同時に分母の数値を計算する必要がある場合その論理式の値は既知であり、分子の値は不明ですが、これらの指標の積として見つけることができます。平均値は算術加重平均の式に従って計算する必要があります。 場合によっては、初期統計データの性質により、算術平均の計算が意味を失い、唯一の一般化指標が別のタイプの平均、つまり調和平均のみになることがあります。 現在、電子計算技術の広範な導入により、算術平均の計算上の特性は、一般的な統計指標の計算における関連性を失っています。 調和平均値は単純化して重み付けすることもできるため、実用上非常に重要です。 論理式の分子の数値がわかっているが、分母の値がわからない場合、調和加重平均公式を使用して平均値が計算されます。 もし、すべてのオプションの平均調和重みを使用する場合 (f;) が等しい場合、重み付けされたものの代わりに、単純な (重み付けされていない) 調和平均を使用できます。  どこで x - 個々のオプション; n は、平均化された機能のバリアントの数です。 たとえば、異なる速度で移動するパスのセグメントが等しい場合、単純な調和平均を速度に適用できます。 平均値は、平均化された機能の各バリアントを置き換えるときに、平均化された指標に関連付けられている最終的な一般化指標の値が変化しないように計算する必要があります。 したがって、パスの個々のセクションの実際の速度をそれらの平均値に置き換える場合、平均速度によって合計距離が変わることはありません。 平均式は、この最終指標と平均との関係の性質 (メカニズム) によって決定されます。 したがって、オプションが平均値に置き換えられたときに値が変化しない最終的な指標は、定義指標と呼ばれます。 平均式を導き出すには、平均化された指標と決定指標との関係を使用して方程式を作成し、解く必要があります。 この方程式は、平均化された機能 (インジケーター) のバリアントをそれらの平均値に置き換えることによって作成されます。 算術平均と調和平均に加えて、他のタイプ (形式) の平均も統計で使用されます。 それらはすべてベキ平均の特殊なケースです。 同じデータに対してすべてのタイプのべき乗平均を計算すると、それらの値は同じになることがわかります。ここでは、平均の大多数の規則が適用されます。 平均の指数が増加すると、平均自体も増加します。 n個の成長因子がある場合は幾何平均が使用されますが、属性の個々の値は、原則として、ダイナミクスの相対値であり、前のレベルとの比率としてチェーン値の形式で構築されますダイナミクスシリーズの各レベル。 したがって、平均は平均成長率を特徴付けます。 幾何単純平均は、次の式で計算されます。  幾何加重平均の式は次のとおりです。  上記の式は同じですが、XNUMXつは現在の係数または成長率に適用され、XNUMXつ目はシリーズのレベルの絶対値に適用されます。 二乗平均平方根は、二乗関数の値を使用して計算するときに使用されます。これは、分布系列の算術平均付近の特性の個々の値の変動の程度を測定するために使用され、次の式で計算されます。 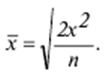 加重二乗平均平方根は、次の式を使用して計算されます。  平均キュービックは、キュービック関数の値で計算するときに使用され、次の式で計算されます。  および平均立方加重: 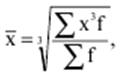 上記の平均値はすべて、一般式として表すことができます。 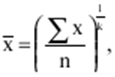 ここで、x は平均値です。 x - 個々の値; n は、調査対象の母集団の単位数です。 k - 平均のタイプを決定する指数。 同じ初期データを使用した場合、一般的なべき乗平均式で k が多いほど、平均値が大きくなります。 このことから、電力手段の値の間に規則的な関係があることがわかります。  上記の平均値は、研究対象の母集団についての一般的な考え方を示しており、この観点から、その理論的、応用的、教育的重要性には議論の余地がありません。 ただし、平均値が実際に存在するオプションのいずれとも一致しない場合があります。 したがって、統計分析では、考慮された平均に加えて、順序付けされた (ランク付けされた) 一連の属性値の中で非常に特定の位置を占める特定のオプションの値を使用することをお勧めします。 このような量の中で最も一般的に使用されるのは、構造的 (または記述的) 平均、つまりモード (Mo) と中央値 (Me) です。 ファッション - この母集団で最も頻繁に見られる形質の値。 変分系列に関して、モードは、ランク付けされた系列の最も頻繁に発生する値、つまり、最も頻度の高いバリアントです。 ファッションは、最も訪問された店舗、つまりあらゆる製品の最も一般的な価格を決定するために使用できます。 これは、母集団の大部分に特徴的なフィーチャのサイズを示し、次の式によって決定されます。 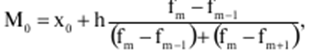 ここでx0 - 間隔の下限; h は間隔の値です。 fm- 間隔頻度; fm1-前の間隔の頻度。 fm + 1- 次の間隔の頻度。 中央値 ランク付けされた行の中央にあるオプションが呼び出されます。 中央値は、その両側に同じ数の人口単位が存在するように、系列を XNUMX つの等しい部分に分割します。 この場合、母集団のユニットの半分は中央値より小さい変動特性の値を持ち、残りの半分は中央値より大きい値を持ちます。 中央値は、値が分布系列の要素の半分以上であるか、またはそれ以下である要素を調査するときに使用されます。 中央値は、属性値がどこに集中しているか、つまりその中心がどこにあるかについての一般的なアイデアを与えます。 中央値の記述的な性質は、人口単位の半分が所有するさまざまな属性の値の量的境界を特徴付けるという事実に現れています。 離散変分系列の中央値を見つける問題は簡単に解決されます。 シリーズのすべてのユニットにシリアル番号が与えられている場合、メジアン バリアントのシリアル番号は (n + 1) / 2 として定義され、メンバーの数は奇数 n です。シリーズのメンバーの数が偶数の場合、中央値は、シリアル番号 n / 2 および n/2 + 1 を持つ XNUMX つのバリアントの平均になります。 間隔変動系列の中央値を決定する場合、それが位置する間隔 (中央値間隔) が最初に決定されます。 この間隔は、累積された頻度の合計が、系列のすべての頻度の合計の半分以上であるという事実によって特徴付けられます。 間隔変動シリーズの中央値の計算は、次の式に従って実行されます。  ここでx0 - 間隔の下限; h は間隔の値です。 fm- 間隔頻度; f は系列のメンバーの数です。 ∫ m -1 - このシリーズに先行するシリーズの累積メンバーの合計。 研究対象の母集団の構造をより完全に特徴付けるために、中央値に加えて、ランク付けされたシリーズ内で非常に特定の位置を占めるオプションの他の値も使用されます。 これらには、四分位数と十分位数が含まれます。 四分位数は頻度の合計によって系列を XNUMX つの等しい部分に分割し、十分位数は XNUMX つの等しい部分に分割します。 XNUMX つの四分位数と XNUMX つの十分位数があります。 中央値と最頻値は、算術平均とは対照的に、変数属性の値の個人差を相殺しないため、統計母集団の追加の非常に重要な特性です。 実際には、平均値の代わりに、または平均値と一緒に使用されることがよくあります。 調査対象の母集団に変数属性の値が非常に大きいまたは非常に小さい特定の数のユニットが含まれている場合、中央値と最頻値を計算すると特に便利です。 母集団にとってあまり特徴的ではないオプションのこれらの値は、算術平均に影響を与えますが、中央値とモードの値には影響しません。これにより、後者は経済的および統計的分析にとって非常に価値のある指標になります。 3. 変動指標 統計調査の目的は、調査対象の統計母集団の基本的な特性とパターンを特定することです。 統計観測データを集計処理する過程で、分布系列が構築されます。 分布系列には、グループ化の基礎としてとられる特性が定性的であるか定量的であるかに応じて、帰属的と変分的の XNUMX つのタイプがあります。 変分分布シリーズと呼ばれ、定量ベースで構築されます。 母集団の個々の単位における量的特性の値は一定ではなく、多かれ少なかれ互いに異なります。 形質の大きさのこの違いは、バリエーションと呼ばれます。 調査対象の母集団で発生する特徴の個別の数値は、値バリアントと呼ばれます。 個体群の個々の単位にばらつきがあるのは、形質レベルの形成に対する多数の要因の影響によるものです。 母集団の個々の単位における兆候の性質と変動の程度の研究は、あらゆる統計研究の最も重要な問題です。 変動指標は、形質の変動性の尺度を記述するために使用されます。 統計研究のもうXNUMXつの重要なタスクは、母集団の特定の特徴の変動における個々の要因またはそれらのグループの役割を決定することです。 統計におけるこのような問題を解決するために、変動を測定する指標のシステムの使用に基づいて、変動を研究するための特別な方法が使用されます。 実際には、研究者は属性の値に対して十分な数のオプションに直面していますが、これは集計内の属性の値に応じた単位の分布についての考えを与えません。 これを行うために、属性値のすべてのバリアントが昇順または降順で配置されます。 このプロセスはシリーズランキングと呼ばれます。 ランク付けされたシリーズは、機能が集約で取る値の一般的なアイデアを即座に提供します。 母集団の徹底的な特性評価のための平均値の不十分さは、調査中の特性の変動(変動)を測定することによってこれらの平均の典型性を評価することを可能にする指標で平均値を補足する必要があります。 これらの変動の指標を使用することで、統計分析をより完全で意味のあるものにすることができ、したがって、研究された社会現象の本質をよりよく理解することができます。 変動の最も単純な兆候は最小と最大です。これは、集合体の特徴の最小値と最大値です。 特徴値の個々のバリアントの繰り返しの数は、繰り返しの頻度と呼ばれます。 度数 - 単位の分数またはパーセンテージで表すことができる度数の相対指標で、変動シリーズを異なる数の観測値と比較できます。 正式には次のとおりです。 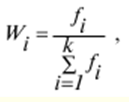 ここでfi - オプションの数。 特性の変動を測定するために、さまざまな絶対的および相対的な指標が使用されます。 変動の絶対指標には、平均線形偏差、変動範囲、分散、標準偏差が含まれます。 変動範囲 (R) は、調査対象の母集団における形質の最大値と最小値の差です。正式には、次のようになります。 R=Xマックス- NS分 この指標は、オプションの制限値の違いのみを示すため、調査中の特性の変動の最も一般的なアイデアのみを提供します。 これは、変動シリーズの頻度、つまり分布の性質とはまったく関係がなく、属性の極値のみに依存するため、不安定でランダムな特性になる可能性があります。 変動の範囲は、調査された母集団の特徴に関する情報を提供せず、得られた平均の典型性の程度を評価することを許可しません。 この指標の範囲は、かなり均質な母集団に限定されています。 特性の変動をより正確に特徴付けるのは、特性のすべての値の変動性を考慮した指標です。 特性の変動を特徴付けるには、調査中の母集団の典型的な値からのこれらすべての値の偏差を一般化できなければなりません。 平均線形偏差、分散、標準偏差などの変動指標は、算術平均からの個々の人口単位の属性の値の偏差の考慮に基づいています。 平均直線偏差 算術平均からの個々のオプションの偏差の絶対値の算術平均です。  ここで、d は平均線形偏差です。 |x−x| - 算術平均からのバリアントの偏差の絶対値 (モジュラス); f - 周波数。 最初の式は、各オプションが集計で XNUMX 回だけ発生する場合に適用され、XNUMX 番目の式は頻度が等しくない場合に適用されます。 算術平均からのオプションの偏差を平均する別の方法があります。 統計におけるこの非常に一般的な方法は、結局のところ、平均からのオプションの二乗偏差を計算し、それらを平均することになります。 この場合、変動の新しい指標である分散が得られます。 分散 (σ2) - 特性値のバリアントの平均値からの二乗偏差の平均: 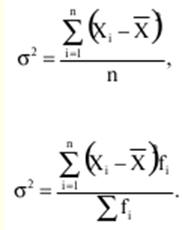 XNUMX 番目の式は、バリアントに独自の重み (または変動シリーズの度数) がある場合に使用されます。 経済分析および統計分析では、標準偏差を使用して属性の変動を評価するのが通例です。 標準偏差 (σ) は分散の平方根です。  平均線形偏差と平均二乗偏差は、属性の値が調査中の母集団の単位で平均してどれだけ変動するかを示し、バリアントと同じ単位で表されます。 統計の実践では、さまざまな特徴の変動を比較することがしばしば必要になります。 たとえば、従業員の年齢と資格、勤続年数と賃金などの変動を比較することは非常に興味深いことです。不適切です。 実際、年数で表される労働経験の変動を、ルーブルやコペックで表される賃金の変動と比較することは不可能です。 集合体のさまざまな特性の変動性を比較する場合、変動の相対的な指標を使用すると便利です。 これらの指標は、算術平均(または中央値)に対する絶対指標の比率として計算されます。 変動の絶対的な指標として、変動の範囲、平均線形偏差、標準偏差を使用して、変動の相対的な指標を取得します。  変動係数は、母集団の均一性を特徴付ける、相対的なボラティリティの最も一般的に使用される指標です。 正規分布に近い分布で変動係数が 33% を超えない場合、セットは均一であると見なされます。 講義№6。 選択的観察 1. 選択的観察の一般的な概念 統計的観測は、連続および非連続として編成できます。 継続的とは、現象の調査対象集団のすべてのユニットの調査を含み、非継続的であり、その部分のみを調査します。 選択的観察も不連続に属します。 サンプル観察は、部分観察の中でも最も広く使用されているタイプの XNUMX つです。 この観察は、研究者の関心のある特性に従って、ランダムに選択されたユニットの特定の部分が研究対象の現象の母集団全体を表すことができるという考えに基づいています。 標本観察の目的は、主に調査対象の母集団全体の一般的な特徴の概要を判断するための情報を取得することです。 選択的観測はその目的の観点から言えば、継続的観測のタスクの XNUMX つと一致するため、XNUMX 種類の観測 (連続的観測と選択的観測) のどちらを実施するのがより適切であるかについて議論することができます。 この問題を解決するには、次の統計的観測の基本要件から進める必要があります。 1) 情報は信頼できるものでなければなりません。つまり、可能な限り現実に対応している必要があります。 2) 情報は、研究の問題を解決するのに十分なほど完全でなければなりません。 3) 情報の選択は、運用目的での使用を確実にするために、できるだけ早く実行する必要があります。 4) 組織化と実施のための金銭的および人件費は最小限に抑える必要があります。 選択的な観察では、これらの要件は連続的な観察よりも大幅に満たされます。 連続観察と比較した場合の選択的観察の利点は、サンプリング方法の理論の科学的原則に厳密に従って組織化され実行される場合に十分に理解できます。 このような原則は、ユニットの選択のランダム性と十分な数を確保することです。 原則を遵守することで、研究者の関心のある特徴に応じて、研究されたセット全体を表す、つまり代表的なユニットのセットを取得することが可能になります。 標本観察を行う場合、研究対象のすべての単位が検査されるわけではありません。つまり、一般集団のすべての単位ではなく、特別に選択されたその一部のみが検査されます。 選択の最初の原則 (ランダム性の確保) は、研究対象の母集団の各単位を選択する際に、サンプルに含まれる平等な機会が提供されることです。 ランダム選択はランダム選択ではありません。 ランダムな選択は、特定の方法論 (たとえば、ロットを選択する、乱数のテーブルを使用するなど) に従った場合にのみ保証されます。 選択のXNUMX番目の原則(十分な数の選択されたユニットを確保する)は、サンプルの代表性の概念と密接に関連しています。 選択されたユニットのセットの代表性の概念は、すべての点で、つまり調査対象集団のすべての点での代表性として理解されるべきではありません。 そのような表現を提供することはほとんど不可能です。 サンプルの観察は、特定の目的で実行され、特定のタスクが明確に定式化されています。代表性の概念は、調査の目的と目的に関連付ける必要があります。 調査対象の母集団全体から選択された部分は、まず、調査中の機能、または要約一般化特性の形成に大きな影響を与える機能に関して、代表的なものである必要があります。 選択的観測で使用されるいくつかの概念を紹介しましょう。 一般人口 研究されたユニットのセット全体が呼び出され、研究者にとって関心のある特性に従って研究の対象となります。 サンプリングセット 一般集団からランダムに選択されたその一部が呼び出されます。 このサンプルは、代表性の要件の対象となります。これは、一般集団の一部のみを調査することによって、調査結果を全集団に拡張する可能性を意味します。 一般母集団とサンプル母集団の特性は、調査対象の特徴の平均値、それらの分散と標準偏差、最頻値と中央値などです。 研究者はまた、一般集団および標本集団で研究中の特性に応じた単位の分布に興味があるかもしれません。 この場合、周波数はそれぞれ一般周波数およびサンプル周波数と呼ばれます。 調査中の母集団の単位を特徴付ける選択規則と方法のシステムは、サンプリング方法の内容を構成します。 サンプリング方法の本質は、調査中の現象に関する信頼できる情報を取得するために、サンプルを観察し、一般化、分析、および人口全体への配布を行うことによって実行される一次データを取得することです。 サンプルの代表性は、サンプル内の母集団内のオブジェクトのランダム選択の原則を遵守することによって保証されます。 母集団が定性的に均一である場合、ランダム性の原則は、サンプル オブジェクトの単純なランダム選択によって実装されます。 単純な無作為選択は、特定のサイズの任意のサンプルについて、観察のために選択される母集団の各ユニットに対して同じ確率を提供するサンプリング手順です。 したがって、サンプリング法の目的は、この母集団からの無作為標本からの情報に基づいて、一般母集団の特徴の意味について結論を引き出すことです。 2. サンプリング エラー サンプル母集団の特性と一般母集団の特性の間には、原則として、統計的観測の誤差と呼ばれるいくつかの不一致があります。 質量観測中、エラーは避けられませんが、さまざまな理由の結果として発生します。 サンプル属性の可能なエラーの値は、登録エラーと代表性エラーで構成されます。 登録エラーまたは技術エラーは、オブザーバーの資格不足、不正確な計算、機器の不完全性などに関連しています。 下に 代表性(代表)エラー サンプル特性と一般母集団の推定特性との不一致を理解する。 代表性エラーは、ランダムまたは系統的である可能性があります。 系統的エラーは、確立された選択規則の違反に関連しています。 確率的誤差は、一般母集団の単位のさまざまなカテゴリのサンプル セットにおける不十分な一様表現によって説明されます。 最初の理由の結果として、各ユニットの選択でエラーが発生し、常に同じ方向に向けられるため、サンプルが偏りやすいことが判明する可能性があります。 この誤差はオフセット誤差と呼ばれます。 そのサイズは、ランダム エラーの値を超える場合があります。 バイアス誤差の特徴は、代表性誤差の一定の部分であり、サンプルサイズとともに増加することです。 サンプルサイズが大きくなるにつれて、確率誤差は減少します。 さらに、ランダム誤差の大きさを決定することができますが、バイアス誤差の大きさを実際に直接決定することは非常に困難であり、場合によっては不可能です。 したがって、オフセット誤差の原因を知り、それを解消するための対策を講じることが重要です。 バイアス エラーは、意図的または非意図的のいずれかです。 意図的なエラーの理由は、一般集団からのユニットの選択に対する偏ったアプローチです。 このようなエラーの発生を防ぐために、ユニットのランダム選択の原則を守る必要があります。 意図しないエラーは、サンプル観測の準備、サンプル母集団の形成、およびそのデータの分析の段階で発生する可能性があります。 このようなエラーを回避するには、適切なサンプリングフレーム、つまり、サンプリングユニットのリストなど、選択対象の母集団が必要です。 サンプリングフレームは、信頼性が高く、完全で、調査の目的と一致している必要があり、サンプリングユニットとその特性は、サンプル観察が準備されたときの実際の状態に対応している必要があります。 サンプル中の一部のユニットは、観察時に存在しない、情報を提供することを望まないなどの理由で情報を収集するのが難しいことは珍しくありません。そのような場合、これらのユニットは他のユニットと交換する必要があります。 交換は同等のユニットで行われるようにする必要があります。 ランダムサンプリングエラーは、サンプル内のユニットと一般母集団のユニットとの間のランダムな違いの結果として発生します。つまり、ランダムな選択に関連付けられています。 ランダムサンプリングエラーの出現の理論的正当化は、確率論とその極限定理です。 極限定理の本質は、質量現象において、規則性と一般化特性の形成に対するさまざまなランダムな原因の累積的な影響が任意に小さい値になるか、実際にはケースに依存しないということです。 ランダムサンプリングエラーは、サンプルの単位と一般母集団の間のランダムな違いの結果として発生するため、サンプルサイズが十分に大きい場合、任意に小さくなります。 確率論の極限定理により、ランダムサンプリングエラーのサイズを決定できます。 平均(標準)と限界サンプリングエラーを区別します。 下 平均(標準)誤差 サンプリングとは、サンプルの平均と母集団の平均との不一致を指します。 限界誤差 サンプルとして、考えられる最大の不一致、つまり、特定の発生確率に対する最大のエラーを考慮するのが通例です。 サンプリング法の数学的理論では、サンプルと一般母集団の特性の平均特性が比較され、サンプルサイズの増加に伴い、大きなエラーの確率と最大可能エラーの限界が証明されます下降。 より多くのユニットが調査されるほど、サンプルと一般的な特性の間の差異は小さくなります。 P. L. Chebyshev によって証明された定理に基づいて、十分に大きなサンプル サイズ (n) を持つ単純な無作為サンプルの標準誤差の値は、次の式で決定できます。 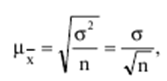 ここで、μxは標準誤差です。 単純無作為標本の平均 (標準) 誤差のこの式から、値 µx は、一般集団における形質の変動性 (形質の変動が大きいほど、サンプリング誤差が大きくなる) に依存し、サンプル サイズ n によっては、調査される単位が多いほど、サンプルと一般的な特性の間の不一致が小さくなります)。 . 学者の A. M. リアプノフは、十分に大きなサイズのランダム サンプリング エラーの発生確率が正規分布の法則に従うことを証明しました。 この確率は、次の式によって決定されます。  数学的統計では、信頼係数 t が使用され、関数 F(t) の値がそのさまざまな値について表にされ、対応する信頼レベルが取得されます。 信頼係数を使用すると、次の式で計算される限界サンプリング誤差を計算できます。 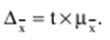 式から、限界サンプリング エラーは、平均サンプリング エラーの数の - 倍に等しいことがわかります。 したがって、限界サンプリング誤差値は一定の確率で設定することができます。 サンプル観察により、サンプルの算術平均を決定できます x そしてこの平均の限界誤差 Δx、一定の確率で示されます)サンプルが一般的な平均とどれだけ上下するかを示します。 次に、一般的な平均の値は、下限が次のようになる区間推定値によって表されます。  推定されたパラメータの未知の値が一定の確率で囲まれる区間を信頼区間と呼び、確率 P を信頼確率と呼びます。 ほとんどの場合、信頼確率は 0,95 または 0,99 に等しくなり、信頼係数 t はそれぞれ 1,96 および 2,58 に等しくなります。 これは、信頼区間に特定の確率の一般平均が含まれていることを意味します。 限界サンプリング誤差の絶対値とともに、相対サンプリング誤差も計算されます。これは、サンプリング母集団の対応する特性に対する限界サンプリング誤差のパーセンテージとして定義されます。 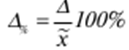 限界サンプリング誤差の値が大きいほど、信頼区間の値が大きくなり、その結果、推定の精度が低下します。 サンプルの平均 (標準) エラーは、サンプル サイズと、一般母集団における特性の変動の程度によって異なります。 3. 必要なサンプルサイズの決定 サンプリング理論の科学的原則の XNUMX つは、十分な数の単位が選択されるようにすることです。 理論的には、この原則に準拠する必要性は、確率論の極限定理の証明に示されています。これにより、一般母集団から選択するユニットの数を確立して、サンプルの代表性を十分に確保することができます。 サンプルの標準誤差の減少 (したがって推定の精度の増加) は、常にサンプル サイズの増加に関連付けられています。 したがって、サンプル観測を組織する段階で、必要な観測結果の精度を確保するために、サンプルのサイズを決定する必要があります。 必要なサンプル サイズの計算は、XNUMX つまたは別のタイプおよび選択方法に対応する限界サンプリング エラー (Δ) の式から導出された式を使用して作成されます。 したがって、ランダムに繰り返されるサンプル サイズ (n) の場合、次のようになります。 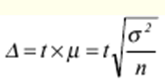  この式の意味は、必要な数をランダムに再選択する場合、サンプル サイズは信頼係数の XNUMX 乗 (t2) と変動特徴の分散 (σ2) であり、限界サンプリング誤差 (∆) の XNUMX 乗に反比例します。2)。 特に、最大誤差が 2 倍に増加すると、必要なサンプル サイズを 4 分の 10 に減らすことができます。 XNUMX つのパラメータのうち、XNUMX つ (t と Δ) は研究者によって設定されます。 この場合、研究者はサンプル調査の目的と目的に基づいて、最適な選択肢を確保するためにこれらのパラメータをどのような定量的な組み合わせで含めるのがより良いかを決定する必要があります。 ある場合には、精度の尺度(Δ)よりも得られた結果の信頼性(t)に満足する場合もあれば、その逆の場合もあります。 最大サンプリング誤差の大きさに関する問題を解決することは、研究者がサンプル観察を設計する段階でこの指標を持っていないため、さらに困難になります。 したがって、実際には、最大サンプリング誤差の値を、通常は属性の予想平均レベルの XNUMX% 以内に設定するのが通例です。 推定平均値の確立には、以前の同様の調査からのデータを使用するか、サンプリング フレームからのデータを使用して小規模なパイロット サンプルを実施するなど、さまざまな方法でアプローチできます。 必要なサンプル サイズを決定する問題は、サンプル調査がサンプリング ユニットのいくつかの特徴の調査を含む場合、より複雑になります。 この場合、各特性の平均レベルとその変動は原則として異なるため、目的と目的のみを考慮して、どの特性のどの分散を優先するかを決定できます。調査。 サンプル観測を設計するとき、許容サンプリング誤差の所定の値は、特定の研究の目的および観測結果に基づく結論の確率に従って仮定されます。 一般に、サンプル平均の限界誤差の式により、次の問題を解決できます。 1) サンプル母集団の指標からの一般母集団の指標の可能な偏差の大きさを決定する。 2) 必要なサンプルサイズを決定し、必要な精度を提供します。この場合、起こり得るエラーの限界は、特定の所定の値を超えません。 3) サンプルのエラーが特定の限界を持つ確率を決定します。 4. サンプリングの選択方法と種類 サンプリング方法の理論では、代表性を確保するために、さまざまな選択方法とサンプリングの種類が開発されています。 下 選考方法 一般集団から単位を選択する手順を理解する。 選択には、繰り返しと非繰り返しの XNUMX つの方法があります。 リサンプリングでは、調査後にランダムに選択された各ユニットが一般母集団に戻され、その後の選択で再びサンプルに分類される場合があります。 この選択方法は、「返球」方式に従って構築されています。 この選択方法では、選択されたユニットの数に関係なく、一般母集団の各ユニットのサンプルに入る確率は変わりません。 非反復選択では、ランダムに選択された各ユニットは、検査後に一般集団に戻されません。 この選択方法は、「返されなかったボール」スキームに従って構築されています。 選択が行われるにつれて、母集団の各ユニットが選択される確率が増加します。 サンプリング方法に応じて、次の主な種類のサンプリングが区別されます。実際には、ランダム、機械的、典型的 (階層化、地域化)、シリアル (ネスト)、結合、多段階、多段階、相互侵入。 実際の無作為サンプルは、科学的原理と無作為選択の規則に厳密に従って作成されます。 真にランダムなサンプルを取得するには、一般母集団をサンプリング単位に厳密に分割し、十分な数の単位をランダムな繰り返しまたは非繰り返しの順序で選択します。 ランダム注文とは、抽選に相当する注文です。 実際には、この順序は特別な乱数テーブルを使用することで最もよく実現されます。 たとえば、1587 ユニットを含む母集団から 40 ユニットを選択する場合、40 未満の 1587 個の XNUMX 桁の数字がテーブルから選択されます。 非反復選択法では、標準誤差の計算は次の式を使用して実行されます。 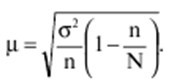
この比率は常に XNUMX 未満であるため、非反復選択のエラーは、他の条件が等しい場合、反復選択のエラーよりも常に小さくなります。 非反復選択は、反復選択よりも編成が容易であり、より頻繁に使用されます。 乱数表を使用する場合、一般集団のすべての単位に番号を付ける必要があるため、ランダム選択の規則に厳密に従ってサンプルを作成することは、実際には非常に困難であり、不可能な場合もあります。 多くの場合、人口が非常に多いため、このような予備作業を行うことは非常に困難で非現実的です。 したがって、実際には、他のタイプのサンプルが使用されますが、それぞれが厳密にランダムではありません。 ただし、ランダム選択の条件への最大の近似が保証されるように編成されています。 純粋に機械的なサンプルでは、まずユニットの全母集団を選択ユニットのリストの形で提示し、研究中の特性に関して中立的な順序で、たとえばアルファベット順にコンパイルする必要があります。 次に、サンプリング単位のリストは、単位の選択に必要な数の等しい部分に分割されます。 さらに、所定の規則に従って、研究中の形質のバリエーションとは関係なく、リストの各部分から XNUMX つのユニットが選択されます。 このタイプのサンプリングでは、常にランダムな選択が行われるとは限らず、結果のサンプルに偏りが生じる可能性があります。 これは、第一に、一般母集団の単位の順序付けには、非ランダムな性質の要素がある可能性があるという事実によって説明されます。 第二に、母集団の各部分からのサンプリングは、起源が正しく確立されていない場合、バイアス エラーにつながる可能性もあります。 ただし、適切なランダムなサンプルよりも機械的なサンプルを整理する方が実際には簡単であり、このタイプのサンプリングはサンプル調査で最もよく使用されます。 典型的な (ゾーン化され、階層化された) サンプリングには、次の XNUMX つの目標があります。 1) 研究者が関心を持っている特性に応じて、一般集団の対応する典型的なグループがサンプルに含まれていることを確認する。 2) サンプル調査結果の精度を高める。 典型的なサンプルでは、その形成が始まる前に、ユニットの一般集団が典型的なグループに分類されます。 この場合、非常に重要な点は、グループ化特性を正しく選択することです。 選択された典型的なグループには、同じ数の選択単位が含まれていても、異なる数の選択単位が含まれていてもよい。 前者の場合、サンプル母集団は各グループからの選択の均等な割合で形成され、後者の場合、一般母集団におけるその割合に比例した割合で形成されます。 サンプルが等しい割合の選択で形成された場合、それは本質的に、それぞれが典型的なグループである、より小さな母集団からの真にランダムなサンプルの数と同等になります。 各グループからの選択は、ランダム(繰り返しまたは非繰り返し)または機械的な方法で実行されます。 典型的なサンプル (選択の割合が等しい場合と不等な場合の両方) を使用すると、サンプル内の各典型的なグループを必ず表現する必要があるため、調査対象の特性のグループ間変動が結果の精度に及ぼす影響を排除することができます。人口は確保されている。 標準サンプリング誤差は、合計分散 - σ の値には依存しません。2、およびグループ分散の平均値σi2. グループ分散の平均は常に全分散よりも小さいため、他の条件が等しい場合、一般的なサンプルの標準誤差は、ランダムサンプル自体の標準誤差よりも小さくなります。 典型的なサンプルの標準誤差を決定するときは、次の式が使用されます。 1) 反復選択法: 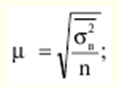 2) 非反復選択方法:  ここで、σв2- サンプル母集団におけるグループ分散の平均。 シリアル (ネスト) サンプリング -これは、調査対象のユニットではなく、ユニットのグループ(シリーズ、ネスト)がランダムに選択される場合のサンプル形成の一種です。 選択したシリーズ (ネスト) 内のすべてのユニットが検査されます。 シリアル サンプリングは、個々のユニットの選択よりも組織化と実施が実質的に簡単です。 ただし、このタイプのサンプリングでは、第一に、各シリーズの代表性が保証されず、第二に、調査結果に対する調査された形質のシリーズ間変動の影響が排除されません。 この変動が大きい場合、ランダムな代表性エラーが増加します。 サンプルの種類を選択するとき、研究者はこの状況を考慮に入れる必要があります。 シリアルサンプリングの標準誤差は、次の式によって決定されます。 1) 反復選択法:  ここで、σв2- サンプル母集団の系列間分散; r-選択されたシリーズの数。 2) 非反復選択方法:  ここで、Rは一般母集団の系列の数です。 実際には、サンプル調査の目的と目的、およびそれらを組織化および実施する可能性に応じて、特定の方法とタイプのサンプリングが使用されます。 ほとんどの場合、サンプリング方法とサンプリングの種類の組み合わせが使用されます。 このようなサンプルは結合と呼ばれます。 組み合わせは、さまざまな組み合わせで可能です: 機械的サンプリングとシリアル サンプリング、典型的サンプリングと機械的サンプリング、シリアル サンプリングとランダム サンプリングなど。組み合わせサンプリングは、調査の組織化と実施にかかる人件費と金銭的コストを最小限に抑えながら、最大の代表性を確保するために使用されます。 結合されたサンプルでは、サンプルの標準誤差の値は、その各ステップでの誤差で構成され、対応するサンプルの誤差の二乗和の平方根として決定できます。 したがって、機械的サンプリングと典型的なサンプリングを複合サンプリングと組み合わせて使用した場合、標準誤差は次の式で決定できます。 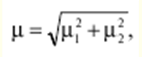 ここで μ1 およびμ2それぞれ、機械的サンプルと典型的なサンプルの標準誤差です。 多段階サンプリングの特徴は、選択の段階に従ってサンプル母集団が徐々に形成されることです。 第1段階では、所定の選択方法および種類の選択を使用して、第1段階ユニットが選択される。 第 XNUMX 段階では、サンプルに含まれる第 XNUMX 段階の各ユニットから、第 XNUMX 段階のユニットが選択されます。段階の数は XNUMX つ以上でも構いません。 最終段階では、サンプル母集団が形成され、その単位が調査の対象となります。 たとえば、家計調査のサンプル調査では、第一段階で国の対象地域を選択し、第二段階で選択した地域の地区を選択し、第三段階で各自治体の企業や団体を選択し、 、最後に、第 XNUMX 段階で、選択された企業から家族が選択されます。 このようにして、サンプリングセットは最終段階で形成される。 多段階サンプリングは、他のタイプよりも柔軟性がありますが、一般に、同じサイズの単一段階サンプルよりも精度の低い結果が得られます。 ただし、同時に、XNUMX つの重要な利点があります。つまり、多段階選択のサンプリング フレームは、サンプル内にあるユニットに対してのみ各段階で構築する必要があるということです。これは非常に重要です。多くの場合、既製のサンプリング フレームはありません。 異なるボリュームのグループを使用した多段階選択でのサンプリングの標準誤差は、次の式によって決定されます。 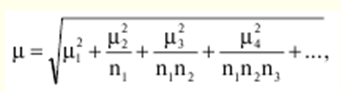 ここで μ1、μ2、μ3,… - さまざまな段階での標準誤差。 n1、n2、n3,… - 対応する選択段階でのサンプル数。 グループのサイズが同じでない場合、理論的にはこの式は使用できません。 しかし、すべての段階で選択の合計割合が一定である場合、実際には、この式による計算はエラーの歪みにつながりません。 多段階サンプリングの本質は、最初に形成されたサンプル母集団に基づいて、このサブサンプルから次のサブサンプルなどのサブサンプルが形成されることです。最初のサンプル母集団は最初の段階を表し、そこからのサブサンプルは XNUMX 番目などを表します。多相サンプリング 次のような場合に使用することをお勧めします。 1) さまざまな機能を調べるために不均等なサンプル サイズが必要な場合。 2) 調査対象の特徴の変動が同じではなく、必要な精度が異なる場合。 3) 初期サンプル母集団 (第 XNUMX フェーズ) のすべてのユニットに関してはあまり詳細ではない情報を収集する必要がある場合、後続の各フェーズのユニットに関してはより詳細な情報を収集する必要がある場合。 マルチフェーズ サンプリングの疑いのない利点の XNUMX つは、最初のフェーズで取得した情報を後続のフェーズの追加情報として使用できること、第 XNUMX フェーズの情報を後続のフェーズの追加情報として使用できることなどです。このような情報の使用が増加します。サンプル調査の結果の正確さ。 多段階サンプリングを編成する場合、さまざまな方法と選択の種類を組み合わせて使用できます (機械的サンプリングによる典型的なサンプリングなど)。 マルチフェーズ選択はマルチステージと組み合わせることができます。 各段階で、サンプリングは多段階にすることができます。 多相サンプルの標準誤差は、そのサンプルが形成された助けを借りて、選択方法とサンプルの種類の式に従って、各相について個別に計算されます。 相互貫入サンプルは、同じ一般集団からのXNUMXつ以上の独立したサンプルであり、同じ方法とタイプで形成されます。 短時間でサンプル調査の予備結果を取得する必要がある場合は、相互貫入サンプルを使用することをお勧めします。 相互貫入サンプルは、調査結果の評価に効果的です。 結果が独立したサンプルで同じである場合、これはサンプル調査データの信頼性を示しています。 相互貫入サンプルは、各研究者に異なるサンプル調査を実施させることにより、異なる研究者の作業をテストするために使用できる場合があります。 相互貫入サンプルの標準誤差は、通常の比例サンプリングと同じ方法で定義されます。 相互侵入サンプルは、他のタイプよりも多くの労力と費用を必要とするため、研究者はサンプル調査を設計する際にこれを考慮に入れる必要があります。 さまざまな選択方法とサンプリングの種類の限界誤差は、次の式によって決定されます。 Δ = tμ、 ここで、μ は対応する標準誤差です。 講義№7。 指数分析 1。 インデックスの一般的な概念とインデックス方法 統計の実践では、指数は平均とともに、最も一般的な統計指標です。 彼らの助けを借りて、国民経済全体とその個々のセクターの発展が特徴付けられ、最も重要な経済指標の形成における個々の要因の役割が研究されています。 指標は、経済指標の国際比較、生活水準の決定、経済における事業活動の監視などにも使用されます。 インデックス (lat. Index) は、特定の条件下で調査された現象のレベルが、他の条件下での同じ現象のレベルと何倍異なるかを示す相対値です。 条件の違いは、時間 (ダイナミクスのインデックス)、空間 (領域インデックス)、および比較の基礎としての条件付きレベルの選択に現れます。 人口の要素(そのオブジェクト、ユニット、およびそれらの特性)の範囲に応じて、個々の(基本的な)インデックスと要約(複雑な)インデックスが区別され、一般的なインデックスとグループに分けられます。 個別指数 -これは、同じオブジェクトに関連するXNUMXつの指標を比較した結果です。たとえば、製品の価格、販売量などを比較します。企業や業界の活動の統計的および経済的分析では、価格指数など、定性的および定量的指標が広く使用されています。 式によって決定されます: 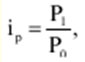 価格指数は、ベースラインと比較したレポート期間中の各タイプの製品の単価の相対的な変化を特徴付けるものであり、定性的な指標です。 物理ボリューム インデックスは、次の式によって決定されます。 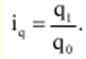 物理量指数は、このタイプの製品の生産が、比較が行われた期間に関連して報告期間中に何回変化したかを示し、定量的な指標です。 複合指数は、人口のいくつかの要素のレベルの比率を特徴づけます(たとえば、異なる天然素材の形態を持ついくつかのタイプの製品の生産量の変化、または労働生産性のレベルの変化いくつかのタイプの製品の生産)。 調査中の母集団が複数のグループで構成されている場合、それぞれが個別のユニットグループのレベルの変化を特徴付ける複合インデックスはグループ(サブインデックス)であり、複合インデックスはユニットの母集団全体をカバーします。 、は一般的な(合計)インデックスです。 複合指数は、複雑な社会経済現象の比率を表し、次のXNUMXつの部分で構成されます。 1) インデックス値から。 2)重量と呼ばれるコメーターから。 その変化がインデックスを特徴付ける指標は、インデックス付きと呼ばれます。 インデックス付き指標には XNUMX 種類あります。 それらのいくつかは、特定の現象の一般的な合計サイズ (ボリューム) を測定し、条件付きでボリューム、広範な (数量、つまり、特定の種類の製品の物理的なボリューム、従業員数、生産のための総人件費、生産の総費用など)P.)。 これらの指標は、直接計算または合計の結果として得られ、最初の主要なものです。 他の指標は、人口のXNUMXつまたは別の単位の観点から現象または機能のレベルを測定し、条件付きで定性的、集約的と呼ばれます:単位時間あたりの生産量(または従業員あたり)、生産単位あたりの労働時間、単位コストこれらの指標は、容積指標を分割することによって得られます。つまり、それらは計算された二次的な性質のものです。 それらは、現象またはプロセスの強度、有効性を測定し、原則として、平均値または相対値のいずれかです。 インデックス法を使用する場合、特定の象徴性、つまり慣例のシステムが適用されます。 索引付けされた各指標は、特定の文字 (通常はラテン語) で示されます。 Q - 物理的な観点から見た、特定の種類の製品の生産量(または販売量)。 T - このタイプの製品の生産にかかる作業時間 (労働力) の総コスト。工数または工数で測定されます。 場合によっては、同じ文字が従業員の平均数を表す場合もあります。 z は生産単位あたりのコストです。 p は生産単位または製品の価格です。 M は、特定の種類および量の製品を生産するための原材料、材料、または燃料の総消費量です。 基本期間のインジケーターには数式内で下付き文字「0」が付き、比較対象 (現在のレポート) 期間のインジケーターには「1」が付きます。 個々のインデックスは文字 i で指定され、インデックス付きインジケーターの指定である添字も付けられます。 はい、1Q 特定の種類の製造された製品 (または販売された商品) の数量 (物理量) の個別の指標を意味します。 私z - 特定の種類の製品の個別単価指数など 複合指数は文字 I で示され、変化を特徴付ける指標の添え字指標も付随します。 たとえば、私はt - 生産単位の労働集約度の複合指数など 個々の指標は通常の相対値、つまり、この用語の広い意味でのみ指標と呼ぶことができます。 狭義の指標、または適切な指標も相対指標ですが、特別な種類のものです。 それらはより複雑な構築方法と計算方法を持っており、それらの具体的な構築方法が指数法の本質です。 社会経済現象とそれらを特徴付ける指標は、釣り合っている、つまり、共通の尺度を持ち、通約不可能である可能性があります。 したがって、異なる企業で生産された、または異なる店舗で販売された同じタイプおよび種類の製品または商品の量は、釣り合いが取れており、合計することができますが、異なるタイプの製品または商品の量は、比較不可能であり、直接合計することはできません。 たとえば、数キログラムのパンに、数リットルの牛乳、数メートルの布、靴を追加することは不可能です。 複合指数の構成と計算における直接和の非通約性と不可能性は、ここでは、自然測定単位の違いではなく、消費者特性の違い、これらの製品または商品の不均等な自然素材の形態によって説明されています。 この点において、複合インデックスを計算するには、それらのコンポーネントを比較可能な形式にする必要があります。 異なるタイプの製品または異なる商品の統一性は、それらが労働の産物であり、特定の価値とその貨幣的表現、つまり価格(p)を持っているという事実にあります。 各製品には、XNUMX つまたは別のコスト (z) と労働集約度 (t) もあります。 これらの定性指標は、一般的な尺度、つまり異なる製品の比較係数として使用できます。 各種類の製品の量 (Q) に、対応する価格、コスト、または生産単位あたりの労働集約度を乗算することで、さまざまな製品を同じ単位に縮小し、合計できる比較可能な指標が得られます。 状況は、質的指標の複合インデックスを構築する場合にも似ています。 たとえば、販売されているさまざまな商品の一般的な価格レベルの変化に関心があるとします。 形式的には異なる財の価格は相応であるが、(各タイプの財の販売量を考慮せずに)それらを直接合計すると、独立した実際的な意味を欠いた価値が得られる. したがって、複合物価指数は単純な合計の比率として構築することはできません。 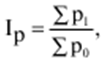 個々の商品の価格は、販売された商品の特定の数と、商品流通の過程におけるそれらの統計的な重みと役割を考慮していません。 個々の商品の価格の単純な合計は、複合インデックスの作成には適していません。これは、価格が商品の測定単位に依存し、その変化によってインデックスの量と値が異なるためです。 したがって、品質指標の概要指標を構築する場合、これらの品質指標が計算される単位ごとに、関連する量指標から切り離して考慮することはできません。 XNUMX つまたは別の定性的指標 (p、z、t) に直接関連する量的指標 (Q) を乗算することによってのみ、XNUMX つまたは別の経済プロセスにおける各タイプの製品 (または製品) の役割と統計的重みを考慮することができます。 - 合計値(pQ)、合計コスト(zQ)、合計作業時間コスト(tQ)などの形成プロセス。同時に、その合計が実際的に重要な指標を取得することができます。 したがって、インデックス方法とインデックス自体の最初の特徴は、インデックス付きインジケーターが単独で考慮されるのではなく、他のインジケーターと組み合わせて考慮されることです。 指数化された指標に関連する別の指標を乗算することにより、さまざまな現象をそれらの統一に還元し、それらの定量的な比較可能性を確保し、実際の経済プロセスにおけるそれらの重みを考慮に入れます。 したがって、インデックス付き指標に関連付けられた乗数指標は通常、指標の重みと呼ばれ、それらによる乗算は重み付けと呼ばれます。 ただし、インデックス付きインジケーターの値に、それらに関連付けられた別のインジケーター (重み) の値を掛けても、インデックス自体の問題はまだ解決されていません。 たとえば、商品の対応する数量の価格を掛けることによって、各期間におけるこれらの商品の価値を見つけることができ、したがって、均衡と重み付けの問題を解決することができます。 ただし、得られた積和を比較すると (∑p1Q1 および∑poQo)は、価格と商品の量(体積)という XNUMX つの要因に応じて貿易売上高の変化を特徴付ける指標を提供しますが、商品の価格レベルと生産レベルの変化を特徴付けるものではありません。 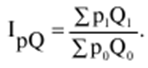 インデックスが一方の要素のみの変化を特徴づけるためには、上記の式のもう一方の要素の変化を排除し、分子と分母の両方で同じ期間のレベルで固定する必要があります。 たとえば、XNUMXつの比較された期間で異種製品の量を見積もるには、両方の期間で販売された商品を同じ、たとえば基本価格(p0)。 結果として得られる指標は、XNUMX つの要素、つまり生産量 Q の物理量のみの変化を反映します。 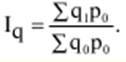 また、商品グループの価格レベルの変化を評価するには、これらの商品の同じ量を比較する必要があります。つまり、商品の数 (Q) は、インデックスの分子と分母の両方で固定する必要があります。同じレベル (ベースまたはレポート レベル) で。 したがって、構築された複合価格指数は、固定により重み (Q) の変化が排除される (排除される) ため、価格の変化のみを特徴付けます。つまり、指数化された指標です。  どちらの場合も(Tq とTp) 指数は、他の要素 (重み) が同じレベルに固定されているため、XNUMX つの要素 (指数化された指標) のみの変化を反映しています。 指数の分子と分母を同じ水準に固定することで重みの変動の影響を排除することが指数および指数法の第二の特徴です。 実際の指標を構築する際に生じる問題を考慮して、タスクは、異種要素 (さまざまな種類の製品など) からなる複雑な現象のレベルを比較して説明することでした。 はい、Tp 全体的な価格水準がどのように変化したかを示す必要があります。つまり、さまざまな商品の価格のダイナミクスを XNUMX つの一般的な指標の形式で測定する必要があります。 歴史的に、指数自体はまさにこの経済問題、つまり一般化の問題、複雑な現象の個々の要素のダイナミクスを XNUMX つの一般化指標に統合する問題、つまり複合指数を解決した結果として登場しました。 ただし、インデックス自体は、別の問題、つまり、これらの因子引数の機能を表す指標の変化に対する個々の因子指標の変化の影響を分析するために使用されます。 したがって、販売された商品の総原価は、価格 (p) と数量 (数量 - Q) の関数になります。 したがって、貿易売上高の変化に対するこれらの各要因の影響を測定するというタスクを設定できます。つまり、各要因の変化によって売上高が個別にどのように変化したかを判断するということです。 このような分析問題を解決するために使用されるインデックスも、重み付けと重み付けの変化の排除というインデックス法の特有の機能を使用して構築されます。 したがって、指数自体は特別な種類の相対的な指標であり、社会経済的現象のレベルが別の(または他の)現象と関連して考慮され、この場合、その変化は排除されます。 指数化された指標に関連付けられた指標は指数の重みとして使用され、重み付けと重みの変更の排除 (同じレベルでの指数の分子と分母の固定) は、指数自体と指数の方法の詳細です。 2。 定性的指標の総合指数 各定性指標は、計算される測定単位 (またはそれが参照する測定単位) に基づいて、XNUMX つまたは別のボリューム指標に関連付けられています。 したがって、商品の単価はその数量 (Q) に関連しています。 価格 (p)、コスト (z)、労働集約度などの品質指標は、生産量に関連付けられています。  生産単位、および原材料、材料の特定の消費 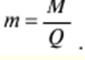 品質指標の要約指標は、任意の商品や製品のセットに関連した一般的な変化を特徴づけるのではなく、非常に特定の量の生産または販売された製品の価格、コスト、労働集約度、または単位原価の変化を特徴付ける必要があります。 これは、重み付け、つまりインデックス付き品質指標のレベルに、関連する体積指標 (重み) の値を乗算し、指標の分子と分母の重みを同じレベルに固定することによって実現されます。 このような積の合計を比較すると、総合指数が得られます。 同様に、生産単位当たりのコストと労働集約度の動態の総合指数、および原材料または資材の比消費量の指数を構築できます。 これらの要約指数を構築する際の主な問題は、指数の重みを固定する必要があるレベル、つまりこの場合は製品 (または商品) の量 - Q を経済的に適切に選択することです。 通常、定性的指標のダイナミクスの複合指標の前に、レベルの相対的な変化だけでなく、この変化の結果として現在の期間に得られる経済効果の絶対値も測定することがタスクになります。 :値下げによる購入者の節約額(または価格が上昇した場合は追加費用の額)、コストの変更による節約額(または追加費用)など。 この問題の定式化は、現在の期間の重みを持つ定性的指標のダイナミクスの指標につながります。 第一に、研究者は、過去ではなく、現在生産されている製品のコストまたは労働集約度の変化に関心があります。 第二に、経済効果は、前の(基準)期間ではなく、現在の報告期間の実際の結果に関連付けられる必要があります。 例として、総コスト インデックスを見てみましょう。 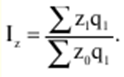 したがって、この指数では、分子は報告期間内の製品の実際のコストの金額を表し、分母は各タイプの単価が同じである場合に報告期間中に製品に費やされた金額を示す条件値です。製品は基本的なレベルに維持されていました。 生産単価を変化させて得られる実質経済効果を絶対値で表したもので、指数の分子と分母の金額の差として算出される   したがって、報告期間(当期)の重みによる重み付けは、定性的指標の指標と、指標化された指標を変更することによって得られる経済効果の指標とを関連付けます。 したがって、定性指標のダイナミクスの集計インデックスは、通常、レポート期間の重みで作成および計算されます。 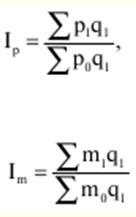 これらの指数では、分子と分母の差が特徴付けられます。最初のケースでは、差の符号に応じて、同じセットの商品を購入するコストの減少または増加が見られます。 XNUMX番目のケースでは、同じ量の製品を生産するための材料の消費量の増加または減少です。 3。 ボリュームインジケーターの集計インデックス 数量指標には、比例するもの (同じタイプの製品または商品の容量) と、比例しないもの (異なるタイプの製品または商品の容量 - Q) があります。 比較可能なボリューム指標は直接合計することができ、集計指標の構築は困難を引き起こしません。 一般的な結果を取得し、異なるボリューム インジケーターの総合インデックスを作成するには、まずこのインジケーターの個々の値を測定する必要があります。 現象の経済的本質に基づいて、共通の尺度を見つけて測定係数として使用する必要があります。 ボリューム指標のこのような一般的な尺度は、関連するものです それらとの品質指標。 したがって、さまざまな種類の製品の量は、これらの製品の単位の価格 (p)、コスト (z)、および労働強度 (t) を使用して測定できます。 指数化されたボリューム指標にXNUMXつまたは別の定性的指標を掛けることにより、合計の可能性を提供するだけでなく、同時に、実際の経済プロセスにおける各要素、たとえば製品の役割も考慮に入れます。つまり、このプロセスにおける統計的な重みです。 さまざまな質的指標が出来高指数のウェイトとして機能する可能性があるため、どれを使用すべきかという問題が生じます。 それぞれの特定のケースにおけるこの問題は、インデックスの前に置かれる認知経済タスクに従って解決されなければなりません。つまり、特定の重み補正子の選択は経済的に正当化されなければなりません。 経済的および統計的作業の実践では、価格は通常、総生産量の指標の重みとして使用されます。 これは、工業製品と農産物の量の指標、および貿易の物理的な量の指標がどのように構築されるかです。 多くの場合、生産量の変化はそれ自体ではなく、より複雑な注文の指標、つまり総生産コスト、その総コスト、作業時間の総コスト、特定の地域での総生産量など。そのような場合、スケールコンパレーターの選択は、より複雑な指標が依存する指標要因の関係によって決まります。 指数が指数化された出来高指標の変化のみを反映するために、その分子と分母の重みは同じ期間のレベルで固定されます。 ボリューム指標のダイナミクスの指標における経済的作業の実践では、通常、重みは基準期間のレベルに固定されます。 これにより、相互接続されたインデックスのシステムを構築できます。 個々の量指標(販売量、生産性量、播種面積)については、基準期間のレベルで重みが選択されます。 例えば:  私はどこにn -複合歩留まり指数; Ip - 商品回転率の複合指数; Iq - 連結コスト指数。 同等の範囲のユニット(同等の製品)で計算される品質インデックスとは異なり、複合ボリュームインデックスは、完全性と正確性のために、各期間の生産または販売されるユニットの全範囲をカバーする必要があります。 この点で、比較された期間のXNUMXつで生産されなかったこれらのタイプの製品に対してどのような重みをとるべきかという疑問が生じます。 このような場合の統計の実践では、XNUMXつの方法が使用されます。 産業生産量の指標を計算する場合、基準期間の価格がない新しいタイプの産業生産は、現在の期間の価格で条件付きで推定されます。 販売された商品の量の指標を計算するとき、新しい商品の価格が類似の商品の比較された範囲の価格と同じ程度に変化したという条件付きの仮定に基づいた方法が使用されます。 4. 一定の重みと可変の重みを持つ一連の集計インデックス 経済現象のダイナミクスを研究する場合、指数が構築され、いくつかの連続した期間について計算されます。 これらは一連の基本インデックスまたはチェーン インデックスを形成します。 多くの基本指数では、各指数の指数化された指標が同期間の水準と比較され、いくつかの連鎖指数では、指数化された指標が前の期間の水準と比較されます。 個々のインデックスでは、分子と分母のウェイトは必然的に同じレベルに固定されます。 一連のインデックスが構築されている場合、その中の重みは、シリーズのすべてのインデックスに対して一定であるか、変数である可能性があります。 生産量の基本的な指標の数: 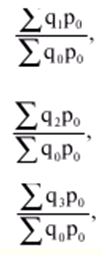 一定の重み(p0) には、いくつかのチェーン インデックスもあります。  いくつかのチェーン価格指数:  一定の重みを持つダイナミクスインデックスの場合、チェーンと基本的な成長率(インデックス)の関係は有効です。  したがって、何年にもわたって一定の重み付けを使用することで、チェーン インデックスからベーシック インデックスへ、またはその逆への移行が可能になります。 したがって、生産量と販売された商品の量の一連の指数は、一定の重みで統計的に作成されます。 たとえば、出来高指数では、基準年の 1 月 XNUMX 日に設定された水準に固定された価格が一定の重みとして使用されます。 数年間使用されるこのような価格は、比較可能 (固定) と呼ばれます。 生産量(商品)の指標に比較可能な価格を使用すると、単純な合計で数年間の結果を得ることができます。 比較可能な価格は、現在の (現在の) 価格と大きく異なるべきではありません。 したがって、それらは定期的に見直され、新しい同等の価格に移行します。 異なる比較可能価格が適用された長期間の生産量指数を計算できるようにするために、XNUMX 年間の生産量は古い固定価格と新しい固定価格の両方で評価されます。 長期の指数は、連鎖法、つまり、この期間の個々のセグメントの指数を掛けることによって計算されます。 現在の期間の重みに従って重み付けするのに経済的に正しい定性的指標の一連のインデックスは、可変の重みで構成されています。 5. 連結地域指数の構築 地域指数を構築するとき、つまり、空間内の指標を比較するとき(地区間、異なる企業間の比較など)、比較ベースと地域(オブジェクト)の選択について、指数の重み付けが必要なレベルで疑問が生じます。固定されます。 それぞれの特定のケースでは、これらの問題は研究の目的に基づいて対処する必要があります。 比較ベースの選択は、特に、比較が双方向(たとえば、隣接するXNUMXつの地域単位の指標の比較)であるか、多国間(複数の地域、オブジェクトの指標の比較)であるかによって異なります。 両側比較では、同じ基準を持つ各テリトリーまたはオブジェクトを、比較および比較ベースの両方として使用できます。 この点に関して、特定の地域(オブジェクト)のレベルで複合指数の重みを固定するという問題が生じます。 たとえば、XNUMXつの分野のどちらで、生産単価が何パーセント低く、生産量が多いかを判断する必要があるとします。 地域 A と地域 B を比較する場合、かなり合理的で簡単な方法は、両方の地域の一般的な生産量を加重してコスト インデックスに固定することです (Q = QA + QE)、次に取得します: 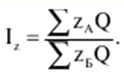 たとえば、多国間の比較では、いくつかの領域で質的指標を比較する場合、重みがそれに応じて固定されるレベルで領域の境界を拡大する必要があります。 出来高指標の統合地域指数では、比較地域全体として計算された対応する質的指標の平均レベルを重みとして使用することができます。 6. 平均指数 個別指数と複合指数の計算方法に応じて、算術平均指数と平均調和指数があります。 言い換えれば、個々のインデックスに基づいて構築された全体的なインデックスは、算術平均または調和インデックスの形式をとります。つまり、算術平均および調和平均に変換できます。 個々の (グループ) インデックスの平均として複合インデックスを構築するという考えは、非常に自然です。なぜなら、複合インデックスは、インデックス付きインジケーターの平均変化を特徴付ける一般的な尺度であり、もちろん、その値はに依存する必要があるからです。個々のインデックスの値。 そして、平均値(平均指数)の形で複合指数を構築することの正確さの基準は、総合指数との同一性です。 集約インデックスの個々の(グループ)インデックスの平均への変換は、次のように実行されます。集約インデックスの分子または分母のいずれかで、インデックス付きインジケーターは、対応する個々のインデックスに関する式に置き換えられます。 。 このような置換が分子で行われる場合、集計インデックスは、分母である場合は算術平均に変換され、次に個々のインデックスの調和平均に変換されます。 たとえば、基準期間における物理量の個別指数と各タイプの生産コストは既知です (q0p0)。 個々の指数の平均を構築するための最初のベースは、物理量の複合指数です。  利用可能なデータから、式の分母のみを合計して直接取得できます。 分子は、基準期間の個々のタイプの製品のコストに個々の指数を掛けることによって取得できます。 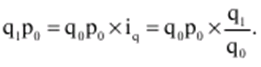 次に、複合インデックスの式は次の形式になります。 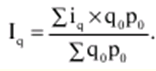 その結果、物理量の算術平均指数が得られます。重みは、基準期間の特定の種類の製品のコストです。 各タイプの製品の生産量のダイナミクスに関する情報があると仮定しましょう (iq) およびレポート期間中の各タイプの製品のコスト (p1q1)。 この場合、企業のアウトプットの全体的な変化を判断するには、Paascheの式を使用すると便利です。 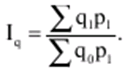 式の分子は、量qを合計することによって取得できます。1p1、および分母 - 各タイプの製品の実際のコストを、物理的な生産量の対応する個別の指標で割ることにより、つまり p を割ります。1q1 / 私q次に: 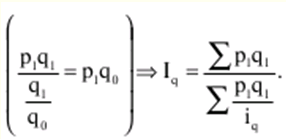 したがって、物理ボリュームの平均加重調波指数の式が得られます。 物理量の指標(総計、算術平均、調和平均)のいずれかの式の使用は、利用可能な情報に依存します。 また、報告期間と基準期間の製品または商品の種類のリスト (それらの範囲) が一致する場合、つまり集計指数がユニットの同等の範囲に基づいて構築されています (質的指標の集計インデックスとボリューム インジケーターの集計インデックス、比較可能な品揃えの対象となります)。 講義№8。 企業の経済活動を決定する指標のシステムの特徴 1.指標のシステムの形成のための原則 企業統計の指標システムの形成の根底にある一般原則は次のとおりです。 1. 統計学の主題 -これは、さまざまなタイプおよび業界の企業の経済活動の分析を可能にする経済指標の収集と処理です。 特定の消費者の注文に関する統計情報の収集は、業界統計の枠組みの中で実行されます。 たとえば、これは中小企業の活動です。 すべての情報は、次の XNUMX つのストリームに分割されます。 1) 業種に関係なく、中小企業のすべての経済活動の主な結果 (フォーム番号 MP - T セクション、最も重要な経済指標)。 2) 特定の産業の小規模企業における商品の生産またはサービスの提供に関する統計的指標 (物理的な生産を含む) は、フォーム No. MP の TT セクションおよびいくつかの産業形態を使用して作成されます。要求された情報量の差別化と詳細化。 また、大・中規模企業統計のベースライン指標の作成作業も進行中です。 企業統計の枠組みで収集された情報の構成を決定する大規模および中規模企業の活動の分析領域は次のとおりです。 1)企業の経済活動の効率、結果と費用の比率(利益と費用の構造、生産の収益性、資産と負債の比率など)。 2)企業の財務および財産の状況(固定および運転資本、資金の出所と方向、負債など)。 3) 企業の投資と事業活動 (投資、生産能力とその使用、在庫の状態、製品の需要、労働力の移動など); 4) 企業の構造的および人口学的特徴。 主な経済指標の構成を決定する作業の段階: 1) 指標の構成、指標形成の方法論、提出のタイミング、報告単位の循環などに関する現在の業界報告の一覧表と分析。 2)ロシアの社会経済発展を分析するための概念スキームの一般的な構造と個々の特別なブロックの構成を考慮に入れた、ミクロレベルの主要な経済指標の形成。 3) 指標のリストと現在の報告で利用可能な統計指標との比較; 4)大中規模企業向けの統計レポートフォームの開発。 5) 統計業界の報告書の様式を改訂するための提案の準備。 業界レポートは、生産に関して有効です。 それは、すべての計算で価値と物理的な用語で製品を会計処理する問題をカバーし、特定の業界の企業の仕事の詳細を反映しています。 統合されたレポート フォームは、統計指標の再現性を排除し、企業の情報負担を軽減するのに役立ちます。 2. 企業構造調査の形態 は、さまざまな種類の製造業者向けの統合報告書の一例です。 メイン へ 構造調査とは、企業の金融および経済活動の主要なパラメータ、個々のマクロ経済指標の形成を包括的に分析するために、生産システムの構造の状態に関する統計データを定期的に提供することです。 2. 製造工程。 彼のモデルの特徴 製造プロセス 原材料と材料を最終製品に変換することを目的とした一連の個別の労働プロセスです。 生産プロセスの構成は、企業とその生産ユニットの構造に一定の影響を与えます。 生産プロセスはあらゆる企業の経済活動の基礎です。 生産の性質を決定するのに役立つ主な要因: 1)労働手段(機械、設備、建物、構造物など); 2)労働の対象(原材料、材料、半製品); 3)労働は人々の活動です。 これらの主な要因の相互作用が、生産プロセスの構成を形成します。 労働資源へ 人材、労働力を指し、人の働く能力として定義されます。 生産過程における労働力は、労働者の目的を持った活動の自然な尺度として、労働時間によって測定される生活労働費の形で消費される。 経済活動に人材を活用する起業家は、労働市場の労働力が価値のある非常に特殊な商品であるという事実に直面します。 費やされた労働量は貨幣価値(賃金)で表されます。 効果的な生産プロセスのために、起業家は、利用可能な労働資源の総量、その質的特性(専門職構成、資格など)、および人件費の形成の詳細について、十分に正確かつ包括的な情報を入手する必要があります。 労働手段の資源 さまざまな固定生産資産のセットです。 労働手段のリソースの情報サブシステムには、それらの利用可能性、タイプ別の構成、技術的条件、および生産および流通コストの形成における役割を反映する指標が含まれている必要があります。 労働手段の特徴は、いくつかの生産サイクルで機能することです。 労働手段は、部分的に、つまり摩耗するにつれて、その価値を製品に移します。 XNUMXつの生産サイクルの生産コストでは、労働手段は、対応する減価償却額によって金銭的に決定される減価償却費の対応する割合に含まれます。 企業の仕事の目的に 原材料、材料、燃料、および半製品、部品、商品の在庫を含むその他の材料資源の在庫。 企業の労働対象のこれらすべてのリソースは、生産プロセスの通常の過程に必要です。 金銭的には、会社の運転資本の大部分を占めており、これには和解金、フリーキャッシュ、その他の種類の金融資産も含まれます。 労働の対象の存在と使用を特徴付けるために、指標のシステムには、それらの自然および材料の組成、入手可能性、生産プロセスにおける収入と支出、それらの消費効率の特徴などに関するデータ、決定する指標を含める必要があります。企業の総費用の形成に対する労働対象の貢献。 生産要素の使用に関連する生産コストは、総コストと生産された製品のコストの両方に転送されます。これは、総コストを超えている必要があります。 起業家の生産プロセスと循環の最終結果は、会社の製品の購入者から現金または非現金の形で受け取った資金(収益)を受け取った時点で明らかになります。 起業家が受け取った現金収入は、いくつかの方向に分配されます。これらは次のとおりです。 1)会社の所有者が決定した金額での生産の再開に関連する費用の払い戻し。これには、労働ツールのリソースを維持および更新し、支払うために、労働対象の在庫の更新に財源の投資が必要です。生きている労働力の現在の消費に関連する費用。 2)会社の収益の一部は、個人的なニーズを満たすために起業家によって使用されます。 3) 収益の一部は、企業の外部環境 (税金の支払い、予算外および特別基金への支払いなど) に使用されます。 3.資源の可能性と企業のすべての活動の結果を決定する指標システムの特徴 労働力の役割は、市場関係の期間だけでなく、常に増加しています。 労働集団 - 起業家活動の成功、起業家の表現と繁栄の鍵となる、起業家の主要なタスクの XNUMX つ。 会社の経営計画を実現し、理解し、実行することができる志を同じくする人々とパートナーのチームは、労働集団と呼ばれます。 労使関係は、企業の複雑な側面です。 生産プロセスは人に依存します。つまり、仕事に対する欲求と能力、そしてそれに応じて資格に依存します。 出現しつつある新しい生産システムは、機械だけで構成されているだけでなく、密接に協力して働く人々も含まれています。 人的資本、設備、在庫は、競争力、経済成長、効率性の基礎です。 企業の効率の向上に影響を与える主な要因: 1) 人員の選択と昇進。 2) 要員の訓練と継続的な教育。 3) 従業員構成の安定性と柔軟性。 4)従業員の仕事の物質的および道徳的評価の改善。 従業員の選抜と昇進には、次の XNUMX つの基準があります。 1) 高い専門的資格と学習能力。 2) コミュニケーションの経験と協力する意欲。 雇用の安定、従業員の離職率の低下、高い賃金は、大きな経済効果をもたらし、従業員の間に仕事の効率を改善したいという欲求を生み出します。 報酬は、労働生産性の向上を刺激し、動機付け効果を持つべきです。 効率と生産性を高めるには、賃金とその形成へのアプローチの両方を変える必要があります。 企業チームの労務および管理の組織には、次のものが含まれます。 1) パートタイムまたは週単位で従業員を雇用する。 2) 確立された生産システムに従った労働者の配置。 3)企業の従業員間の職務の分配。 4) 要員の再訓練または訓練。 5) 分娩の刺激; 6)労働組織の改善。 企業の労働集団は、生産プロセスの既存のシステムに適応します。 生産プロセスの構造は、次のような労働組織の科学的原則に基づいています。 1) 生産工程の分割に基づく分業と連携の向上。 2)専門職および熟練労働者の選択とその配置。 3) 合理的な作業方法と技術の開発と実施による労働プロセスの改善。 4) 各サービス機能の明確な規制に基づいて、職場のサービスを改善する。 5) 効果的なチームワークの導入、マルチユニットサービスの開発、職業の組み合わせ。 6) 埋蔵量の使用に基づく労働配給の改善、人件費の削減、および機器の最も合理的な操作モード。 7) 体系的な生産ブリーフィングの組織と実施 - 労働者の高度な訓練、経験の交換、高度な労働方法の普及。 8)衛生的および衛生的、心理生理学的、美的関係、合理的な作業スケジュールの導入、作業モードおよび作業中の休息の観点から、好ましい作業条件および作業安全の作成。 これらの原則の実施の一般的な指標は次のとおりです。 1) 労働生産性の向上; 2) すべての労働条件の満足; 3) 労働の内容とその魅力に対する満足。 企業での採用の主なソースは、あらゆる種類の教育機関、同様の職業を持つ企業、および労働交換です。 職務分掌と労働者の配置は、分業制に基づいています。 次のような分業が普及しています。 1)技術 - 仕事の種類、職業、専門分野別。 2)運用 - 技術プロセスの特定の種類の操作。 3)実行される作業の機能に応じて-メイン、補助、補助。 4) 資格による。 企業の所有者がすべての要件を満たす従業員を選択した場合、雇用契約または雇用契約を作成する必要があります。これは起業家と雇用される人との間の合意であり、特定の雇用システムが使用されます。国内の練習。 企業のすべての人員はカテゴリに分類されます。 1)労働者; 2)従業員; 3) 専門家; 4) リーダー。 企業の労働者には、物質的価値の創造または輸送および生産サービスの提供に直接関与する労働者が含まれます。 ワーカーは、メインと補助に分けられます。 それらの比率は、企業の分析指標です。 主な労働者の人数比率は、次の式で決定されます。  ここで、Tvr は、企業、作業場、現場 (人) の補助労働者の平均数です。 Tr - 企業、ワークショップ、現場(人)の全労働者の平均数。 スペシャリストとマネージャー(ディレクター、職長、チーフスペシャリストなど)が生産プロセスを組織し、管理します。 従業員には、金融決済、供給およびマーケティング、およびその他の機能 (代理店、レジ係、事務員、秘書、統計担当者など) を実行する従業員が含まれます。 仕事の資格は、特別な知識と実践的なスキルのレベルによって決定され、仕事の複雑さの程度を特徴付けます。 あらゆる職業の能力、身体的および精神的資質の順守は、従業員の職業的適性を意味します。 企業の人員構成 は、総数に対するさまざまなカテゴリの労働者の比率です。 人員の構造を分析するために、企業 T の平均従業員数の合計における従業員 dpi の各カテゴリのシェアが決定され、比較されます。 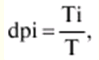 ここでTi - カテゴリの平均従業員数 (人)。 フレームの状態は、係数を使用して決定されます。 離職率 平方キロ(%) は、Tuv. の特定の期間にさまざまな理由で解雇された従業員数の、同じ期間 T の平均従業員数に対する比率です。 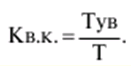 フレーム受け入れ率 (Kp.k)。 (%) は、特定の期間に雇用された従業員数 (Tp で表される) と、同期間の平均従業員数 (T で表される) との比率です。  人事安定係数Кс.к。 個々の部門の企業と全体の両方で、生産管理の組織レベルを評価する際に使用されます。  トゥブはどこですか。 - 報告期間中、労働規律違反により自らの自由意志で辞職した従業員の数(人); T - レポート期間の前の期間における企業の平均従業員数 (人); Tp-レポート期間中に新しく雇用された従業員の数(人)。 スタッフの離職率 (Kt.k.) は、特定の期間 (Tuv.) に退職または解雇された企業の従業員の数を、同じ期間の平均数 T (%) で割ることによって決定されます。 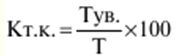 労働力統計は、労働力の構成と規模を調べます。 材料生産の分野では、労働力は企業の主要な活動に従事する人員と非中核的な活動の人員に分けられます。 人事の主なカテゴリーは労働者です。 労働者は、職業、労働の機械化の程度、資格によってグループ化されます。 適格性の主な指標は、料金カテゴリーまたは料金係数です。 資格の平均レベルは、平均料金カテゴリによって決定され、従業員の数または割合で重み付けされたカテゴリの算術平均として計算されます。  どこで P - 関税カテゴリ; T - 特定のカテゴリのワーカーの数 (%)。 すべての従業員は、性別、年齢、職歴、学歴によってグループ分けされています。 労働者数と従業員数の区分には、給与と実際に働いている従業員数があります。 人数には、XNUMX 日以上雇用された企業のすべての従業員が含まれます。 出勤者数には、出勤者のほか、出張中や組織の指示により他企業に雇用されている者も含まれる。 すべての従業員数カテゴリは特定の日付に対して決定されますが、多くの経済計算では、平均従業員数、つまり平均従業員数、平均従業員数、実際に働いている人の平均数を知る必要があります。 平均数は、次の方法で決定されます。 期間の開始時と終了時の給与がわかっていると仮定すると、平均人数はこれらの値の合計の半分として決定されます。 四半期、半年、および XNUMX 年の平均人数は、月平均の算術平均として決定されます。 T\uXNUMXd平均月間従業員数の合計/期間の月数。 毎月の初めまたは終わりなど、定期的な間隔で人数がわかっている場合、四半期、半年、または XNUMX 年の平均人数は、次の平均年代式を使用して求められます。 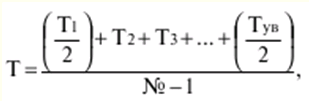 ここで、No.-1 はインジケーターの数です。 T1- 初デートの数字、T2、T3 - その他の日付。 最も正確な結果を得るには、次の XNUMX つの式を使用します。  従業員の平均数は、次の式で決定されます。  実際に働いている人の平均数は、次の式で計算されます。  作業時間は、工数と工数で測定されます。 統計科学では、次の作業時間 (工数) の資金が考慮されます。 カレンダー基金 -これはレポート期間全体の時間であり、期間の暦日数と従業員の給与数の積に等しくなります。 人件費は、休日や週末の工数の分、カレンダー資金より少なくなります。 可能な最大資金は、次の休暇の時間のために人件費よりも少なくなります。 実際、労働時間のさまざまな損失により、費やされた時間基金は可能な最大額よりも少なくなっています。 時間資金の使用は、次の係数によって測定されます。
統計では、シフト勤務時間の使用も分析されます。これには、次の指標が使用されます。  調整済みシフト係数 = 連続係数 x シフト モード使用係数。 労働は、自然物や原材料を完成品に変えます。 この労働能力を生産力といいます。 労働生産性は成功の指標です。 労働生産性 - これは生きた労働の有効性であり、時間をかけて製品を作成するための生産活動の有効性です。 労働生産性統計のタスクは次のとおりです。 1) 労働生産性の計算方法を改善する。 2) 労働生産性の成長要因の特定。 3) アウトプットの変化に対する労働生産性の影響を決定する。 労働生産性は、労働強度と生産量の指標によって特徴付けられます。 単位時間あたりの生産量 (W) は、生産量 (q) と作業時間 (平均人数) のコスト (T) の比率によって測定されます。 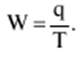 これは労働生産性の直接的な指標です。 反対は労働集約度です。 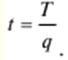 生産量は、単位労働時間あたりに生産される製品の量を示します。 労働生産性の統計的指標のシステムは、製造された製品の量の測定単位によって決定されます。 単位は、自然、条件付き自然、労働、費用のいずれかです。 彼らは、労働生産性のレベルとダイナミクスを測定するために、自然な、条件付きで自然な、労働とコストの方法を使用します。 人件費の測定に応じて、次のレベルの生産性が区別されます。  このレベルは、XNUMX 時間の実際の作業に対する労働者の平均生産量を特徴付けます。 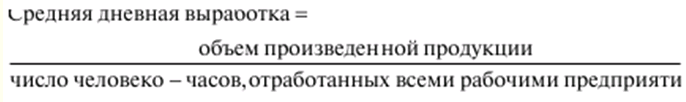 このレベルは、稼働日の生産使用の程度を示します。  分母は労働準備金を反映しています。 四半期平均生産高は、月平均と同様に決定されます。 平均生産高は、市場性のある製品の比率と平均従業員数によって特徴付けられます。 考慮されるすべての指標の間には関係があります。 W1PPP = Wч × Prd × PPN ×dワーキング в PPP ここで W1nn - 従業員あたりのアウトプット; Wч -XNUMX時間あたりの平均出力。 Пrd - 勤務時間; ПPN - 労働時間; dワーキング в PPP - 産業および生産要員の総数に占める労働者の割合。 レベルの測定方法に応じて、労働生産性のダイナミクスは次の統計指標によって分析されます。 1) 自然指数: 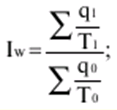 2) 労働指数: 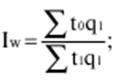 3) 学者 S. G. Strumilin のインデックス: 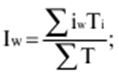 4)値インデックス:  4. 企業の固定資本 二つの要素が揃って初めて生産が行われます。 第一に、これは労働であり、目的を持った人間の活動です。 第二に、生産手段であり、労働手段(機械、器具など)と労働の対象(材料、燃料、原料など)に分けられます。 労働手段の助けを借りて、労働の対象物(工業用建物や構造物など)に直接的な影響を及ぼします(抽出、収集、加工など)、または生産プロセスを保証する条件が作成されます。 労働手段と労働対象の違いは、労働対象が XNUMX つの生産サイクルで消費され、その価値が完全に一度製品に移されるという事実にあります。生産プロセスを経て、その価値を部品単位で製品に移し、生産のたびに繰り返します。 生産過程で機能するすべての労働手段は固定資産を構成します。 したがって、固定資産は、生産プロセスに影響を与える労働手段、労働の対象、または企業での生産プロセスの実施のための条件を提供しますが、長期間機能し、それらの価値を部分的に作成中の製品に移します. 固定資産の構成と構造 資本は生産要素です。 外部的には、資本は特定の形で表されます - これらは生産手段(生産資本)、お金(現金)、商品(商品)です。 生産資本(建物、構築物、機械設備)の一部は固定資本と呼ばれます。 生産資本(原材料、資材、エネルギー資源など)のもう一つの部分は運転資本です。 会計には「固定資産」「固定資産」などの用語があります。 市場関係では、主な場所は、組織の生産能力と固定資産の使用効率を高めるという問題によって占められています。 工業生産における企業の地位、財政状態、および市場での競争力は、これらの問題がいかに効果的に解決されるかにかかっています。 労働ツールの助けを借りて生産プロセスにある企業の従業員は、労働の対象に影響を与え、それらをさまざまなタイプの完成品に変換します。 生産プロセスで機能する固定資産は、生産プロセスとその価値の形成に関与する固定資産の部分を含む生産固定資産と、非生産固定資産に分類されます。それらは物質の生産に直接関係しており、本質的には労働者への奉仕の領域、彼らの日常的および文化的ニーズの満足(住宅の建物、児童およびスポーツ施設、その他の施設)に関係しています。 非生産固定資産の絶え間ない増加は、企業の従業員の幸福の改善と、企業の業績に影響を与える彼らの生活の物質的および文化的レベルの増加に関連しています。 主な生産資産は、社会的生産の材料的および技術的基盤です。 企業の生産能力と労働の技術設備のレベルは、固定生産資産の量に依存します。 労働プロセスは、固定資産の蓄積と労働の技術設備の増加によって豊かになります。 産業で稼働している生産資産は工業生産資産を構成しており、これらの資産は多様性があるため、包括的に研究されます。 工業生産資産の量と構成を研究するために、それらは所有形態別、産業別、自然形態別など、さまざまな基準に従ってグループ化されます。 現在、工業生産資産は、会計制度で確立された分類に従って、その自然の形態に従ってグループ化されています。 分類の本質は、生産プロセスの目的に応じて企業の固定資産を分配し、技術レベルを反映する可能性を生み出すことです。 工業企業の主な生産資産は、次のグループに分けられます。 1) 建物、構造物; 2) 伝送装置。 3)機械および装置-これらは、動力機械、装置、作業機械および装置、測定および調整装置および装置および実験装置、コンピューター技術、その他の機械および装置です。 4) 1 年以上使用でき、1 万ルーブル以上の費用がかかる工具および備品。 各個に。 使用期間が XNUMX 年未満、または費用が XNUMX 万ルーブル未満の工具および機器。 XNUMX 枚あたり、低価値で使い古されたものとして運転資本として扱われます。 5) 生産と家計の在庫。 固定資産全体に占める個々の固定資産の割合 ボリュームは、固定資産の特定の構造を表します。 建物、構造物、在庫は、固定資産のアクティブな要素の機能を保証するため、固定資産のパッシブな部分に属します。 固定生産資産のコストに占める設備の割合が高い場合、他の条件が同じであれば、生産高と資本生産性が高くなります。 固定生産資産の構造を改善することは、生産と資本の生産性を向上させ、コストを削減し、企業の現金貯蓄を増やすための条件です。 固定生産資産の構造に影響を与える要因は、製品の性質、生産量、機械化と自動化のレベル、協力と専門化のレベル、組織の地理的位置、および気候条件です。 製造された製品の性質の影響は、建物のサイズとコスト、車両と伝送デバイスのシェアに反映されます。 生産量が多ければ特殊順送加工機・設備のシェアも高くなる。 このような状況は、ファンドの構造に対する第 XNUMX および第 XNUMX の要因の影響の特徴でもあります。 建物と構造物の割合は、気候条件によって異なります。 固定生産資産の計画と会計は、自然形式と通貨形式で実行されます。 固定資産を現物で評価する場合、機械の数、それらの生産性、能力、生産エリアのサイズ、およびその他のさまざまな数値が確立されます。 このようなデータは、企業や産業の生産能力を計算し、生産プログラムを計画し、設備の生産準備金を増やし、設備のバランスを取るために使用されます。 固定資産の物理的な会計の基礎は、それらのパスポート化、および在庫、その到着と処分の会計です。 固定資産の個々の単位ごとに、生産および技術的特性を含むパスポートが作成されます。これにより、技術的特性、生産目的、およびそれらの状態に従ってグループ化することができます。 固定資産の金銭的評価により、固定資産の拡張再生を計画し、減価償却の程度と減価償却の額、民営化の量を決定できます。 会計実務では、固定資産のいくつかのタイプの評価が使用されます。これは、生産プロセスへの長期的な参加と段階的な損耗、この期間の複製条件の変化に関連しています。 . 固定資産の初期費用は、資金の取得または製造、それらの設置および配送の費用の合計です。 まず第一に、固定資産の評価は元の原価で実行されます。 固定資産の初期費用には、固定資産の取得、輸送、組み立て、設置の費用が含まれます。つまり、これらはすべて、取得と試運転に関連する費用です。 交換費用 - 市況における固定資産の再生産の費用。 再取得価額は、資金の再評価時に設定されます。 残存価値は、固定資産の元のコストまたは交換コストとその減価償却額の差額です。 機能している主要な生産資産は消耗し、その価値が製造された製品に移ります。 償却 製品に譲渡された固定資産の減価償却の金銭的価値です。 減価償却費は製造原価に含まれています。 減価償却控除の年間額は、次の式で決定されます。 A \uXNUMXd (B - L) / T、 ここで、Bは固定資産の初期費用の合計です。 L - 固定資産の清算価値から解体費用を差し引いたもの。 T は固定資産の標準耐用年数です。 Mは、運用期間全体における近代化の推定コストです。 年間減価償却率も、次の式によって決定されます。  固定資産の年間残高は、固定資産の量と移動の変化、それらの再生産、それらに基づいて、再生産のプロセスが分析され、ダイナミクスが研究され、更新の指標、廃棄および状態がまとめられます。固定資産が計算されます。 固定資産の年間減価償却費は、その年の未払減価償却額と同じです。 固定資産の受領元は次のとおりです。 1) 新しい固定資産の試運転; 2) 法人および個人からの固定資産の購入。 3) 他の法人および個人の固定資産の無償受領。 4) 固定資産のリース。 処分は、老朽化や損耗による清算、さまざまな法人や個人への固定資産の売却、無償譲渡、長期リースのための固定資産の譲渡中に発生する可能性があります。 これらの残高に基づいて、固定資産の状態と再生を特徴付ける多くの指標を計算することができます。 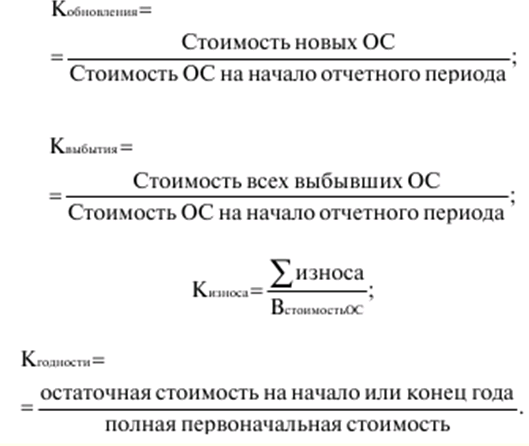 固定資産の使用の指標。 資産利益率:  資本集約度:  資本労働比率:  5. 企業の流動資産 運転資金 - これらはオブジェクトに投資された財源であり、その支出は短い暦期間内に企業によって実行されます。 運転資金に含まれる品目には、その価値に関係なく耐用年数が 50 年を超えない品目、および購入日の単位あたりの最低賃金の XNUMX 倍を超えないという設定された制限を下回る価格の品目が含まれます。 、耐用年数とそのコストに関係なく。 運転資本の構成: 1) 生産在庫; 2) 仕掛品および半製品; 3) 未完成の農業生産。 4) 飼料および飼料; 5)将来の報告期間の費用。 6) 完成品; 7) 商品; 8) その他の在庫品目。 9) 出荷された商品; 10) 現金; 11) 債務者。 12) 短期金融投資; 13) その他の流動資産。 在庫の構成には、原材料と材料、購入した半製品、部品、燃料と潤滑油、燃料、部品などがあります。 運転資本要素の形成の源泉は財源である。 財源の構成には、自己資金(認可資本の資金、利益を犠牲にして形成される特別資金)、誘致資金(商業ローン、預金、発行された手形など)が含まれます。 運転資本は、常に動いていて現金に変わる資産で構成されています。 運転資本の使用を特徴付けるには、その循環速度の XNUMX つの指標があります。 回転率 レポート期間の生産運転資本の平均残高の回転数を特徴付けます。  ここで、P はその期間に販売された商品の原価です。 SO - 運転資本の平均残高。月次平均 (四半期、半年、年) の算術平均または時系列平均として定義されます。 運転資本の固定係数 - この値は、1 ルーブルの運転資金がいくら必要かを示しています。 販売した製品の原価。 運転資本の XNUMX 回の回転の平均日数: 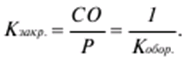 運転資本の XNUMX 回の回転の平均日数:  ここで、D は期間の日数です。 運転資本の循環速度の平均指標が計算されます。 回転率と定着率は、算術加重平均として計算されます。 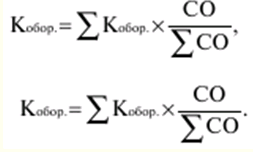 XNUMX 回転の平均持続時間 (日) は、調和加重平均として定義されます。 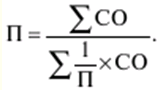 運転資本の回転率の加速の効果は、回転率の加速により条件付きで流通から解放された資金の量によって表されます。 労働の目的の使用の指標は物質的強度であり、これは生産結果の単位あたりの物質的資源の消費を金銭的に特徴付けます。 材料消費の指標は、次の式で計算されます。 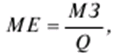 どこで MZ - 固定資産の減価償却なしの材料生産費; Q - 個々の産業や企業の総社会的生産物、国民所得、または生産物の量。 6. 企業金融の統計的研究 エンタープライズ ファイナンス - これらは、商品の生産と販売、仕事の遂行、およびさまざまなサービスの提供の過程で、金銭的資金と貯蓄の形成、分配、および使用で生じる金銭的に表現された関係です。 金融資源の形成、分配、使用、金融および銀行システムと国家に対する経済主体の義務の履行による、金融および金融関係の量的特徴は、それらの質的特徴とともに、金融統計の研究科目。 財務統計の主なタスク: 1)経済主体の財政的および金銭的関係の状態と発展を研究すること。 2) 財源の形成源の量と構造を分析する。 3) 資金の使用方向を決定する。 4) 利益のレベルとダイナミクス、企業の収益性を分析する。 5) 財務の安定性とソルベンシーを評価する。 6) 経済主体による金融および信用義務の履行を評価する。 財源 - これらは、自由に使える経済主体の自己資金および借入資金であり、財務上の義務を履行し、生産コストを負担することを目的としています。 財源の量と構成は、企業の発展のレベルとその効率に関係しています。 企業が成功した場合、その現金収入の大きさは大きいです。 財源の形成は、法定基金の形成時に発生します。 授権資本のソースは次のとおりです。 1) 株式資本; 2) 協同組合のメンバーの貢献を分かち合う。 3) 長期信用; 4) 予算資金。 市場経済の確立された企業では、財源は次のとおりです。 1)販売された製品、実行された作業、または提供されたサービスからの利益。 2) 減価償却控除、株式、有価証券の売却による収入。 3)短期および長期ローン。 4)不動産等の売却による収入。 利益は、貿易および生産活動の最終結果を特徴付けます。 利益は、企業の財政状態の主要な指標です。 ビジネスファイナンスの統計には、次の種類の利益があります。 1) 貸借対照表利益; 2)製品(作品、サービス)の販売からの利益。 3) 総利益; 4)純利益。 バランスシート利益 -これは、経済主体の固定資産およびその他の財産の製品の販売の結果として受け取った利益、および非販売事業からの損失を差し引いた収入です。 製品の販売による利益は、製品の販売による収益と、製造原価に含まれる製造および販売の原価との差額として計算されます。 営業外収益および損失の一部としての総利益には、支払われた罰金および罰則が考慮されます。 企業自体が、純利益の使用の方向性、量、および性質を決定します。 純利益を犠牲にして、生産開発基金、蓄積基金、社会開発基金、および物質的なインセンティブ基金、準備金基金が形成されます。 収益性指標 1. 全体的な収益性: 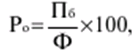 ここで、Pб - 貸借対照表の総利益; F - 固定資産と正規化された運転資本の平均年間費用。 2.販売商品の収益性: 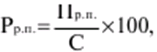 ここで、P r.p. -製品の販売からの利益; C は、販売された商品の総原価です。 企業の事業活動の指標 企業の事業活動は、総資本回転率の指標を使用して決定されます。  ここで、B は製品の販売による収入です。 K - 企業の主要資本。 企業の財政的安定性の分析は、市場経済において非常に重要です。 財政的持続可能性 -これは、経済主体が固定資本および運転資本、無形資産に投資した費用をタイムリーに払い戻し、義務を完済する、つまり支払能力がある能力です。 係数は、安定性測定を評価するために適用されます。 1.自律係数: 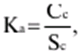 ここで、Cс -自己資金; Sс - すべての財源の合計。 2. 安定係数: 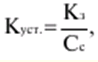 ここでKз - 買掛金およびその他の借入金。 3. 敏捷性: キロ = (Cс +DKZ-Oセント.) / からс, どこで DKZ - 長期のクレジットとローン; Osv。 - 固定資産およびその他の非流動資産。 4. 流動比率: 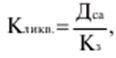 どこで Dsa - 証券、在庫、債権に投資された資金; KZ - 短期債務。 講義№9。 動的解析 1. 社会経済現象のダイナミクスとその統計的研究の課題 社会経済統計によって研究される社会生活の現象は、継続的に変化し、発展しています。 月ごと、年ごとに、人口の規模やその構成、生産量、労働生産性の水準などが変化するため、その変化を調査することは統計の最も重要な仕事の一つです。時間の経過に伴う社会現象 - その発展のプロセス、そのダイナミクス。 統計学では、動的な系列 (時系列) を構築して分析することで、この問題を解決します。 ダイナミクスの範囲 (時系列、動的、時系列) 時間順に並べられた一連の数値指標であり、調査対象の現象の発展レベルを特徴付けます。 シリーズには、時間とインジケーターの特定の値 (シリーズ レベル) の XNUMX つの必須要素が含まれます。 現象の大きさ、大きさを特徴付ける指標の各数値は、シリーズのレベルと呼ばれます。 レベルに加えて、ダイナミクスの各シリーズには、レベルが参照する瞬間または期間の表示が含まれています。 統計観測の結果を集計すると、XNUMX 種類の絶対指標が得られます。 それらのいくつかは、特定の時点での現象の状態を特徴付けます。その時点での人口の単位の存在、またはフィーチャのXNUMXつまたは別のボリュームの存在です。 このような指標には、人口、自動車台数、住宅在庫、在庫などが含まれます。このような指標の値は、特定の時点でのみ直接決定できるため、これらの指標と対応する時系列は瞬間的と呼ばれます。 他の指標は、特定の期間 (間隔) (日、月、四半期、年など) のプロセスの結果を特徴付けます。 このような指標は、たとえば、出生数、生産された製品の数、住宅の試運転、賃金基金などです。これらの指標の値は、一定の間隔 (期間) についてのみ計算できます。 したがって、そのような指標とその一連の値は間隔と呼ばれます。 対応する時系列のレベルのいくつかの機能 (プロパティ) は、間隔と瞬間の絶対インジケーターの異なる性質に由来します。 間隔シリーズでは、一定の間隔 (期間) に対する任意のプロセスの結果であるレベルの値は、この期間の長さ (間隔の長さ) に依存します。 他の条件が同じであれば、間隔シリーズのレベルが大きいほど、このレベルが属する間隔の長さが長くなります。 間隔 (シリーズ内の隣接する日付間の時間間隔) もあるダイナミクスのモーメント シリーズでは、特定のレベルの値は、隣接する日付間の期間の長さに依存しません。 区間系列の各レベルは、より短い期間にわたるレベルの合計をすでに表しています。 この場合、あるレベルの一部である集団の単位は、他のレベルには含まれません。 したがって、一連のダイナミクスのインターバルでは、隣接する期間のレベルを合計して、より長い期間の結果 (レベル) を取得できます (したがって、月次レベルを合計すると四半期レベルが得られ、四半期レベルを合計すると年間レベルが得られます) ; 年間レベルを合計すると、複数年のレベルが得られます)。 場合によっては、隣接する時間間隔の間隔シリーズのレベルを順次追加することにより、一連の累積合計が作成されます。各レベルは、特定の期間だけでなく、特定の日付 (から) から始まる他の期間の合計も表します。年始など)。 このような累積的な結果は、多くの場合、企業の会計およびその他のレポートで提供されます。 瞬間の時系列では、通常、同じ人口単位が複数のレベルに含まれます。 したがって、この場合に得られた結果には独立した経済的重要性がないため、ダイナミクスのモーメント系列のレベルの合計自体は意味がありません。 上記では、初期のプライマリである一連の絶対値のダイナミクスについて述べました。 それらとともに、一連のダイナミクスを構築することができ、そのレベルは相対値と平均値です。 それらはまた、瞬間的または間隔的のいずれかです。 相対値と平均値のダイナミクスの間隔シリーズでは、相対値と平均値は導関数であり、他の値を割って計算されるため、レベルの直接合計自体は無意味です。 一連のダイナミクスを構築して分析する前に、まず一連のレベルが互いに比較可能であるという事実に注意を払う必要があります。この場合のみ、動的なシリーズは現象の発展を正しく反映するからです。 . 一連のダイナミクスのレベルの比較可能性 -これは、このシリーズの分析の結果として得られた結論の妥当性と正確性にとって最も重要な条件です。 時系列を構築する場合、時系列は、比較可能性に違反する変更 (地域の変更、オブジェクトの範囲の変更、計算方法など) が発生する可能性のある長い期間をカバーできることに留意する必要があります。 社会現象のダイナミクスを研究する場合、統計は次のタスクを解決します。 1) 別々の期間のレベルの絶対的および相対的な成長率または減少率を測定します。 2) レベルの一般的な特性と、一定期間のその変化率を示します。 3) 個々の段階での現象の発展における主な傾向を明らかにし、数値的に特徴付けます。 4) 異なる地域または異なる段階でのこの現象の発展を数値で比較して説明する。 5) 研究された現象の時間の変化を引き起こす要因を明らかにする。 6) 将来の現象の発展を予測します。 2. 一連のダイナミクスの主な指標 ダイナミクスを研究するとき、さまざまな指標と分析方法が使用され、初歩的、単純、およびより複雑な数学のより複雑なセクションを使用する必要があります。 多くの問題を解決する際に使用される分析の最も単純な指標 (主に一連のダイナミクスのレベルの変化率を測定する場合) は、絶対成長、成長、成長率、および絶対値 (内容) です。 1%の成長。 これらの指標の計算は、一連のダイナミクスのレベルを相互に比較することに基づいています。 同時に、比較が行われるレベルは、比較のベースであるため、ベースレベルと呼ばれます。 通常、前のレベルまたはシリーズの最初のレベルなどの前のレベルのいずれかが、比較のベースとして使用されます。 各レベルを前のレベルと比較すると、この場合に取得された指標はチェーン指標と呼ばれます。これは、シリーズのレベルを接続するチェーン内のリンクであるためです。 すべてのレベルが同じレベルに関連付けられており、これが一定の比較基準として機能する場合、この場合に取得される指標は基本と呼ばれます。 多くの場合、一連のダイナミクスの構築は、一定の比較基準として使用されるレベルから始まります。 このベースの選択は、研究中の現象の発展の歴史的および社会経済的特徴によって正当化されるべきです. たとえば、開発の前の段階の最終レベル(または前の段階でレベルが増加または減少した場合はその平均レベル)など、いくつかの特徴的な典型的なレベルを基本レベルとして使用すると便利です。 絶対成長 ベースラインと比較して、つまり特定の期間 (期間) にレベルが増加 (または減少) した単位数を示します。 絶対増加は、比較されたレベル間の差に等しく、これらのレベルと同じ単位で測定されます。 Δ=yi −yi-1, Δ=yi −y0, ここでi - i 年目のレベル。 yi-1 - 前年のレベル; y0 - 基準年レベル。 ベースと比較したレベルの低下は、レベルの絶対的な低下を特徴付けます。 単位時間 (月、年) あたりの絶対成長率は、レベルの絶対成長率 (または減少率) を測定します。 チェーンと基本的な絶対成長は相互に関連しています。連続するチェーンの成長の合計は、対応する基本的な成長、つまり期間全体の成長の合計に等しくなります。 成長のより完全な特徴付けは、絶対値が相対値によって補完された場合にのみ得られます。 ダイナミクスの相対的な指標は、成長率と成長プロセスの強度を特徴付ける成長率です。 成長率 (Tр)は、一連のダイナミクスのレベルの変化の強さを反映する統計指標であり、レベルが基準レベルと比較して何倍増加したか、減少した場合は基準レベルのどの部分であるかを示します。比較したレベル。 これは、現在のレベルと以前のレベルまたは基本レベルの比率によって測定されます。  他の相対値と同様に、成長率は係数 (レベルの単純な比率) の形式だけでなく、パーセンテージでも表すことができます。 絶対成長率と同様に、任意の時系列の成長率は、それ自体が間隔指標です。つまり、時間の XNUMX つまたは別の期間 (間隔) を特徴付けます。 チェーン成長率とベース成長率の間には一定の関係があり、係数の形で表されます。連続するチェーン成長率の積は、対応する期間全体のベース成長率に等しくなります。 例えば: 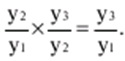 成長率 (Tпр) 増加の相対値を特徴付けます。つまり、以前のレベルまたはベース レベルに対する絶対増加の比率です。  パーセンテージで表される成長率は、ベースラインを 100% として、レベルが何パーセント増加 (または減少) したかを示します。 開発率を分析するとき、成長率と成長率の背後に隠されている絶対値(レベルと絶対増分)を見失うことは決してありません。 特に、成長率と成長率の低下(減速)に伴い、絶対成長率が上昇する可能性があることに留意する必要があります。 この点で、ダイナミクスの別の指標を研究することが重要です-絶対成長を対応する成長率で割った結果として決定される成長の1%(XNUMX%)の絶対値(内容): 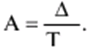 この値は、増加の各パーセンテージがどれだけ与えるかを絶対値で示します。 ある年の現象のレベルは、地域、部門、およびその他の変更(会計および指標の計算方法の変更など)により、他の年のレベルと比較できない場合があります。 比較可能性を確保し、分析に適した時系列を得るには、他と比較できないレベルを直接再計算する必要があります。 ただし、これに必要なデータが利用できない場合があります。 このような場合、一連のダイナミクスの閉鎖と呼ばれる特別な手法を使用できます。 たとえば、ある現象の発展のダイナミクスがi年目に研究された領域の境界に変化があったとしましょう。 その場合、今年以前に取得されたデータは、その後の年のデータと比較できなくなります。 これらのシリーズをクローズし、全期間のシリーズのダイナミクスを分析できるようにするために、それぞれのデータを i 年目のレベルの比較ベースとして採用します。領土の古い境界と新しい境界内。 同じ比較基準を持つこれら XNUMX つの行は、XNUMX つの閉じたダイナミクス行に置き換えることができます。 このようなクローズド シリーズのデータから、任意の年と比較した成長率を計算できます。 新しい境界で期間全体の絶対レベルを計算することもできます。 もちろん、一連のダイナミクスを閉じて得られた結果には多少の誤差が含まれていることに留意する必要があります。 現象のダイナミクスは、ほとんどの場合、棒グラフと線図の形でグラフで表されます。 波グラフ、方形グラフ、円グラフなど、他の形式のグラフも使用されます。分析グラフは通常、折れ線グラフの形式で作成されます。 3. 平均ダイナミクス 時間の経過とともに、現象のレベルが変化するだけでなく、そのダイナミクスの指標、つまり絶対的な増加や発展の速度も変化します。 したがって、開発の一般化された特性について、典型的な主な傾向とパターンを特定して測定し、分析の他の問題を解決するには、時系列の平均指標、つまり平均レベル、平均絶対増加率、およびダイナミクスの平均率が使用されます。 平均値と相対値を計算する際の分子と分母の比較可能性を確保するために、時系列を構築するときにすでに力学系列の平均レベルを計算する必要があることがよくあります。 たとえば、ロシア連邦の XNUMX 人当たりの電力生産量の一連のダイナミクスを構築する必要があるとします。 これを行うには、毎年、その年に生産された電力量 (間隔指標) を同じ年の人口 (即時指標。値は年間を通じて継続的に変化します) で割る必要があります。 一般に、特定の時期の人口規模が、年間全体の生産量と比較できないことは明らかです。 比較可能性を確保するには、何らかの方法で人口規模を年間全体と一致させる必要があります。これは、年間の平均人口規模を計算することによってのみ行うことができます。 また、多くの現象のレベルが期間ごと、たとえば年ごとに大きく変動し、増加または減少するため、ダイナミクスの平均指標に頼る必要があることがよくあります。 これは、年々低下しない農業の多くの指標に特に当てはまります。 したがって、農業の発展を分析するとき、彼らはしばしば年次指標ではなく、数年間のより典型的で安定した平均年次指標で動作します。 ダイナミクスの平均指標を計算するときは、平均理論の一般規定がこれらの平均に完全に適用されることに留意する必要があります。 これは、まず第一に、動的平均が現象の発展にとって均質で多かれ少なかれ安定した条件を備えた期間を特徴づける場合には、動的平均が典型的であることを意味します。 そのような期間、つまり発達段階の特定は、ある点ではグループ化に似ています。 動的平均が、現象の進行条件が大きく変化した期間、つまり、現象の進行のさまざまな段階をカバーする期間に対して計算される場合、そのような平均は、それを補足して、細心の注意を払って使用する必要があります。個々のステージの平均を示します。 ダイナミクスの平均指標は、論理的および数学的要件も満たす必要があります。これにより、平均が計算される実際の値を置き換えるときに、定義指標の値、つまり、平均化された指標に関連付けられた一般化指標、変更しないでください。 一連のダイナミクスの平均レベルを計算する方法は、主に一連の指標の性質、つまり時系列のタイプに依存します。 計算する最も簡単な方法は、レベルが等しい絶対値のダイナミクスの間隔シリーズの平均レベルです。 計算は、単純な算術平均の式に従って行われます。 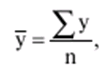 ここで、n は連続する等しい時間間隔の実際のレベルの数です。 絶対値のダイナミクスのモーメント系列の平均レベルを計算すると、状況はより複雑になります。 モーメント インジケータは、ほぼ連続的に変化する可能性があります。 したがって、その変化に関するより詳細で包括的なデータがあればあるほど、平均レベルをより正確に計算できることは明らかです。 さらに、計算方法自体は、利用可能なデータの詳細度によって異なります。 ここではさまざまなケースが考えられます。 モーメント指標の変化に関する包括的なデータがある場合、その平均レベルは、さまざまなレベルの間隔シリーズの算術加重平均の式によって計算されます。  ここで、t はレベルが変化しなかった期間の数です。 隣接する日付間の時間間隔が互いに等しい場合、つまり、日付間の等しい (またはほぼ等しい) 間隔を扱っている場合 (たとえば、各月または四半期、年の初めにレベルがわかっている場合)、レベルが等しい即時シリーズの場合、時系列平均式を使用してシリーズの平均レベルを計算します。 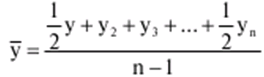 レベルが異なるインスタント シリーズの場合、シリーズの平均レベルは次の式を使用して計算されます。 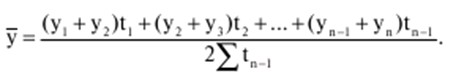 上記では、一連の絶対値のダイナミクスの平均レベルについて話しました。 平均値と相対値の一連のダイナミクスについては、これらの平均値と相対値の指標の内容と意味に基づいて平均レベルを計算する必要があります。 平均絶対成長率 単位時間 (月平均、年平均など) ごとに、前のレベルと比較してレベルが増加または減少した単位数を示します。 平均絶対増加は、レベルの平均絶対増加率 (または減少) を特徴付け、常に間隔指標です。 これは、期間全体の総成長を、さまざまな時間単位でのこの期間の長さで割ることによって計算されます。 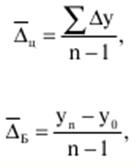 どこで Δ - 連続する期間のチェーン絶対増分; n はチェーンの増分数です。 у0 - ベース期間のレベル。 平均成長率 (および平均絶対増加率) の計算の正確さの基礎と基準として、検討中の全期間の成長率に等しい連鎖成長率の積を使用できます。決定指標。 したがって、n 連鎖成長率を掛けると、全期間の成長率が得られます。  平等を尊重する必要があります。  この等式は、単純な幾何平均の式を表します。 この等式から、次のことがわかります。 
ここで、n はダイナミクス シリーズのレベル数です。 Т1、T2、Tп - チェーンの成長率。 係数の形で表される平均成長率は、単位時間あたりの平均で(年間、月間などの平均で)レベルが以前のレベルと比較して何倍増加したかを示します。 平均成長率と成長率については、通常の成長率と成長率の間には同じ関係が成り立ちます。  パーセンテージで表される平均増加率 (または減少率) は、単位時間 (年平均、月平均など) あたりの平均で、前のレベルと比較してレベルが何パーセント増加 (または減少) したかを示します。 平均成長率は、成長の平均強度、つまりレベル変化の平均相対速度を特徴付けます。 XNUMX 種類の平均成長率式のうち、XNUMX 番目の式がより一般的に使用されます。これは、すべての連鎖成長率を計算する必要がないためです。 最初の式によると、一連のダイナミクスのレベルも期間全体の成長率も知られていない場合にのみ計算することをお勧めしますが、チェーンの成長率 (または成長) のみが知られています。 4.主な開発動向の特定と特性化 時系列の分析で発生するタスクの XNUMX つは、時間の経過に伴う調査中の指標のレベルの変化パターンを確立することです。 これを行うには、この現象と他の現象との関係、およびその開発の条件に関して十分に均一な開発の期間(段階)を選択する必要があります。 発達段階の特定は、この現象を研究する科学 (経済学、社会学など) と統計学の交差点にある課題です。 この問題の解決は、統計的方法の助けを借りて実行されるだけでなく(それらはある程度の利益をもたらす可能性があります)、現象の本質、性質、および一般的な意味のある分析に基づいて実行されます。その開発の法則。 発展の各段階で、現象のレベルの変化の主な傾向を特定し、数値的に特徴付ける必要があります。 トレンドとは、時間の経過に伴う現象のレベルの増加、減少、または安定化に向かう一般的な方向です。 レベルが継続的に増加または継続的に減少している場合、上昇傾向または下降傾向は明確であり、時系列グラフから視覚的に簡単に検出できます。 ただし、レベルの増加と低下はどちらも、均等に発生する場合もあれば、加速する場合もあれば、減速する場合もあるなど、さまざまな方法で発生する可能性があることに留意する必要があります。 ここでの均一な成長 (または減少) とは、連鎖絶対増加 (4) が同じである場合に、一定の絶対速度で成長 (減少) することを意味します。 成長または衰退が加速すると、チェーンの増分は絶対値で体系的に増加し、ゆっくりとした成長または衰退では、チェーンの増分は減少します (これも絶対値で)。 実際には、一連のダイナミクスのレベルが厳密に均等に増加 (または減少) することはほとんどありません。 また、チェーンの増分が XNUMX つの偏差もなく系統的に増加または減少することもまれです。 このような逸脱は、現象のレベルが依存する主な原因と要因の複合体全体の時間の経過の変化、または二次作用の方向と強さの変化(ランダムを含む)のいずれかによって説明されます。状況と要因。 したがって、ダイナミクスを分析するときは、開発トレンドだけでなく、開発のこの段階を通じて非常に安定している (持続可能である) 主なトレンドについても話しています。 場合によっては、この規則性、オブジェクトの開発における一般的な傾向は、ダイナミック シリーズのレベルによって非常に明確に示されます。 主な傾向(傾向) これは、時間の経過に伴う現象のレベルの非常に滑らかで安定した変化と呼ばれ、多かれ少なかれランダムな変動がありません。 主な傾向は、傾向モデル方程式の形で分析的に、またはグラフで表すことができます。 統計学において、発展の大きな傾向(トレンド)を特定することを時系列アライメントとも言い、主な傾向を特定する方法をアライメント手法と呼びます。 一連のダイナミクスの主な傾向 (トレンド) を特定する最も一般的な方法の XNUMX つは、次のとおりです。 1) 間隔の拡大方法; 2) 移動平均法 (この方法の本質は、絶対データを特定の期間の算術平均に置き換えることです)。 平均値の計算は、スライド方式、つまり、最初のレベルの受け入れ期間からの段階的な除外と次のレベルの包含によって実行されます。 3) 解析的位置合わせ法。 この場合、ダイナミクス シリーズのレベルは時間の関数として表されます。 a) f(t)= a0+ ajt- 線形依存; b) f(t) = a0 + cijt + a2t2-放物線依存。 平均レベルごとに間隔とその特性を拡大する方法は、短い間隔から長い間隔に移行することです。たとえば、数日から数週間または数十年、数十年から数か月、数か月から四半期または年、年単位から数年間隔に移行します。 。 一連のダイナミクスのレベルが多かれ少なかれ一定の周期性 (波状) で変動する場合、拡大された間隔を変動の周期 (サイクルの「波」の長さ) と等しくすることをお勧めします。 このような周期性が存在しない場合、傾向の一般的な方向が十分に明確になるまで、拡大は小さな間隔から徐々に大きな間隔に実行されます。 ダイナミクス シリーズが瞬間的であり、シリーズのレベルが相対値または平均値である場合、レベルの合計は意味がなく、集約された期間は平均レベルによって特徴付けられる必要があります。 間隔が拡大されると、動的系列のメンバーの数が大幅に減少し、その結果、拡大された間隔内のレベルの動きが見えなくなります。 この点で、主な傾向とそのより詳細な特性を識別するために、系列は移動平均を使用して平滑化されます。 移動平均を使用した一連のダイナミクスの平滑化は、一連の最初の順序レベルの特定の数から平均レベルを計算し、次に同じ数のレベルから、XNUMX 番目から始めて、次に XNUMX 番目から始めて平均レベルを計算することで構成されます。このようにして、平均レベルを計算するときは、最初から最後まで時系列に沿ってスライドし、そのたびに最初の XNUMX つのレベルを破棄し、次のレベルを追加するように見えます。 したがって、移動平均という名前が付けられました。 移動平均の各リンクは、対応する期間の平均レベルです。 グラフ表示といくつかの計算を使用して、各リンクは通常、計算が行われた期間の中央間隔 (インスタント シリーズの場合は中央日付) を参照します。 移動平均リンクを計算する必要がある期間の問題は、ダイナミクスの特定の機能によって異なります。 間隔の拡大と同様に、レベル変動に一定の周期性がある場合は、平滑化期間を振動周期またはその値の倍数に等しくすることをお勧めします。 そのため、毎年季節的に増減する四半期レベルがある場合は、XNUMX 四半期または XNUMX 四半期の平均などを使用することをお勧めします。明確なトレンドパターンが現れます。 時系列の分析的な調整により、傾向の分析モデルを取得できます。 以下の流れで製作します。 1. 有意義な分析に基づいて、開発段階が特定され、この段階でのダイナミクスの性質が確立されます。 2. XNUMXつまたは別の成長パターンとダイナミクスの性質の仮定に基づいて、傾向の分析表現の形式、特定の線(直線、放物線、指数関数)にグラフィック的に対応する近似関数の種類この線(関数)は、時間の経過とともに滑らかにレベルが変化する予想されるパターン、つまりメイントレンドを表します。 この場合、力学系列の各レベルは、従来、次の XNUMX つのコンポーネント (コンポーネント) の合計として考慮されます。t = f(t) + ε。 それらのXNUMXつ(yt = f(t)) は傾向を表すもので、恒久的な主要因の影響を特徴付け、系統的規則成分と呼ばれます。 別のコンポーネント (е!) ランダムな要因や状況の影響を反映しており、ランダム成分と呼ばれます。 このコンポーネントは、トレンドからの実際のレベルの偏差に等しいため、残差 (または単に残差) とも呼ばれます。 したがって、主要なトレンド(トレンド)は、常に作用する主要な要因の影響下で形成され、二次的なランダムな要因によってレベルがトレンドから逸脱すると想定(条件付きで想定)されます。 曲線の形状の選択によって、トレンド外挿の結果が大きく決まります。 曲線の種類を選択するための基礎は、特定の現象の発展の本質を意味のある分析にすることができます。 この分野に関する以前の研究結果も信頼できます。 最も単純な経験的方法は視覚的な方法です。つまり、系列のグラフ表示 (破線) に基づいてトレンドの形状を選択します。 実際には、その単純さのため、線形依存性は放物線依存性よりも頻繁に使用されます。 著者: コニック N.V.
タッチエミュレーション用人工皮革
15.04.2024 Petgugu グローバル猫砂
15.04.2024 思いやりのある男性の魅力
14.04.2024
▪ 記事 雲はどうやって空に留まることができるのでしょうか? 詳細な回答 ▪ 記事 小型トンネルダイオード無線送信機。 無線エレクトロニクスと電気工学の百科事典
ホームページ | 図書館 | 物品 | サイトマップ | サイトレビュー
www.diagram.com.ua |


 - サンプルに含まれていない一般集団の単位の割合。
- サンプルに含まれていない一般集団の単位の割合。


 他の記事も見る セクション
他の記事も見る セクション 